
ファッションモデル生成の最先端: Generating High-Resolution Fashion Model Images Wearing Custom Outfits [Yildirim+ ICCVW19]

はじめに
ファッション人物生成で結果のよい論文が出ていたので内容についてまとめます。2019/08/23に公開され、先日ICCVのWorkshopに採録されたものです。
Generating High-Resolution Fashion Model Images Wearing Custom Outfits
以下、結果の一例ですが、かなり綺麗に生成できています。

著者はZalando Researchの方々で、ZalandoはファッションECサイトを運営する会社です。そのため、データは内部の38万枚の画像を学習データとしたようです。生成に使用したモデルは Style GAN [Karras+ CVPR19] で、(1) 単純にこのモデルを適用させたノイズからランダムにファッションモデルの画像を生成するもの、と (2) 姿勢とアイテムを指定して生成するもの、の2つのパターンを実験しています。上記の例のは(1)の結果を示しています。
この論文の面白さは、大量の高品質なファッション画像を最新の画像生成モデルに適用させたらとても品質の高い画像が生成できた ということと任意の姿勢及び服を指定して高品質な画像を生成できたという2点があると思います。
提案モデルとその結果
上述の通り、モデルは2パターンあります。まず、ランダムノイズからファッションモデルの画像を生成するパターンです。このモデルは、Style GAN [Karras+ CVPR19] を使っており、Progressive GAN [Karras+ ICLR17] にStyle Transfer系の技術であるAdaIN [Huang+ ICCV17] の要素が組み合わさった形になっています。生成画像のサイズは1024x768で高解像度です。

前章のサンプルはこのモデルの結果にあたります。また生成するときのlayerを操作することで色や姿勢を特定のものにすることができるということも示されています。以下のように色や姿勢を維持できていることが分かります。

モデルの2つ目のパターンは服と姿勢を指定して生成を行うパターンです。以下の画像のようにアイテムを最大6つ(服の順番はアイテムの種類ごとに固定、ないアイテムはグレイを置く。)と特定の姿勢をenbeddingしたものを加えます。これによって、任意の服と姿勢に対応した画像を生成できるようになりました。
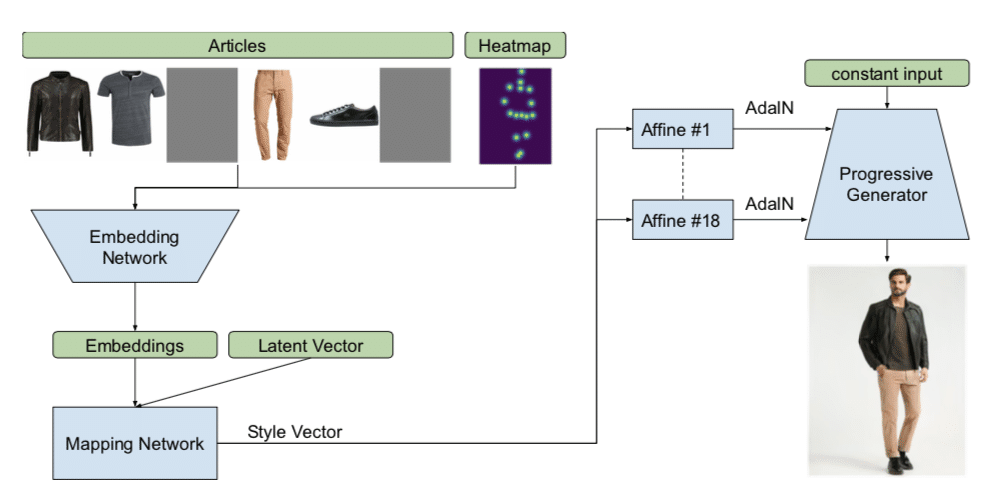
結果は以下の通りです。以下の画像のアイテムを入力で指定した結果を示します。

結果は以下の通りでかなり綺麗に、しかもちゃんと指定したアイテムを着用しています。

画像の品質については以下のように、FID(0に近いほうが結果がいい)で出しており、前者(unconditional)のほうが後者(conditional)のアイテムを指定するよりよいという結果になっており、品質だけ見れば前者が良いということで、アイテムを指定できるメリットとtrade-offの関係になっています。

終わりに
ファッションECサイトを運営していることにより大量の質の高いデータを使えるのは羨ましいと思いました。やはり、大量のデータと最新のモデルを組み合わせるとこんなに良い結果になるんですね。
ただし、現段階ではうまくいくものはうまくいくという感じなのではないかなあとは思っています。以下のように、future workとして複雑な模様なテキストがある服について述べられていて、このあたりは難しいのだと思います。
As future work, we plan to improve the image quality and consistency of the conditional model on more challenging cases, such as generating articles with complicated textures and text.
個人的には、複雑な模様やテキストに関しては経験的に単純にGANを適用するだけではどうしても限界がくることが分かっており、このあたりは3D系の技術と合わせて真面目に取り組まないと本当に精度が高いものはできないのでは?と思っています。
ただ、GANでデータさえあれば、ここまでできるんだなあと思って、これからがますます楽しみです。
また、これまでvirtual try-on(仮想試着)の研究はいくつもあって、この論文の第2 authorのJetchevさんも CAGAN [Jetchev+ ICCV17]という画像ベースの仮想試着の元祖のモデルを提案しています。この問題設定で目的としては、単純にオンライン上での仮想試着は挙げられますが、それと同時にファッションモデルが服を着用したサンプル画像を作成するコストの削減も挙げられます。今回の論文はこの目的に直に向かうもので、現実的にもかなり筋がいいと思いました。このあたりの問題設定のうまさは企業のリサーチチームだからこそなのでしょうか。
この記事が気に入ったらサポートをしてみませんか?