
DBの設計とSQL操作(Using Databases with Python: Week 3)

引き続き、ミシガン大学がCoursera上で開講しているPython for Everybody Specializationの第4コース、Using Databases with Pythonを受講した記録です。前回のWeek 2では、データベースの基礎とSQLを用いたPythonプログラミングの概要を学びました。
Week 3では、さらにデータベースモデルの構築について学んでいきます。前半はPythonプログラミングというよりはデータベースの設計に関する学習がメインになりますが、後半で比較的複雑なプログラミングを行っていきますので、まずはコンセプトを理解していきましょう。
1.データベースの設計
<テキストの範囲>
Chapter 15: Using Database and SQLのつづき
データベースのデザイン(データベースの各テーブルの仕様やどの情報をどのように集約するかといった設計)は、Dr. Chuckによれば"いわゆるアート"であり、設計の経験とスキルが求められるものです。私たちがこれから学んでいく目的は、設計ミスをなくし、データベースをよりcleanに、より理解しやすい形に設計することです。
通常、リレーショナル・データベースはいくつものテーブルを持ちます。そして、テーブルが特定のColumnを参照する形で相互に関係し合っています。前回の講義の例では1つのテーブルで、2個のColumnがある程度のシンプルなデータベースでしたが、今回は多数のテーブルと多数のColumnがあり、それぞれ特定のColumnで関連し合う複雑なスキーマを設計します。
リレーショナル・データベースを設計するときは、図を描くと理解しやすい形で設計できます。
それでは、以下のプレイリストについてトラック(曲)を管理するデータベースを構築してみましょう。

まず、トラック(曲)が独自に持つ情報は何かを考えてみます。上の例では「曲名」「時間」「お気に入り」「再生回数」がトラックが持つ独自のデータに見えます。
次に、それぞれのトラックは「アルバム名」に属しており、それぞれのアルバムは「アーティスト名」に属しているように見えます。したがって、以下のような関係性を持つテーブルを設計することができると考えられます。

さて、残るジャンルをどこに配置するかですが、データを見るとアルバムに属しているようにも見えますし、アーティストにも属しているようにも見えます。この点はデータベースの構築で議論になるポイントとDr. Chuckは指摘しています。ここでは、ジャンルはトラックに属すると考えます。
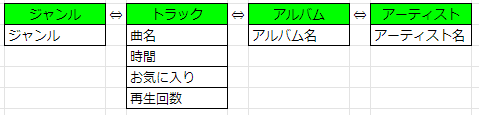
これで、スプレッドシートにあったデータが4つのテーブルで表現されるようになりました。それぞれのテーブルがどのように関連するかは図で表現されていますが、実際にどのようにデータベースを関連付けていくかは、次の項で説明していきます。
2.テーブル同士を関連付ける
テーブルに記録される各データ(Row)は重複を避ける必要があります。しかしながら、偶然にも(アルバム名やアーティスト名が違うものでも)同じ曲名、同じ時間、同じお気に入りレーティング、同じ再生回数のものが発生してしまう可能性があります。このとき、重複を避けるため、それぞれのRowにはユニークなIDなどを振ることが必要となります。このようなキーを、主キー(Primary key)といいます。

これでは、まだテーブル同士が関連付けられたことにはなりません。同士の関連付けには、外部キー(Foreign key)と呼ばれるものを定義します。関連付けたい方向において、矢印の元となるテーブルに外部キー、矢印の先となるテーブルの主キーを参照するようにします。すると、

このような形で、矢印で各テーブルを参照するように関連付けができるようになりました。
それでは、実際に「ジャンル」テーブルをSQLで作成してみましょう。
CREATE TABLE Genre(
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT
)このようにSQLをコーディングすると、ジャンル側のIDは無(NULL)でない主キーであり、自動的に1から順番に振られていくように定義されます。
(※SQLiteの場合)
同様に、「トラック」テーブルも以下のように定義していきます。
CREATE TABLE track(
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
title TEXT,
album_id INTEGER,
genre_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
)ここで、外部キーの型は参照先となるテーブルの主キーの型に合わせます。上の例であれば両方ともにINTEGERと宣言されていますね。
それでは、SQLを用いてデータを入力していきましょう。
INSERT INTO genre (name) values ('ロック')実際のRowには主キーであるidが含まれているはずですが、idは自動的に入力されるため、idの入力は不要です。外部キーを持つテーブルへの入力は、
INSERT INTO album (title, artist_id) values ('あ', 1)とします。このような入力方法では、各アルバムがどのアーティストに対応しているかを関連付けるために、アーティストIDを覚えている必要がありますが、通常はプログラムで自動的に関連付けます。
3.複数テーブルから必要な情報を抽出する
これまでは、多くのColumnを有する一つのテーブルについてデータの性質を理解したうえでデータベースの構造を設計し、複数のテーブルに分けて効率的な管理ができるようになりました。そのため、ユーザーにとって必要な情報を抽出するためには、複数のテーブルから情報を取り出さなければなりません。
SQLでは、JOINという命令を用いて外部キー/主キーで接続されたテーブルから必要な情報を取り出すことができます。
SELECT album.title, artist.name FROM album JOIN artist ON album.artist_id = artist.idSQL構文を一つ一つ見ていきましょう。SELECTで抽出されるのは、アルバムのタイトルとアーティスト名です。次の図の赤字の部分を抽出するイメージです。

FROM album JOIN artistで、これら2つのテーブルを結合します。結合の方法は、ON以下の、albumテーブル側の外部キーであるartist_idと、artist側の主キーであるidが一致することです。(Dr. Chuckによると、あるデータベースのソフトウェアではONの代わりにWHENという命令を使うことがあるようです)
SQLで抽出できるのは、2つのテーブルにとどまりません。4つのテーブル全体から特定の条件を満たすものを抽出することができます。その場合は、ONの後ろをANDで接続するだけで可能です。
SELECT track.title, artist.name, album.title, genre.name
FROM track JOIN genre JOIN album JOIN artist
ON track.genre_id = genre.id AND track.album_id = album.id
AND album.artist_id = artist.id4.Pythonプログラムで複雑なデータベースを操作する
この講義では、iTunesからインポートしたプレイリストのXMLファイルをデータベース化するプログラムをコーディングしていきます。第3コースのWeek 5で学習したXMLスキーマの処理で、要素やattibuteを抽出するプログラムを書きましたが、その応用です。
XMLの操作には、xml.etree.ElementTreeライブラリを用います。
import xml.etree.ElementTree as ET
import sqlite3
conn = sqlite3.connect('trackdb.sqlite')
cur = conn.cursor()
# Make some fresh tables using executescript()
cur.executescript('''
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
CREATE TABLE Artist (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Album (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT UNIQUE,
album_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
''')
fname = input('Enter file name: ')
if ( len(fname) < 1 ) : fname = 'Library.xml'
def lookup(d, key):
found = False
for child in d:
if found : return child.text
if child.tag == 'key' and child.text == key :
found = True
return None
stuff = ET.parse(fname)
all = stuff.findall('dict/dict/dict')
print('Dict count:', len(all))
for entry in all:
if ( lookup(entry, 'Track ID') is None ) : continue
name = lookup(entry, 'Name')
artist = lookup(entry, 'Artist')
album = lookup(entry, 'Album')
count = lookup(entry, 'Play Count')
rating = lookup(entry, 'Rating')
length = lookup(entry, 'Total Time')
if name is None or artist is None or album is None :
continue
print(name, artist, album, count, rating, length)
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES ( ? )''', ( artist, ) )
cur.execute('SELECT id FROM Artist WHERE name = ? ', (artist, ))
artist_id = cur.fetchone()[0]
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES ( ?, ? )''', ( album, artist_id ) )
cur.execute('SELECT id FROM Album WHERE title = ? ', (album, ))
album_id = cur.fetchone()[0]
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, len, rating, count)
VALUES ( ?, ?, ?, ?, ? )''',
( name, album_id, length, rating, count ) )
conn.commit()いつものようにコード全文を理解するのは大変なので、一つずつ見ていきましょう。まずは先頭のSQL文からです。executescript(*)で、複数のSQL文を実行していきます。
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
DROP TABLE IF EXISTSという命令は、すでにファイルの中にArtistやAlbumといった名前のテーブルがある場合は、それを削除します。プログラムを実行していくと何度もテーブルを作成することになるので、いったん前に作ったテーブルをクリアにします。
CREATE TABLE Artist (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
name TEXT UNIQUE
);
CREATE TABLE Album (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT UNIQUE,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
id INTEGER NOT NULL PRIMARY KEY
AUTOINCREMENT UNIQUE,
title TEXT UNIQUE,
album_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);この部分で、ArtistとAlbumとTrackの3つのテーブルを作成します。それぞれのテーブルは、以下のようなイメージになります。

次に、XMLの構造を深く見ていくための関数を定義しています。ひとまず関数の定義については後回しにして、その下の部分を見ていきます。
fname = input('Enter file name: ')
if ( len(fname) < 1 ) : fname = 'Library.xml'
#ここにdef lookup(d, key): があるが省略
stuff = ET.parse(fname) #...[1]
all = stuff.findall('dict/dict/dict') #...[2]
print('Dict count:', len(all)) #...[3][1]では、XML形式のファイルをxml.etree.ElementTreeライブラリのparseメソッドによってツリー形式に構造化します。
その中で、実際の曲のデータはそれぞれのdict/dict/dictという場所に保管されていますので、[2]でfindallを用いてdict/dict/dictにあるデータを全て抽出します。
[3]は確認のためのツリーとして抽出された個数を確認しています。
def lookup(d, key): #...[2]
found = False
for child in d: #...[4]
if found : return child.text #...[6]
if child.tag == 'key' and child.text == key : #...[5]
found = True
return None #...[7]
for entry in all: #...[1]
if ( lookup(entry, 'Track ID') is None ) : continue #...[3]さて後回しにしたlookup関数ですが、まずfor文を見てみましょう。[1]であるように、allというすべてのツリーの中で一つずつ繰り返す処理ですから、entryというオブジェクトは一つのツリーを指す(と同時にカウンタである)ことがわかります。
lookup関数は(d, key)の2つの引数をとります。dは[3]でentryを、keyは[3]で'Track ID'を指しています。ここで、元のXMLを見てみましょう。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Major Version</key><integer>1</integer>
<key>Minor Version</key><integer>1</integer>
<key>Date</key><date>2015-11-24T11:12:10Z</date>
<key>Application Version</key><string>12.3.1.23</string>
<key>Features</key><integer>5</integer>
<key>Show Content Ratings</key><true/>
<key>Music Folder</key><string>file:///Users/csev/Music/iTunes/iTunes%20Music/</string>
<key>Library Persistent ID</key><string>**************</string>
<key>Tracks</key>
<dict>
<key>369</key>
<dict>
<key>Track ID</key><integer>369</integer>
<key>Name</key><string>あいうえお</string>
<key>Artist</key><string>なんとかの歌手</string>
<key>Composer</key><string>なんとかの作曲者</string>
<key>Album</key><string>イケてるアルバム</string>
<key>Genre</key><string>ロック</string>
・・・[4]でchildというものはdのツリーの中をforループでひたすら検索していきます。少しトリッキーですが、まずは[5]を見てみましょう。タグが<key>というタグかを判定しています。そして、タグ<key>の中のテキストが引数のkeyと一致しているかを判定しています。すなわち、
lookup(entry, 'Track ID')であれば、
<key>Track ID</key><integer>369</integer>の項目が見つかったらfound=Trueという形にスイッチします。そうして、わざと1回ループさせると、<key>が'Track ID'であるものの要素(ここでは369)にたどりつきます。found=Trueとなったときに、[6]でこの369という文字をchild.textとして取り出す処理を関数で行っているわけです。
なお、該当する<key>が存在しなければNoneを返します。
したがって、[3]の処理はTrack IDのないツリーは以後の処理を無視してループを一つ進める、という処理になります。
だいぶ進んできました。もうひと踏ん張りです。
name = lookup(entry, 'Name')
artist = lookup(entry, 'Artist')
album = lookup(entry, 'Album')
count = lookup(entry, 'Play Count')
rating = lookup(entry, 'Rating')
length = lookup(entry, 'Total Time') #...[1]
if name is None or artist is None or album is None : #...[2]
continue
print(name, artist, album, count, rating, length) #...[3]
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES ( ? )''', ( artist, ) ) #...[4]
cur.execute('SELECT id FROM Artist WHERE name = ? ', (artist, ))
artist_id = cur.fetchone()[0] #...[5a]
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES ( ?, ? )''', ( album, artist_id ) )
cur.execute('SELECT id FROM Album WHERE title = ? ', (album, ))
album_id = cur.fetchone()[0] #...[5b]
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, len, rating, count)
VALUES ( ?, ?, ?, ?, ? )''',
( name, album_id, length, rating, count ) )
conn.commit()[1]より上の処理は、それぞれName, Atrist, Album, Play Count, Rating, Total Timeのデータがそれぞれのツリーに情報として入っているかを確認し、入っていればそのデータを、入っていなければNoneが変数の中に代入されます。
したがって、どれかのデータが欠落しているものは[2]で以後の処理を行わず、ループを進めます。
[3]は確認のための表示です。
[4]はSQLでINSERTの命令をしていますね。artistの文字列をArtistテーブルに保存しています。[5a]も前回の講義で触れられていた、条件に一致したRowの先頭フィールドを取得するSQLです。つまり、以前にもあったartistの名前がArtistテーブルにあった場合、同じartist_idを振る処理を行っているわけです。[5b]も同様の処理を行っています。
ここまでで、実際にPythonプログラムを実行させてみると、trackdb.sqliteファイルに正常にデータベースが作成されているはずです。プログラムは長くて少し解読に疲れてしまいそうですが、一つ一つを紐解いていくと前回までの内容が大半で、課題を達成するのにもそれほど時間が掛からないかと思います。
今回の講義はここまでとなります。それでは、次回のエントリもお楽しみに!
この記事が気に入ったらサポートをしてみませんか?