
【Suphx論文解説⑦】Oracle Guiding

今回は次回に引き続き、Suphxの心臓部である「3つの機能」の解説です。
・Global Reward Prediction
・Oracle Guiding(👈今回はココ!)
・run-time policy adaption
前半部分は麻雀プレイヤー向けの直感的な説明、後半はガチ勢向けの技術的な説明です。
まずは直感的な説明から
麻雀は不完全情報ゲームです。相手の手牌や山などは誰にもわかりません。ところが、熟練の麻雀プレイヤーの中には「相手のシャンテン数」や「山読み」など不確定な情報を推測する技術を持っている打ち手も存在します。
人工知能がこのような技術を身につけるためには一体どうすればいいのでしょうか?
これに対する答えがOracle Guidingです。
突然ですが、みなさん「ヒカルの碁」という漫画はご存知でしょうか?少し昔のジャンプ漫画なので若い人は知らないかもしれません。(知っている方はアラサーくらいかと思います。)
ヒカルの碁では「藤原佐為」という平安時代の最強棋士の亡霊が登場します。佐為は序盤は主人公のヒカルに憑依して「神の一手」を極めようと囲碁を打つのですが、次第にヒカル自身が強くなってしまいます。最終的に佐為はヒカルの意思を尊重し、囲碁を打つのをやめて成仏します。
Oracle Guidingはまさにこんなイメージです。

Oracle Guidingという単語を日本語に直すと…
Oracle(神のお告げ)Guiding(導く)
となります。一言で言えば「神の導き」です。
Oracle Gudingを導入することで人工知能でも長年の経験に基づく読みを学習することが可能になります。以前、Suphxが相手のテンパイを察知して、ツモ切リーチに踏み切ったシーンを記事にしました。これはまさにOracle Guidingの恩恵を受けていると言っていいでしょう。
Oracle Agentの見る景色
Oracle GuidingではOracle Agentと呼ばれるエージェントを学習させます。
※通常の強化学習のエージェント(Normal Agent)に対して、全ての情報を見ることができる神視点のエージェントをOracle Agentと呼びます。
Oracle Agentが観測できる情報は以下の通りです。
①自分の手牌
②全プレイヤーの捨て牌
③持ち点、供託など
④他家の手牌
⑤ツモ山
通常のエージェントでも①〜③までの情報は観測できるので、大きな違いは④と⑤です。Oracle Agentは通常はオープンされていない情報を使ってチート的に強化学習を行います。
他家の手牌やツモ山がわかるということは…相手のシャンテン数、打点、待ちの残り枚数や、隠れワンチャンスなどを推測することが出来そうですね。Suphxが時折見せる「牌効率を無視した先切り」や「突然のベタオリ」などはこのOracle Guidingによるものだと考えられます。
要するにOracle Guidingとは
Suphxに不確定情報を推測する能力を与える学習方法
なのです。
🤖「そろそろ上家がテンパりそうです。抑え込みリーチをかけましょう。」
🤖「あなたの待ちは山ゼロの可能性大です。ターツを振り替えましょう。」
🤖「他家の手は安いはずです。ここはゼンツです。」
Suphxにはこんな判断をしているはずです。まさに熟練の打ち手の思考そのものですね。
ゆるふわな説明はここまで。
ここから先はもう少し技術的に踏み込んでいきます。
完全情報から不完全情報へ
さて、Oracle Agentがチート的に学習することは説明しました。
💁♂️「うーん…。Oracle Agentが神視点なのはわかったけど、実際に打つときには全部見えるわけじゃないよね?一体どうするんですか?」
当然そう思いますよね。
いくらAIとは言えSuphxも他のプレイヤーと同様に、不完全な情報だけで行動を選択する必要があります。Oracle Guidingでも最終的にはそうするのですが、まずは数式を見てみましょう。

難しいですね。
この数式は強化学習に用いるある関数を表しているのですが、これを基準にして方策(=5つの戦術モデル)のパラメータの調整を行なっていきます。ここにOracle Guidingの秘訣があります。この式を理解することを目標にしましょう。
ポイントは以下の二点です。
■方策勾配法
■ドロップアウトマトリックス
一つずつ説明していきたいと思います。
方策勾配法による強化学習
まずは方策勾配法の説明です。
Suphxでは最初に教師あり学習によって5つの戦術モデルを学習させて、次にそのモデル(=方策)のパラメータを強化学習によって改善していきます。
方策勾配法というのは方策のパラメータ改善のための手法です。方策勾配法の詳細な説明は省きますが、歴史的な経緯は頭に入れておきましょう。下のツイートによくまとめられています。Suphxに関連するのは中央下部の赤背景の部分です。
東京大学松尾研 深層強化学習サマースクール,講義は昨日無事に終了しました.受講生の皆様お疲れ様でした!
— えるエル (@ImAI_Eruel) September 9, 2020
講義資料を作りながら,いい機会だと思ったので,強化学習のアルゴリズムをまとめた図を作ってみました
強化学習,深層強化学習について大体の流れ,手法を追いたい人は是非ご利用ください! pic.twitter.com/loCRgxWQGE
方策勾配法 → 方策勾配定理→ 自然方策勾配 → TRPO → PPO →ゲームAIへ…という流れが追えると思います。
Suphxの論文の3.1章では以下のような数式が掲げられています。
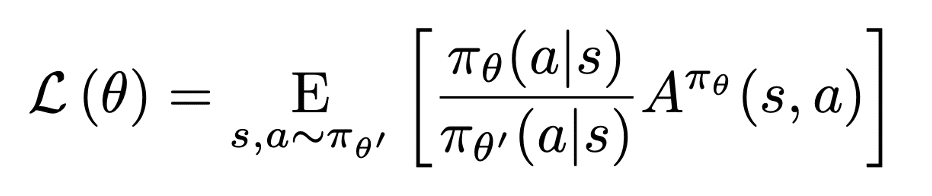
これは2015年に発表されたTRPO(Trust region policy optimization)というアルゴリズムで登場する数式です。πは方策(5つの戦術モデル)の出力する確率値を表しています。aとsは行動(Action)と状態(State)です。π_θ(a|s)というのは「ある状態sで行動aを取ったときの方策πが出力する確率値」という意味です。
前半部分では「新しい方策の確率値(π_θ)」を「古い方策の確率値(π_θ')」で割ることでパラメータ更新量の比率を計算しています。AというのはAdvantageと呼ばれる関数です。エージェントが選んだ行動の価値を評価します。パラメータ更新の比率を行動価値に掛け合わせて、その平均を求めています。
※E[〇〇]というのは平均値(or期待値)を表します。
この式は結局のところ、「5つの戦術モデルの行動選択がどれだけ改善したか」の期待値を表しています。したがって、このL(θ)が最大になるように方策パラメータθを決めれば、最も効果的にパラメータを改善できるということになります。
ここら辺までくると僕も完全に理解し切れていないので、間違っていたらごめんなさい。
参考にしたリンクをいくつか貼っておきます。
ドロップアウトマトリックスの導入
先ほど紹介した数式はNormal Agent(通常の強化学習エージェント)が学習する際の話です。ここでの状態sは相手の手牌やツモ山が見えない場合のものです。
Oracle Agentを導入すると全ての情報がオープンになるため、状態sはより多くの情報量を持つことになります。
最初に出した数式をもう一度見てみましょう。
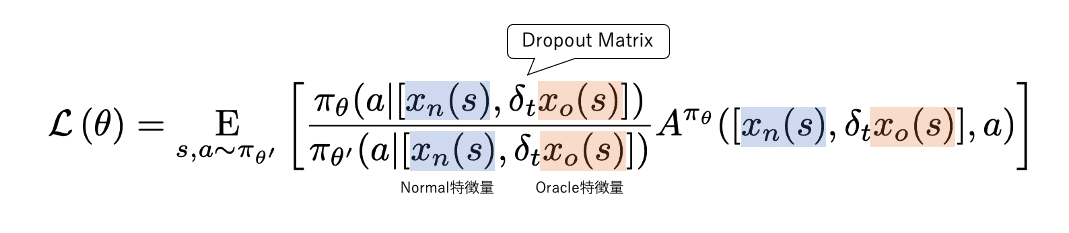
前述のTRPOの数式と違って、状態sの部分がごちゃごちゃしてます。
xというのは以前紹介したマトリクスに変換された盤面(特徴量)を表します。青色はNormal Agentから見える特徴量で、オレンジはOracle Agentから見える特徴量です。
δtはドロップアウトマトリクス(Dropout Matrisx)です。Suphxも最終的にはNormal特徴量だけで行動を決めなければならないので、Oracle特徴量を削ぎ落としていかなければなりません。最終的には0になって無くなるようなイメージです。
ドロップアウトマトリクスは[0,1]の要素で成り立つ行列です。これをOracle特徴量のマトリクスに掛けると要素が1の部分はそのまま残り、0の部分は情報が欠落します。こうしてOracle特徴量の絞り込みを行います。
ドロップアウトマトリクスの要素はベルヌーイ変数に従います。ベルヌーイ変数というのは確率 p で 1 、確率 q = 1 − p で 0となるような変数です。pを徐々に0に近づけていけば、全ての要素が0になります。
この数式は結局何を表しているのか?
ここまで説明してきた数式を比較してみます。

通常の強化学習のパラメータ更新と違って、Oracle GuidingではNormal/Oracleの二つの特徴量を配合しながらパラメータを更新していきます。
このようにOracle GuidingではOracle AgentとNormal Agentの判断が近づくように学習しているというわけです。
最初は神視点で最適解を選び、段々とその打ち筋をSuphx自身が習得して、最終的にはOracle Agentはゼロになって消える。まさにヒカルの碁と一緒ですね。
さらに学習を安定させるための2つの工夫
学習を安定させるために以下の2つのトリックを導入したそうです。
1. 学習率を0.1に設定する
2. 重み(importance weight)が一定の閾値以上変化するデータだけ採用
論文を見てもこれ以上詳しく書いてないので、これ以上は何とも言えません。ですが、これだけの工夫が必要ということは裏を返せば、Suphxの学習はかなり不安定であるということがわかります。
こういったパラメータ調整には「職人芸に近い技術」が要求されることが多いです。今後、さらに強い麻雀AIを作るのはかなり難しいのではないかと思います。
人類にもOracle Guidingを
我々人間も自分の牌譜を見直したり、他人の対局を見たりして、同じような学習が可能です。実際にトッププロの勉強会でも、牌譜を再現しながら検討していると思います。Suphxはこの学習法を高速かつ大量に行うことが出来るのです。これは機械にしかできない学習メソッドです。人間を超越したポイントはここでしょう。
また、ドロップアウトマトリクスは「我々人間も牌譜検討や対局をただ見るだけではダメだ」ということも示唆しています。全てが見える状況ではなくて、ところどころブラインドした状態で検討するのも良いのではないでしょうか。
ん… ?ところどころブラインド…?これどこかで見たことがあるような気がするぞ。
(ワシズ牌ってもしかしたら麻雀の読みの練習にピッタリなのでは…?)
Oracle Guidingの解説はここまで。次回はrun-time policy adaptionです。
この記事が気に入ったらサポートをしてみませんか?