
Pythonでデータベースを操作する(Using Databases with Python: Week 2)

引き続き、ミシガン大学がCoursera上で開講しているPython for Everybody Specializationの第4コース、Using Databases with Pythonを受講した記録です。前回のWeek 1では、オブジェクト指向プログラミングの導入を学びました。
Week 2では、リレーショナル・データベースとSQLについて概要を学んでいきます。
1.リレーショナル・データベースとは
<テキストの範囲>
Chapter 15: Using Database and SQL
私たちはプログラムを通じて、データベースに格納されているデータを抽出し、分析することをしばしば行います。また、ある情報をデータベースへ登録するプログラムを作成することもあるでしょう。
まず、この講義ではデータベース・ブラウザのインストールが求められます。Pythonプログラムもデータベースを読み書きできますが、プログラムからもデータベースの読み書きを行うことができます。ここで推奨されているのはSQLite Browserです。Mac, Windows, Linuxなどに対応しているほか、Chrome Plug-inもあります。
リレーショナル・データベースとは、ある表形式のテーブル(Table)に行(Row)および列(Column)を持つデータの集まりです。Excelのような表計算ソフトで見慣れている形式です。ここまでであれば単なる表計算ソフトでも同様のことができるのですが、通常リレーショナル・データベースは複数のテーブルを持っており、テーブル同士が相互に関係(リレーション)を持っているところが特徴です。
今日では、膨大なデータベースから特定のデータを抽出するために、全部のデータをコンピュータに読み込むことはしていません。必要なデータだけを取り出す操作を行っています。
リレーショナル・データベースで用いられる用語は以下のとおりです。
・データベース……多数のテーブルを持つ集合体
・リレーション(テーブル)……タプルとアトリビュートを持つ
・タプル(行:Row)……一般的に、オブジェクトを表現するフィールドのセット
・アトリビュート(列:Column)……行で定義されたオブジェクトに関連する多数のデータの要素。フィールドとも言う
こうして見ると難しい単語のように見えますが、要は以下のようなテーブルのようなものと考えてよいかと思います。
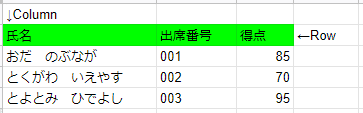
このようにシンプルなテーブルであれば検索が容易にできますが、実際のデータベースはもっと複雑で、様々なテーブルが非常に大容量のデータを持っているケースがあります。そのようなデータベースをPythonなどのプログラムから直接操作するのは非常に難しいものです。
そこで、SQL(Structured Query Language)というデータベースをより容易に操作する言語を用います。SQLを使えば、テーブルを作成したり、データを更新したり、挿入や削除をしたりできます。
2.データベースを操作してみる
例えば、大きな開発プロジェクトであればアプリケーションを開発する人とデータベースを管理する人は異なります。アプリケーションを開発する側では、アプリケーションのロジックを考え、構築していきます。一方で、データベースを管理する側ではプログラムによってデータベースがどのように使われるかをモニターし、調整します。重要なことは、データベース(データモデル)をどのように構築するかは、しばしば両方の人が参加して構築していきます。
データベース・モデルは、データベース・スキーマとも呼ばれ、(ざっくりと言えば)データベースの構造またはフォーマットを指します。
さて、今回はデータベースの構築とプログラムの開発を自分一人で行う小さなプロジェクトのケースを考えます。具体的には、データベースを管理・構築するためにSQLite Browserを用い、一方でデータベースをSQLで操作するPythonプログラムを構築します。
SQLiteを起動し、New Databaseアイコンをクリックすると、まずはデータベースファイルの保存先を聞かれます。都合のよい場所に適当なファイル名で保存しましょう。すると、New Databaseの画面が表示されますが、いったんそれは閉じて、Execute SQLのタブをクリックします。すると、次のような画面が出てきます。
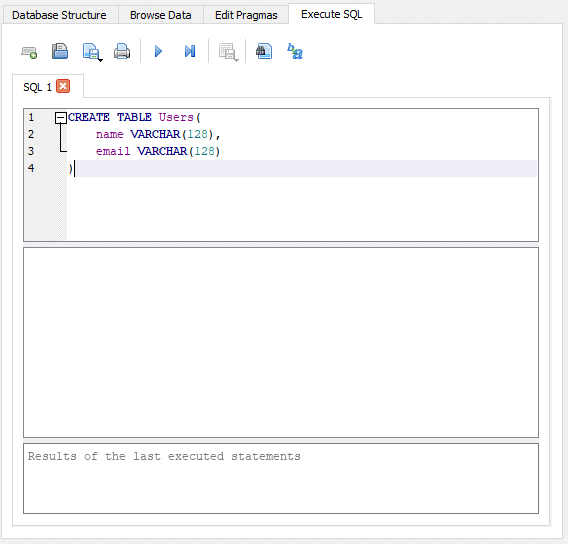
ここに、SQLのコードを入力していきます。
CREATE TABLE Users(
name VARCHAR(128),
email VARCHAR(128)
)
"CREATE TABLE"で「新しいテーブルを作成する」という命令を持ちます。そのテーブル名を"Users"と定義します。その中に、"name"と"email"の2つのColumnを作成します。VARCHAR(128)は、それぞれのColumnが128バイトを上限とするという意味です。
プログラムが終わったら、再生ボタン(▶)を押してみましょう。特に異常がなければ、
Result: query executed successfully.
の文字が一番下のウィンドウに表示されるはずです。これで、テーブルの作成ができました。
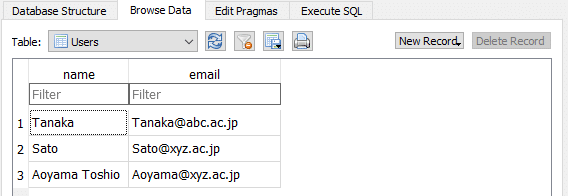
次に、実際のデータを入力していきましょう。Browse Dataタブを開き、New Recordボタンを押して新たなフィールドを作成して入力していきます。
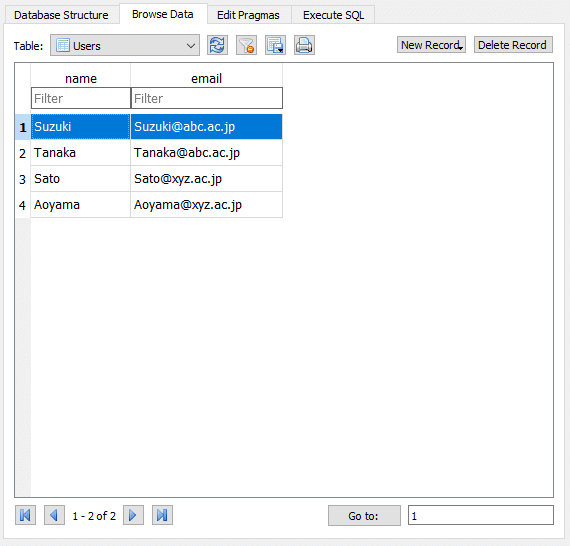
ここでは、私たちがグラフィカルに入力できていますが、実は裏ではSQLが動いています。
INSERT INTO Users (name, email) VALUES ('Suzuki', 'Suzuki@abc.ac.jp')このようにして、実際にテーブルにRowを登録しています。Rowを登録した状態で右下のSQL Logを見ると、このようなINSERTコマンドがバックグラウンドで走っていたことがわかります。
Rowに登録されているデータを削除するには、DELETEを用います。Execute SQLタブに以下のコマンドを入力して実行してみましょう。
DELETE FROM Users WHERE email='Suzuki@abc.ac.jp'
WHERE以下は、Rowすべてを削除するのではなく、条件を満たしたRowだけを削除するというコマンドです。ここでは1つのRowしか削除されませんが、仮にSuzuki@abc.ac.jpのemailを持つRowが100個も1,000個もあった場合はそのすべてが削除されてしまうことに注意してください。
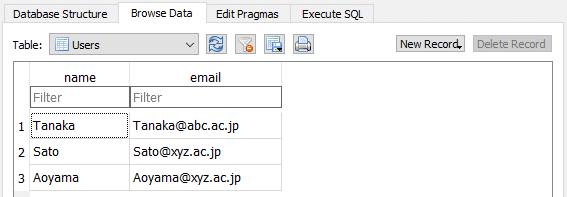
Browse Dataタブに戻ってみると、SuzukiのRowが削除されているのがわかります。
次に、データの更新を見ていきましょう。データの更新には、UPDATEを用います。
UPDATE Users SET name='Aoyama Toshio' WHERE email='Aoyama@xyz.ac.jp'このコードでは、emailがAoyama@xyz.ac.jpという条件を満たすもののnameを'Aoyama Toshio'に更新します。先ほどと同様にExecute SQLでコードを入力し、実行すると、Browse Dataにて結果が確認できます。
最後に、データの抽出をしてみましょう。データの抽出には、SELECTを用います。
SELECT * FROM Users WHERE email='Sato@xyz.ac.jp'ここで、*はColumnすべてを抽出するという意味です。ワイルドカードに似ていますね。一つのColumnだけを抽出したい場合は、SELECT nameなどと書きます。このSQLの実行結果は、以下のとおりになります。
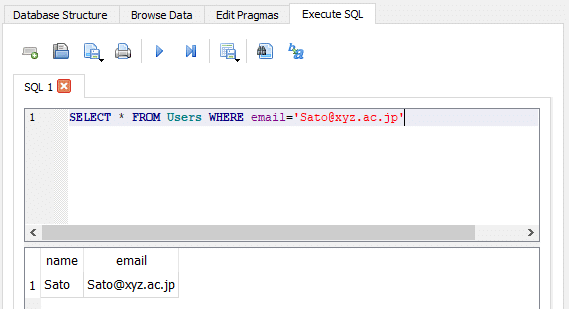
確かに、条件を満たすnameとemailの2つのColumnが抽出されました。抽出するものを昇順で並べ替えて表示する場合は、ORDER BYを用います。
SELECT * FROM Users ORDER BY email3.Pythonでデータベースを操作する
さて、データベースの操作方法が理解できたところで、いよいよPythonでのプログラムを書いていきます。ここでは、Dr. Chuckの講義で用いられているデータベースを解説します。
このプログラムは、受信メールボックスに保存されたテキストデータからメール送信者のメールアドレスを取得し、メールアドレスと受信回数をデータベースに格納するプログラムです。少し長いですが、一つずつ見ていきましょう。
import sqlite3 #...[1]
conn = sqlite3.connect('emaildb.sqlite') #...[2]
cur = conn.cursor() #...[3]
cur.execute('DROP TABLE IF EXISTS Counts') #...[4]
cur.execute('''
CREATE TABLE Counts (email TEXT, count INTEGER)''') #...[5]
fname = input('Enter file name: ')
if (len(fname) < 1): fname = 'mbox-short.txt'
fh = open(fname)
for line in fh:
if not line.startswith('From: '): continue
pieces = line.split()
email = pieces[1] #...[6]
cur.execute('SELECT count FROM Counts WHERE email = ? ', (email,)) #...[7]
row = cur.fetchone() #...[8]
if row is None: #...[9]
cur.execute('''INSERT INTO Counts (email, count)
VALUES (?, 1)''', (email,))
else: #...[10]
cur.execute('UPDATE Counts SET count = count + 1 WHERE email = ?',
(email,))
conn.commit() #...[11]
sqlstr = 'SELECT email, count FROM Counts ORDER BY count DESC LIMIT 10'
for row in cur.execute(sqlstr): #...[12]
print(str(row[0]), row[1])
cur.close()まず、[1]でPython向けに提供されているライブラリのsqlite3を読み込みます。
[2]では、emaildb.sqliteというファイルを読み込みにいきます。ファイルがない場合は、作成します。[3]のカーソルとは、ファイルのハンドルのような作用をします。これを用いて、SQLを実行する(後段のcur.execute()と書かれている所)ことができます。
[4]では、もしファイルがあり、Countsテーブルが存在している場合はテーブルを削除します。この行を置いておくことで、二度三度とプログラムを実行した時に毎回emaildb.sqliteを削除しなくてよくなります。
[5]で、テーブルのColumnを定義しています。テーブルはCounts、Columnはemailとcountの2つですね。
[6]までの式は前回の講義までの復習です。ファイルを開き、"Form:"から始まる行のみを取り扱い、空白で区切られた要素のうち、2番目(pieces[1])の要素をemailという変数に読み込みます。
[7]からいよいよ本格的にSQLでテーブルを操作します。?マークはプレースホルダと言い、email = の後にくる文字列をタプル形式で置換することができる機能です。タプルが1つのときは、(email, )とカンマが入るところに注意しましょう。したがって、[7]のSQLは、送信者のメールアドレスとemailが一致するcount要素をテーブルから抽出します。
SELECT文で実行した結果、条件に一致するRowをいくつも取得してしまいます。[8]のfetchoneメソッドは、その条件に一致したRowの先頭を取得するという意味です。一致するRowがない(新規に出てきた送信者である)場合、if文のelseに飛びます。
[9]と[10]で、Rowがない場合は新規にRowを作成し、Rowがある場合はcountを1追加するようUPDATEのSQL文を実行する形としています。
commit()メソッドは、ここまで変更を加えたデータベースをひとまず更新完了とするコマンドです。このコマンドを行うことで、他の人がデータベースでSQL文を読み込んだとしても更新後の数値を参照することができるようになります。ただし、毎回のcommit()を行うと時間がかかるので、10回に1回など頻度を減らすことでプログラムを高速化できます。
最後に、処理完了したデータベースについて、[12]の上のSQL文をexecuteし、受信回数の上位10名をリストアップします。row変数はタプル形式ですのでstrで変更してあげます。ORDER BY ... DESCを用いることで、降順にソートすることができます。
ここまでで、実際に分析対象とするテキストファイルを読み込み、SQLでリレーショナル・データベースを作成・更新し、そのテーブルを用いて結果を出力する、というミニプログラムが完成しました。ちょっとした達成感がありますね!
少し長くなりましたが、今回はここまでとなります。それでは、次回のエントリもお楽しみに!
この記事が気に入ったらサポートをしてみませんか?