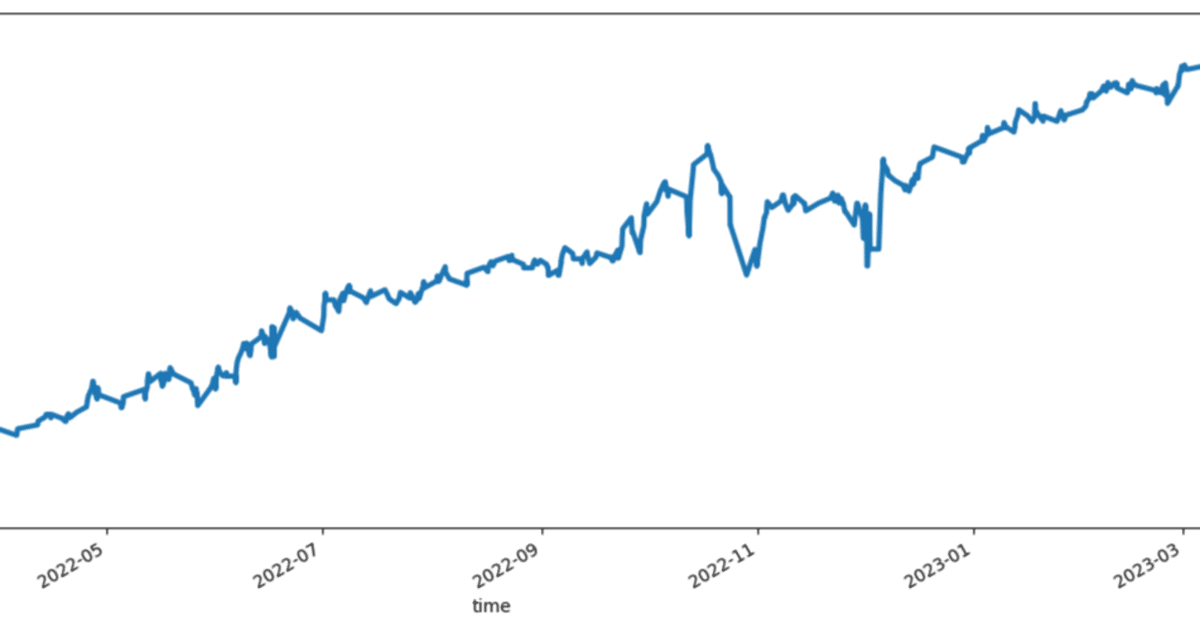
Pythonバックテストのサンプルコード(ADM-EAのロジック実装とバックテスト)

この記事では、ADM-EAのロジックを実装するためのサンプルコードを掲載しています。
ADM-EA(分解モンテカルロ法)とは
以下のページで配布しているEAです。一度バックテストやデモ口座での運用を試してみて、どのような挙動か確認することをオススメします。
この記事では、このEAのロジックについて、
・Pythonでロジック実装する
・Pythonでバックテストを行う
方法をご紹介します。
Pythonでロジック実装する上で必要なコードを詳細まで掲載していますので是非ご確認ください。MT4,MT5でEA開発する際にも十分参考になると思います。
Inputデータの準備
まず、MT5を起動して「表示」→「銘柄」と進みます。
MT5からtickデータのダウンロード
以下のように「ティック」タブで「情報呼出」を行い、「ティックをエクスポートする」をクリックしてtickデータをダウンロードします。
期間を「2023.03.01 00:00:00 - 2023.04.01 00:00:00」と指定すると、2023年3月の1ヶ月分のティックデータがダウンロード出来ます。この際、ファイル名を「GBPJPY_tick_202303.csv」としておきます。

同様にして、202201~202303までの15ヶ月分のデータをダウンロードしてください。
※tickデータはサイズが大きいので、1ヶ月ごとのダウンロードを推奨しています。
MT5からbarデータのダウンロード
続いて「チャートバー」タブで「情報呼出」を行い、「バーをエクスポートする」をクリックしてbarデータをダウンロードします。
barデータはそんなにサイズが大きくありませんので、期間を「2013.01.01 00:00:00 - 2023.04.01 00:00:00」と指定して必要な期間だけ1つのファイルにデータを保存します。
それぞれ以下のファイル名で保存します。
H1(1時間足):「GBPJPY_H1.csv」
M15(15分足):「GBPJPY_M15.csv」
M5(5分足):「GBPJPY_M5.csv」
M1(1分足):「GBPJPY_M1.csv」

tickデータをGoogle Driveに保存
上記でダウンロードしたtickデータをGoogle Driveのtickフォルダに以下のように保存します。

※画像は202303のみですが、202201~202303までの15個のcsvファイルを保存します。
barデータをGoogle Driveに保存
上記でダウンロードしたbarデータをGoogle Driveのbarフォルダに以下のように保存します。

Google Colabの事前準備
ここからは、Google Colabで行う処理です。
Googleドライブのマウント
以下のコードを実行することで、ColabからGoolge Driveにアクセスすることが可能になります。
from google.colab import drive
drive.mount('/content/drive')ライブラリのインポート
必要なライブラリをインポートします。
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from tqdm.notebook import tqdm
import numba
from numba.typed import List
import os
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick年月リストの作成方法
ループ処理を行うために、年月のリスト(YYYYMM_list)を作成しておきます。
# 2022年〜2023年までの年月のリストを作成
YYYYMM_list = []
for year in range(2022, 2024):
for month in range(1, 13):
YYYYMM_list.append(f"{year}{month:02d}")
# 15ヶ月間に絞る(この場合、2022年1月〜2023年3月まで)
YYYYMM_list = YYYYMM_list[:15]この処理により、以下のようなリストが作成されました。
['202201', '202202', '202203', '202204', '202205', '202206', '202207', '202208', '202209', '202210', '202211', '202212', '202301', '202302', '202303']
Inputデータ(csvをpklに変換)
まずは、csvファイルをpandasのDataFrameに変換してpklファイルとして保存します。これによりpandasでインプットデータが扱いやすくなります。
tickデータの変換方法
YYYYMM = '202303'
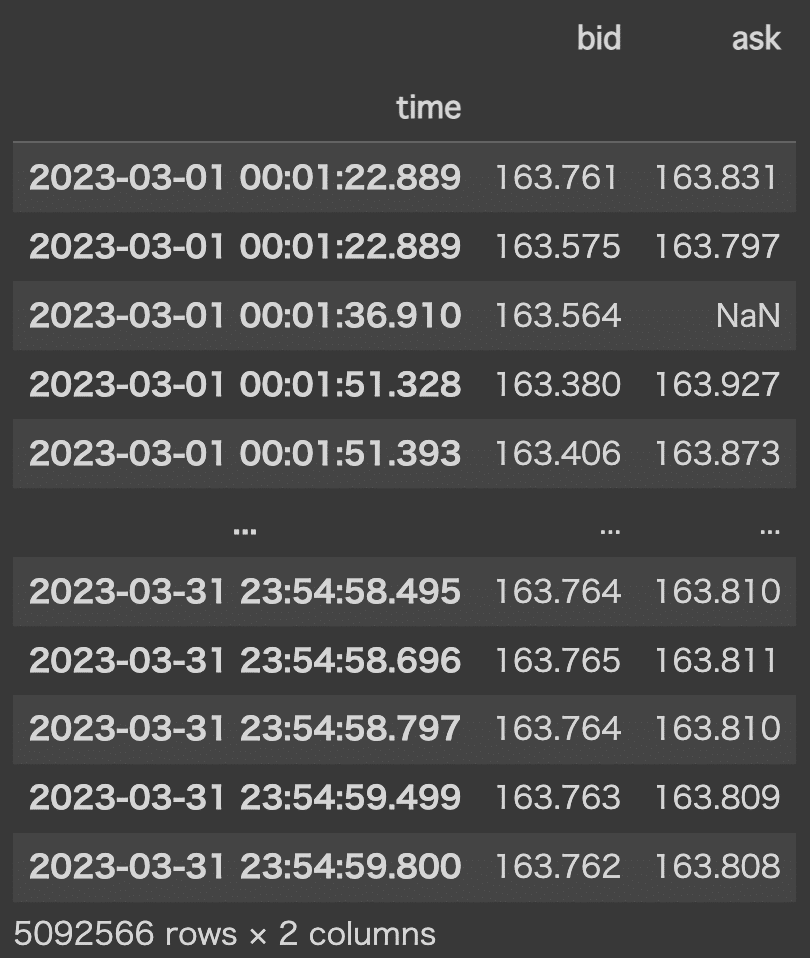
df = pd.read_table('/content/drive/My Drive//tick/GBPJPY_tick_'+YYYYMM+'.csv')
df['time'] = pd.to_datetime(df['<DATE>']+ ' '+ df['<TIME>'])
df = df.set_index('time')
df = df.rename(columns={'<BID>':'bid','<ASK>':'ask'})
df = df[['bid','ask']]
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.pkl')
df実行結果

15ヶ月分のループ処理方法
上記は、202303のみを変換するコードでしたが、以下のループ処理を行うことで15ヶ月分のcsvデータを一気に変換可能です。
for YYYYMM in tqdm(YYYYMM_list):
df = pd.read_table('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.csv')
df['time'] = pd.to_datetime(df['<DATE>']+ ' '+ df['<TIME>'])
df = df.set_index('time')
df = df.rename(columns={'<BID>':'bid','<ASK>':'ask'})
df = df[['bid','ask']]
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.pkl')先ほどの処理で2022年1月から2023年3月までの年月リスト(YYYYMM_list)を作成していましたので、15ヶ月分のpklデータがGoogleドライブに保存される処理になります。
barデータの変換方法
続いて、barデータの変換も行います。最初にashi_listというリストを作成して、1分足(M1)、5分足(M5)、15分足(M15)、1時間足(H1)の4つについてループ処理を行います。
ashi_list = ['M1', 'M5', 'M15', 'H1']
for ashi in tqdm(ashi_list):
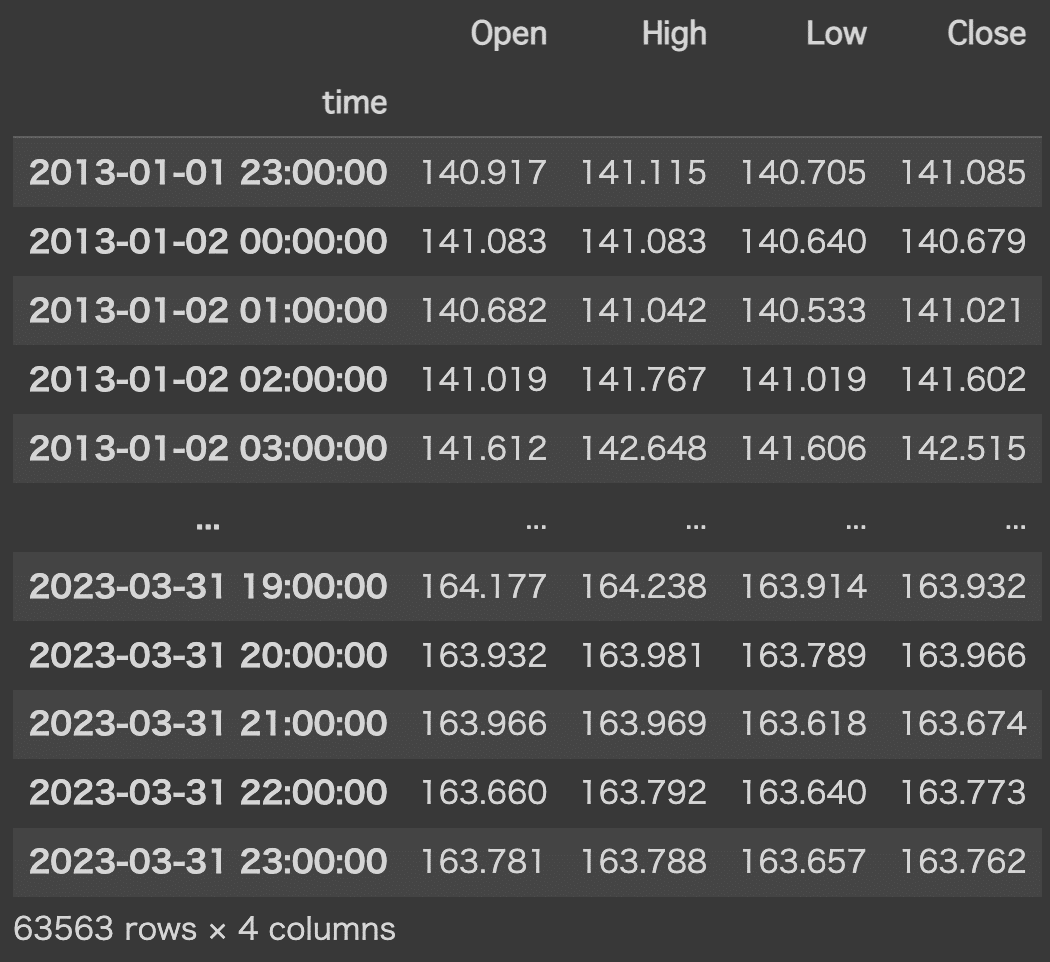
df = pd.read_table('/content/drive/My Drive/bar/GBPJPY_'+ashi+'.csv')
df['time'] = pd.to_datetime(df['<DATE>']+ ' '+ df['<TIME>'])
df = df.set_index('time')
df = df.rename(columns={'<OPEN>':'Open','<HIGH>':'High','<LOW>':'Low','<CLOSE>':'Close'})
df = df[['Open','High','Low','Close']]
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_'+ashi+'.pkl')実行結果
テクニカル指標の計算
続いて、準備したbarデータにテクニカル指標を追加します。
barデータの読み込み
まずは、先ほど作成したbarデータ(.pkl)を読み込みます。
df_M1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M1.pkl')
df_M5 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M5.pkl')
df_M15 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M15.pkl')
df_H1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_H1.pkl')pandas_taのインストール
テクニカル指標計算のために、pandas_taというライブラリを使用します。Google Colabにはインストールされていませんので、以下のようにインストール処理を行います。
!pip install pandas_tapandas_taのインポート
続いて、インポート処理です。Ta-Libというライブラリに似ていますが、コードの書き方等は異なっていて別物です。
import pandas_ta as taテクニカル指標計算関数
テクニカル指標計算用の関数としてcalc_indicatorsを定義します。
def calc_indicators(df):
#四本値の取得
open = df['Open']
high = df['High']
low = df['Low']
close = df['Close']
#テクニカル指標の計算
MA = ta.sma(close, timeperiod=14)
DMP = ta.adx(high, low, close)["DMP_14"]
DMN = ta.adx(high, low, close)["DMN_14"]
ATR = ta.atr(high, low, close, timeperiod=14)
#テクニカル指標の格納
df['ATR'] = ATR
df['MA'] = MA
#DMI_flgの設定
df['DMI_flg'] = 0
df.loc[(DMP > DMN), 'DMI_flg'] = 1
df.loc[(DMP < DMN), 'DMI_flg'] = -1
return df各テクニカル指標の内容や判定ロジックの詳細は以下の記事で解説しています。合わせてご覧ください。
テクニカル指標とbar_timeの追加
先ほど読み込んだdf(データフレーム)形式のbarデータに、テクニカル指標とbar_timeを追加します。
start_time = datetime(2013, 1, 1, 0, 0, 0, 0)
df = df_H1
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=60)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_H1_i.pkl')
df = df_M15
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=15)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_M15_i.pkl')
df = df_M5
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=5)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_M5_i.pkl')
df = df_M1
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=1)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_M1_i.pkl')bar_timeというのは、2013年1月1日の0時を基準とした経過時間を整数で表したものです。
例えば、以下の実行結果(GBPJPY_H1_i.pklの例)であれば、
・2013-01-01 23:00:00→23時間後
・2023-03-31 23:00:00→89,807時間後
といった形です。
後ほど、tickデータとbarデータを連結するために使用します。
実行結果

tickデータにテクニカル指標を追加
ここからは、tickデータにもテクニカル指標を追加する処理です。
barデータの読み込み
まずは、先ほど作成したテクニカル指標とbar_timeを追加したbarデータ(.pkl)を読み込みます。
df_M1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M1_i.pkl')
df_M5 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M5_i.pkl')
df_M15 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M15_i.pkl')
df_H1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_H1_i.pkl')tickデータにbar_time追加
続いて、tickデータにもbar_timeを追加します。datetime形式(2013-01-01 23:00:00など)の時間を、各時間足ごとの整数値に変換することによってマッチングさせやすくします。
start_time = datetime(2013, 1, 1, 0, 0, 0, 0)
for YYYYMM in tqdm(YYYYMM_list):
df = pd.read_pickle('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.pkl')
df = df.fillna(method='ffill')
df['spread'] = df['ask'] - df['bid']
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time_H1'] = (df['time'] - df['start_time'])//timedelta(minutes=60)
df['bar_time_M15'] = (df['time'] - df['start_time'])//timedelta(minutes=15)
df['bar_time_M5'] = (df['time'] - df['start_time'])//timedelta(minutes=5)
df['bar_time_M1'] = (df['time'] - df['start_time'])//timedelta(minutes=1)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_a_'+YYYYMM+'.pkl')以下の通り、それぞれの時間足を基準としたbar_timeをセットしました。

tickデータとbarデータのマッチング関数
それぞれのデータに追加したbar_timeをキーとして、tickデータにbarデータで計算したテクニカル指標を追加します。
@numba.njit
def connect_tick_i(
tick_len,
tick_bid,
tick_bar_M1,
tick_bar_M5,
tick_bar_M15,
tick_bar_H1,
len_bar_M1,
len_bar_M5,
len_bar_M15,
len_bar_H1,
bar_time_M1,
bar_time_M5,
bar_time_M15,
bar_time_H1,
bar_MA_M1,
bar_DMI_M1_flg,
bar_DMI_M5_flg,
bar_DMI_M15_flg,
bar_DMI_H1_flg,
bar_ATR_H1,
):
tick_MA_M1 = tick_bid.copy()
tick_MA_M1[:] = np.nan
tick_DMI_M1_flg = tick_bar_M1.copy()
tick_DMI_M1_flg[:] = np.nan
tick_DMI_M5_flg = tick_bar_M1.copy()
tick_DMI_M5_flg[:] = np.nan
tick_DMI_M15_flg = tick_bar_M1.copy()
tick_DMI_M15_flg[:] = np.nan
tick_DMI_H1_flg = tick_bar_M1.copy()
tick_DMI_H1_flg[:] = np.nan
tick_ATR_H1 = tick_bid.copy()
tick_ATR_H1[:] = np.nan
if tick_len > 0:
for j in range(len_bar_M1):
if bar_time_M1[j] == tick_bar_M1[0]:
M1_j = j
break
for j in range(len_bar_M5):
if bar_time_M5[j] == tick_bar_M5[0]:
M5_j = j
break
for j in range(len_bar_M15):
if bar_time_M15[j] == tick_bar_M15[0]:
M15_j = j
break
for j in range(len_bar_H1):
if bar_time_H1[j] == tick_bar_H1[0]:
H1_j = j
break
for i in range(tick_len):
for j in range(M1_j, len_bar_M1):
if bar_time_M1[j] == tick_bar_M1[i]:
M1_j = j
tick_MA_M1[i] = bar_MA_M1[j-1]
tick_DMI_M1_flg[i] = bar_DMI_M1_flg[j-1]
break
for j in range(M5_j, len_bar_M5):
if bar_time_M5[j] == tick_bar_M5[i]:
M5_j = j
tick_DMI_M5_flg[i] = bar_DMI_M5_flg[j-1]
break
for j in range(M15_j, len_bar_M15):
if bar_time_M15[j] == tick_bar_M15[i]:
M15_j = j
tick_DMI_M15_flg[i] = bar_DMI_M15_flg[j-1]
break
for j in range(H1_j, len_bar_H1):
if bar_time_H1[j] == tick_bar_H1[i]:
H1_j = j
tick_DMI_H1_flg[i] = bar_DMI_H1_flg[j-1]
tick_ATR_H1[i] = bar_ATR_H1[j-1]
break
return (
tick_MA_M1,
tick_DMI_M1_flg,
tick_DMI_M5_flg,
tick_DMI_M15_flg,
tick_DMI_H1_flg,
tick_ATR_H1
)@numba.njitによって高速化していること、一度それぞれの時間の起点を確認してからループを行うことによってループ処理の無駄を減らしていることが特長です。こうした工夫を入れずにただマッチングを行うと、tickデータのレコード数が多すぎるためにかなり時間がかかるかもしれません。
テクニカル指標を追加するループ処理
定義した関数(connect_tick_i)と年月リスト(YYYYMM_list)を用いて以下の処理を行います。
for YYYYMM in tqdm(YYYYMM_list):
df = pd.read_pickle('/content/drive/My Drive/tick/GBPJPY_tick_a_'+YYYYMM+'.pkl')
if(len(df)>0):
(
df['MA_M1'],
df['DMI_M1_flg'],
df['DMI_M5_flg'],
df['DMI_M15_flg'],
df['DMI_H1_flg'],
df['ATR_H1']
)= connect_tick_i(
tick_len=len(df),
tick_bid=df['bid'].values,
tick_bar_M1=df['bar_time_M1'].values,
tick_bar_M5=df['bar_time_M5'].values,
tick_bar_M15=df['bar_time_M15'].values,
tick_bar_H1=df['bar_time_H1'].values,
len_bar_M1=len(df_M1),
len_bar_M5=len(df_M5),
len_bar_M15=len(df_M15),
len_bar_H1=len(df_H1),
bar_time_M1=df_M1['bar_time'].values,
bar_time_M5=df_M5['bar_time'].values,
bar_time_M15=df_M15['bar_time'].values,
bar_time_H1=df_H1['bar_time'].values,
bar_MA_M1=df_M1['MA'].values,
bar_DMI_M1_flg=df_M1['DMI_flg'].values,
bar_DMI_M5_flg=df_M5['DMI_flg'].values,
bar_DMI_M15_flg=df_M15['DMI_flg'].values,
bar_DMI_H1_flg=df_H1['DMI_flg'].values,
bar_ATR_H1=df_H1['ATR'].values,
)
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_i_'+YYYYMM+'.pkl')以下の通り、tickデータに売買判定用の情報を追加することが出来ました。

以上で、バックテストを行う上での事前準備が完了です。
上記データは、
・1秒未満の1ティックあたりの時刻(time)
・価格情報(bidとask)
・スプレッド情報(spread)
・その時間におけるテクニカル指標、売買判断フラグ
という情報を1レコードの中で揃えていますので、これを1レコードずつ読み込んでいって売買シミュレーションを行うという処理が可能になっています。
有料部分の内容
これまで準備してきた内容を用いて、以下の処理を行います。
ADM-EAのロジック部分のコード
以下のロジックを実装しているバックテスト用のコードを掲載しています。
DMIを用いて、買いエントリーを行うか売りエントリーを行うかを判断します。
MAを用いて、エントリータイミングを決定します。
ATRを用いて、利確幅と損切り幅を決定します。
ポジションは買いまたは売りのどちらか1つしか持ちません。そのポジションが利確または損切りをするまで、次のポジションは持ちません。
分解モンテカルロ法を用いて各トレードのロット数を調整します。
より詳細は以下の記事で解説しています。合わせてご覧ください。
バックテスト結果の集計方法
以下のようなdf_ordersという取引履歴データを作成する方法をご紹介しています。
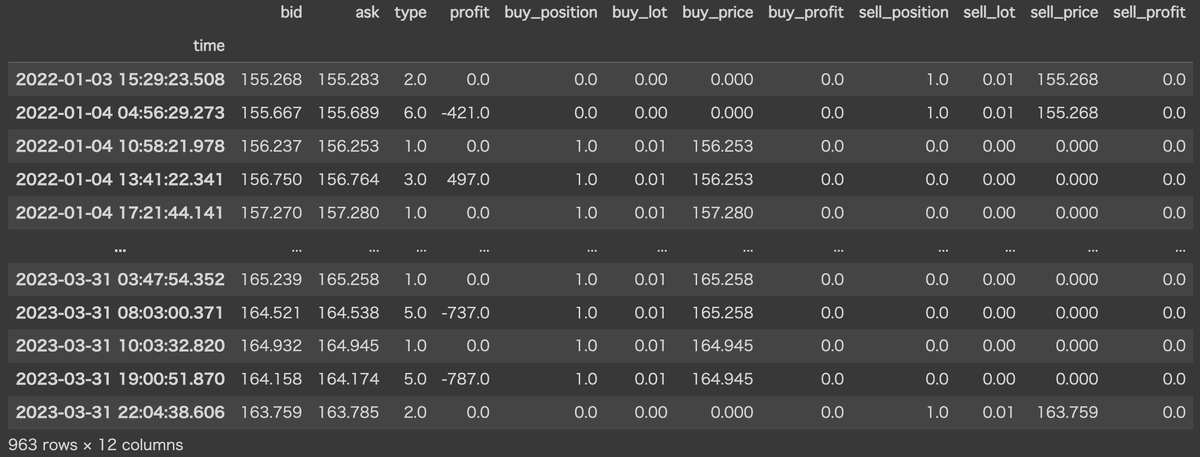
pandasで扱いやすいデータフレーム形式ですので、結果を分析したりパフォーマンス指標を計算したりすることが容易になっています。
損益グラフの作成方法
バックテスト結果(df_orders)から、以下のような損益グラフを作成する方法をご紹介しています。
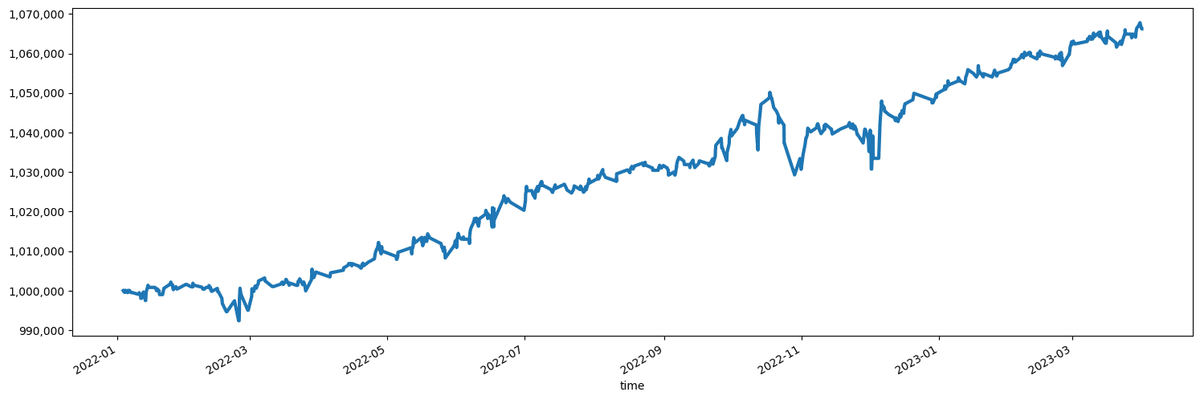
MT5で作成したEAと結果が完全に一致するわけではないですが、基本的に同様のロジックで実装したものです。
以下ではMT5用EAを配布しています。合わせてご覧ください。
パフォーマンス指標の作成方法
以下のように、総損益、プロフィットファクター、取引数、勝率といった、MT4,MT5のバックテストで表示されるようなパフォーマンス指標を計算して表示させる方法をご紹介しています。

15ヶ月間という期間ではありますが、勝率は50%超ということでそれなりに理想的な結果になっております。実際にご自身でバックテストを行なって確認してみてください。
全てのコードを掲載した.ipynbファイルのダウンロード
この記事でご紹介している全てのコードを掲載した.ipynbファイル(Google Colabで実行可能なファイル形式)をダウンロード可能にしています。記事のコードのコピペで上手くいかない場合等にご活用ください。基本的には、そのままGoogle Colabで実行可能かと思います。
なお、ここまでに説明している無料部分のみのファイルは以下からダウンロード可能です。
注意点
当記事で掲載しているコードはGoogle Colab上での実行を想定しています。また、取引シミュレーションを行うバックテスト用のコードです。そのままでは実際のFX取引に使用出来ません。
エラー等が発生しないことを確認しておりますが、状況が変わり実行が出来なくなってしまう可能性もございます。
紹介している画像等と全く同じ結果が出ることを保証するものではございません。
ここから先は
¥ 1,000
よろしければサポートお願いします。いただいたサポートは今後の記事の執筆に活用させていただきます。