
2024年のComfyUI、完全入門

目次
2024年こそComfyUIに入門したい!

そう思っている方は多いハズ!?
2024年も画像生成界隈は盛り上がっていきそうな予感がします。
日々新しい技術が生まれてきています。
最近では動画生成AI技術を用いたサービスもたくさん生まれてきており、引き続きこの盛り上がりがとどまる気配はありません。
画像生成を行うためのソフトウェアもStable Diffusion web UIやFooocusなどたくさん出てきていますね。
そして今回テーマとして書こうとしているComfyUIもこれらと同じ、Stable Diffusionを用いて画像や動画を生成するためのソフトウェアの一つです。
本題に入る前に、簡単な自己紹介
「あなたは誰?」と思う方もいるかと思うので、簡単に自己紹介をさせていただきます。
サファと言います。
noteは初めて書くので「はじめまして」という形でもあります。
普段はYouTubeで画像生成AI関連の動画を日々投稿しています。

また現在はWindowsのデスクトップPC(GPUはRTX4060 TI / 16G)とGoogle Colabを併用しながら、Stable Diffusion関連のソフトウェアを用いて画像生成・動画生成を行っています。
ComfyUIは最新技術への対応のスピードやカスタムノードという仕組みを採用した拡張性の高さ、処理効率が良い点(低スペックPCでもそれなりに動かすことができる)などの点から非常に魅力的なソフトウェアであり、間違いなく今後もその独自のポジションを位置したまま、画像生成・動画生成の有力な選択肢の一つとして君臨し続けるでしょう。
そのため私のチャンネルでも動画内でComfyUI入門動画を作成しようとしていたのですが、残念ながら私の編集スキルでは最後まで楽しんで見てもらうComfyUI入門動画を作るためには相当な時間がかかりそうでした。
なるべくYouTubeの投稿間隔を空けたくない、という動画投稿者としての個人的な事情はあれど、なるべく入門に必要な情報を分かりやすく伝えるにはどうすればよいか?という観点から、このたび画像とテキストで紹介するという選択を選び、noteで書くことにしました。
もしこの記事を読んで有用だと思っていただけましたら、上のリンクから動画もご覧いただけると嬉しいです。
ComfyUIの特徴とは?

ComfyUIの特徴はなんといっても、このノードとノードを繋いで処理の流れを構築していくタイプのUIで、この処理の流れをファイルなどで共有もできることから、様々なワークフロー(作成した処理の流れをワークフローと呼びます)を公開している方が世界中にたくさんいます。
例えば…
入力画像を渡すだけでStable Video Diffusionを用いて動画化してくれるワークフロー
プロンプトと参照画像を入力するだけでAnimateDiffで動画を作成し、その上アップスケールの処理も行ってくれるワークフロー
少し前に話題になっていたStream Diffusionをサクッと試すことができるワークフロー
などなど、1から導入すると準備も大変になるこれらの処理をワークフローを読み込ませるだけで実行できるようになるのは、とても便利ですし、最新技術を試す際にもとても重宝します。
(もちろん、必要な拡張機能がインストールされていない場合は実行できません。しかし後述するComfyUI Managerから足りない拡張機能はインストールすることができるなど、ワークフローの実行に足りていない部分を補完する仕組みもすでに存在します)
またその他のComfyUIの特徴としては、
・比較的Stable Diffusion web UIやFooocusと比べて、最新技術への対応が早い
・生成速度が他のソフトウェアと比べて速い(もちろん環境によるので例外はあります)
・動作が他のソフトウェアと比べて軽い(もちろん環境によるので例外はあります)
などがあり、非常に魅力的なソフトウェアとなっています。
ComfyUIはとっつきにくい?
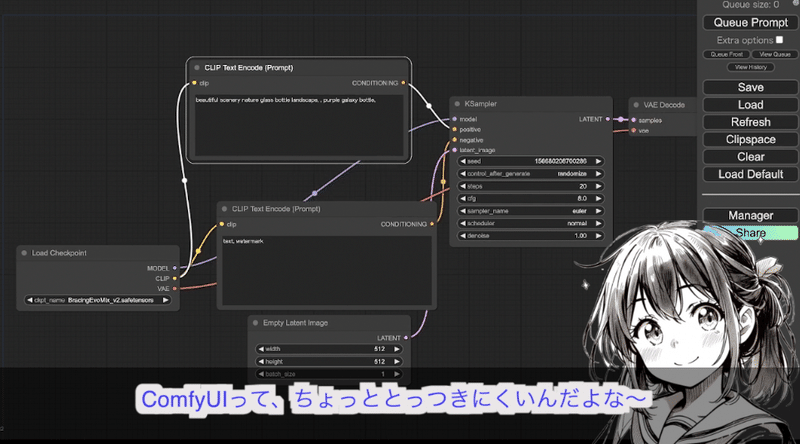
そんなメリットばかりが目立つComfyUIですが、逆にこのノードベースの画面は自由度が高すぎて初心者にはとっつきにくいのも事実です。
画像生成AIのソフトウェアとして有名なソフトウェアである、Stable Diffusion web UIと比べると、どちらが利用しやすそうかは一目瞭然かもしれません。

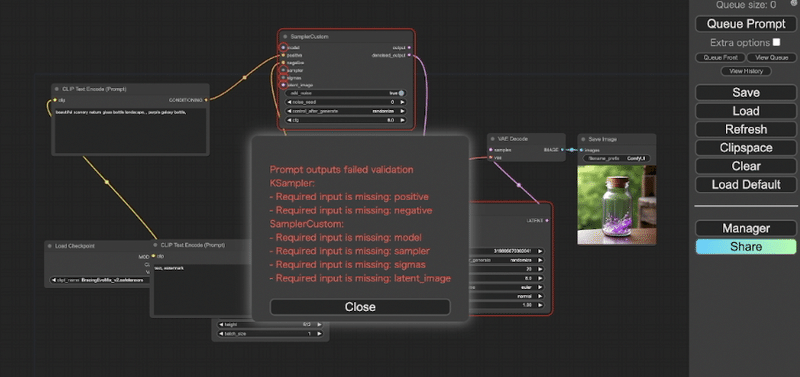
また、色々と自分で処理を作成しようとすると、すぐにこのようなエラー画面が出てげんなりしてしまうかと思います。
この記事を読むとComfyUIに入門できる?
この記事を読むことで、魅力的で敷居の高いComfyUIでも、とりあえず画像生成や動画生成ができるようになります。
ComfyUIのすべてを理解することはできませんが、まずは入門すれば楽しく学びながら操作できます。
私もまだまだComfyUIに慣れていませんが、初めて使った時に便利だったことや知りたかったことなどもまとめていますので、最後まで読んで一緒にComfyUIを楽しんでいきましょう!
またこの記事はStable Diffusion web UIからComfyUIに乗り換え(または共存)を検討されている方にも有用な情報を載せています。
もし該当する方は、ぜひこの記事をお読みいただきスムーズにComfyUIに入門できれば幸いです。
想定読者
ComfyUIに入門したい!
Stable Diffusion web UIを触っていたけど、2024年はComfyUIにも入門してみたい!
Google Colab環境で画像生成をしているけど、ComfyUIを触ってみたい
以上が想定される読者となります。
上にも書いたようにWindows PCで画像生成をしている方でも、Google Colabで画像生成をしている方でもウェルカムな記事となっていますので、ぜひ皆でComfyUIに入門していきましょう!
ComfyUIのインストール方法(Windows編)
では、まずはComfyUIの導入方法を手短に説明していきます。
ここについては現在ではすでに情報がたくさん出ていますので、ダウンロードしてComfyUIを起動するところまでを簡単に説明していきます。
Windows環境でのインストール方法
ComfyUIの公式リポジトリ(公式ページ)はこちらになります。
まずはこちらにアクセスしてください。そして画面の下の方にスクロールすると、こんな画面が出てくると思います。この赤枠のリンクをクリックしてください。

このリンクをクリックするとダウンロードダイアログが表示されます。
あとは指示に従ってZIPファイルをダウンロードし、手元で解答して中にあるrun_nvidia_gpu.batというバッチファイルをダブルクリックすることでComfyUIが起動します
ComfyUIを起動したら画面右上のQueue Promptを押してみましょう。
これがComfyUIでのGenerateボタンとなります。

無事に上のように画像が生成できたら画像生成完了です!
Windows 11なら7-Zipは不要!?
ちなみにダウンロードしたZIPファイルは7zip形式で圧縮されています。
これのZIPファイルを解凍するには7-Zipというソフトウェアを利用する必要があり、その旨がComfyUIのダウンロードリンクのすぐ下にも書かれています。
しかしWindows 11では7zipファイルの解凍機能はWindows側に組み込みで搭載されているようです。
そのためWindows 11環境の方は7-Zipのインストールは不要かと思います。
Stable Diffusion web UIで利用しているモデルをComfyUIでも利用したい!
ちなみに既にStable Diffusion web UIを利用されている方は、既にダウンロードしているモデルなどをComfyUIのために再度ダウンロードしたり、指定のフォルダにコピーするのはディスク容量を圧迫してしまう、という観点から、あまり行いたくないかもしれません
ComfyUIにはStable Diffusion web UIで既に画像生成を行っている人のための仕組みが用意されており、ComfyUI側で設定することでStable Diffusion web UIで利用しているモデルやLoRA、VAEなどをそのままComfyUI側でも読み込むことができます。
やり方は簡単です。
まずはComfyUIのフォルダ内に extra_model_paths.yaml.example というファイルがあるので、こちらをコピーして extra_model_paths.yaml というファイル名に変更します

次にこの extra_model_paths.yaml というファイルの中を以下のように設定します。
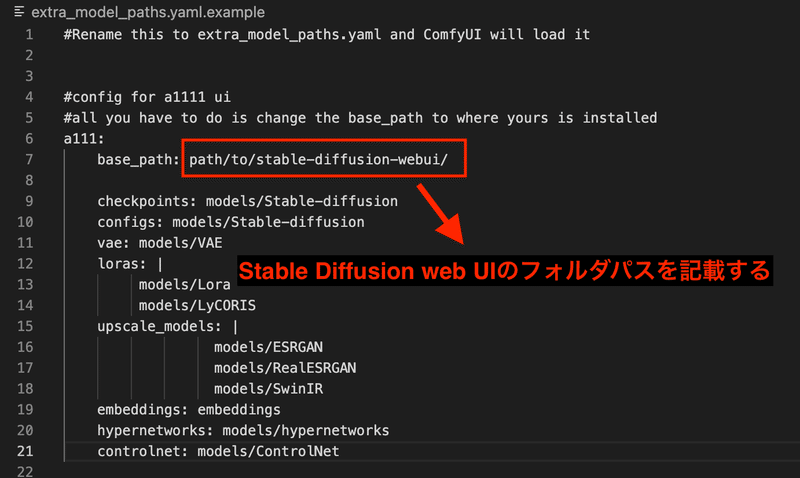
書き換えが完了したら、ComfyUIを起動してみましょう!
Checkpointを選択する際に、Stable Diffusion web UI側で利用しているモデルを参照できれば設定はうまく行っています。

手順をまとめると。以下のようになります。
すぐに終わりますし、ディスク容量も無駄に圧迫しないで済むので、ぜStable Diffusion web UIを利用していた方はぜひ設定してみてください!

ComfyUIのインストール方法(Google Colab編)
ComfyUIをGoogle Colabから利用する際に公式のColabノートブックを使おうとしていましたが、ComfyUI-Manager側のColabノートブックを使う方がManagerも始めから入っているし、こちらの方がスムーズに使い始められそう...
— サファ【AIイラスト多め】 (@safa_dayo) January 5, 2024
(台本修正しなくちゃ🥺)https://t.co/LwKDsUPgYa
次にGoogle ColabでのComfyUI導入方法ですが、上にも貼ったように最初はComfyUIの公式Colabノートブックを利用することを検討していましたが、後述するComfyUI ManagerというComfyUIの拡張機能を管理するための拡張機能のリポジトリで提供されているColabノートブックを利用するほうがスムーズに始められることに気づきました。

理由としてはこちらの方がComfyUI Managerが最初から導入されているため、凝ったワークフローを利用する際にスムーズに始めることができます。
Google Colab Pro前提での説明となります
なお、ここに書いてあるColabノートブックの設定方法はGoogle Colab Pro環境で動作確認をしています。
現在Colabの無料プランではStable Diffusion web UIなどと同様に利用が制限されているようなので、利用にはColab Proプランに加入する必要があります。
ただ、Google Colab Proに契約しても月額1,200円ほどで試すことはできるので、個人的には気軽に契約してみても良いかなと思っています。
もしColabの契約を検討している方は、以下の動画でもColabで画像生成を行うことのメリット・デメリットについて解説していますので、よろしければチェックしてみてください(宣伝)
Google ColabでのComfyUIインストール方法
というわけで、導入方法を説明していきます。まずは ComfyUI Managerの公式リポジトリにアクセスします。
アクセスしてから少し下の方にスクロールすると、以下のようなリンクが出てくるので、こちらにアクセスしてください。

すると、先ほどのようなColabノートブックの画面が表示されます

このColabノートブックは複数のセルに分かれており、上から3つのセルをそれぞれ順番に実行していくことでComfyUIの起動が完了します。
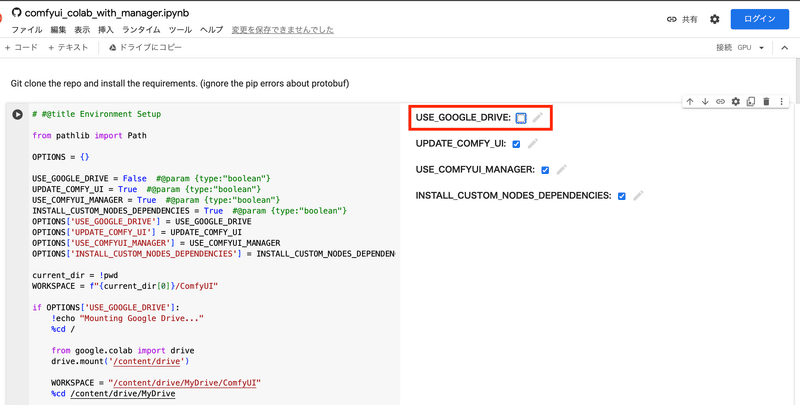
また、1つ目のセルの右側にあるチェックボックスをクリックすることで、設定を変えることができます。
私は基本的にColabノートブック上でGoogle Driveを連携させることは少ないので、USE_GOOGLE_DRIVEというチェックボックスは外した状態で実行することが多いです。
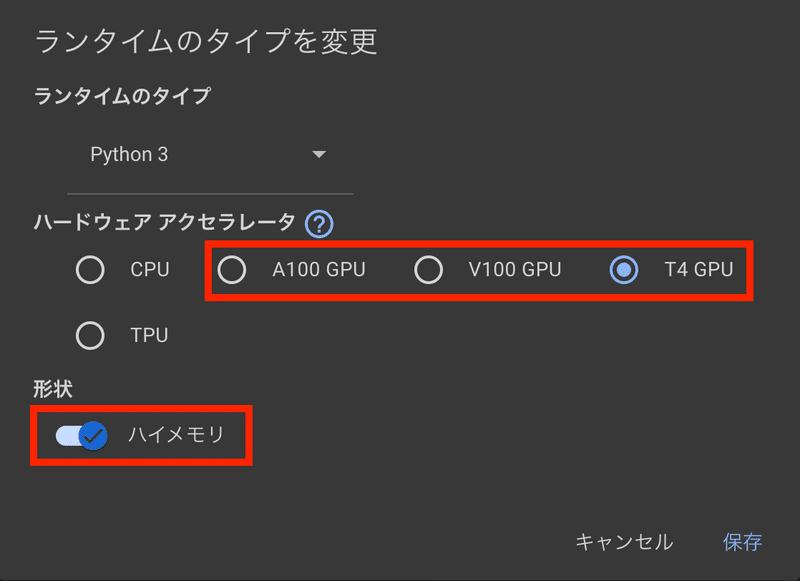
ランタイムの設定について
またGoogle Colabで実行する際はランタイムのタイプを設定することになりますが、最低でもT4 + ハイメモリを選んでおけば、ストレスなく生成できるかと思います。
動画生成などを行いたい場合はV100 + ハイメモリ以上にしたほうが待ち時間も少なく生成できるのでおすすめできます。
以上でGoogle Colab環境でのComfyUIセットアップ方法については終了です。
別途利用したいモデルなどがあればノートブックをコピーして、独自にコマンドを書き換えることでアレンジが可能ですので、色々と試してみてください。
ComfyUI Managerは必須拡張機能
ComfyUIの画面を起動させることができたら、次のステップです。
Stable Diffusion web UIでは拡張機能を管理する仕組みはデフォルトで用意されていますが、ComfyUIでは別途拡張機能を管理する拡張機能をインストールする必要があります。
Google Colab環境の方は上でご紹介したColabノートブックで起動することで、最初からComfyUI Managerが入った状態で起動することができますが、Windows環境の場合は自身でインストールする必要があります。
ComfyUI Managerのインストール方法
インストールを行うにはgitをWindows PC上に入れておく必要があります。もしまだの方は以下のリンク先からダウンロードしてインストールしましょう。
インストーラーをダウンロードしてから起動させると、インストールダイアログが表示され、色々と聞かれます。
私は基本的にデフォルトのままでインストールをしたと思いますので、もし内容がわからない方はそのまま次へ次へで進めていけば良いでしょう。
インストールが完了したら、ComfyUIのフォルダ内にある custom_nodes というフォルダを右クリックしてコマンドプロンプトを開きます。
そこで以下のコマンドを実行してください。
git clone https://github.com/ltdrdata/ComfyUI-Manager.gitそして再度ComfyUIを起動すれば、以下のように画面右下にManagerというボタンが増えていることが確認できます。
これでComfyUI Managerのインストールは完了です。

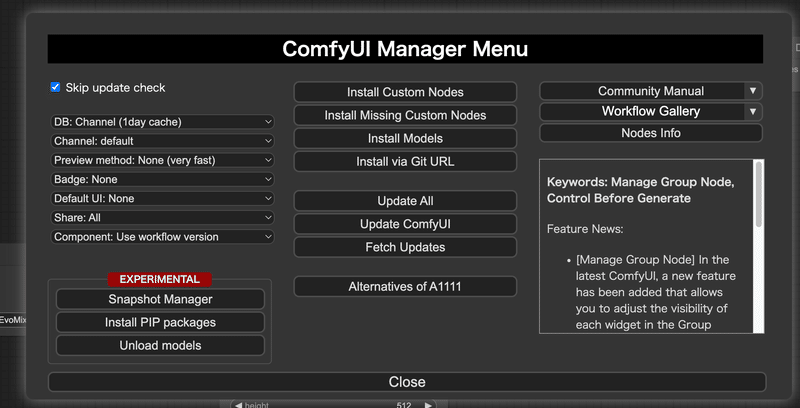
ComfyUI Managerの使い方
ComfyUI Managerを開くとこのような画面が表示されると思います。
(今後のバージョンアップで画面デザインが変更される可能性はあります)

ComfyUI Managerは拡張機能を管理するという仕事をこなしつつも、実に様々な機能を持った拡張機能なので、ComfyUI Managerでやれることをすべて説明しようとすると、それだけで膨大な量になってしまいます。
そのため、今回はこれだけ知っていればComfyUI Managerを用いて拡張機能の管理ができる、という部分だけ説明していきます。
Install Custom Nodesでカスタムノードをインストール
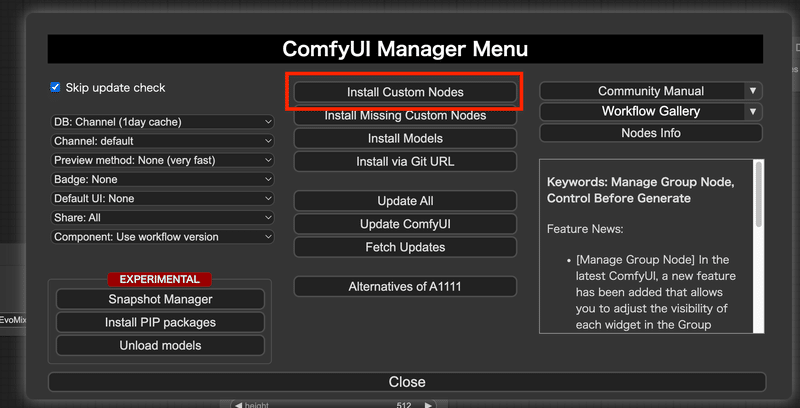
今まで拡張機能という言葉を使ってきましたが、ComfyUIでは拡張機能のことをカスタムノードとも呼びます。
そしてカスタムノードをインストールするために利用するボタンが、Install Custom Nodesという上の画像の赤枠で囲われた部分となります。
こちらのボタンを押すと、以下のような画面が表示されます。
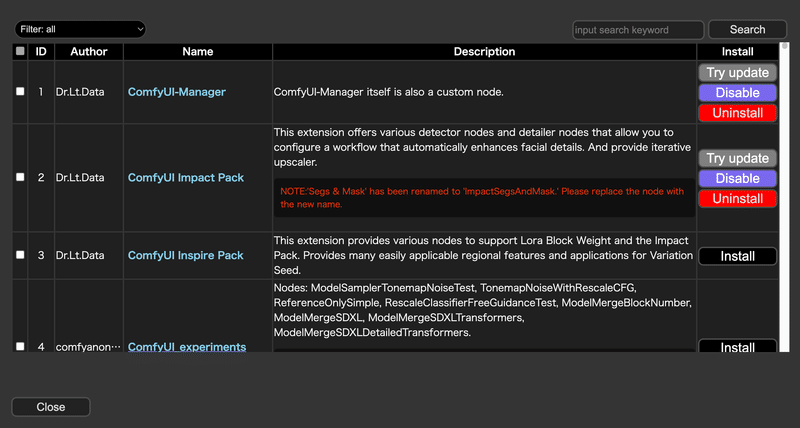
この画面上でカスタムノード(拡張機能)を管理していきます。
ただし一点注意点があり、ここに表示されている拡張機能はあくまでComfyUI Manager側で登録されている拡張機能のみが表示されており、例えば手元にしか存在しない自作の拡張機能を直接custom_nodes配下に格納して利用しているような場合、その拡張機能に関する情報は表示されませんのでご注意ください。
(脇道)自作のカスタムノードをComfyUI Manager経由でユーザーにインストールしてもらうには?
もし仮にあなたが自作のカスタムノードを将来作成し、ComfyUI Manager経由でユーザーにインストールさせたいと考えている場合、現在の運用としてはComfyUI Managerの公式リポジトリに直接登録のためのPull Requestを送って、作者に取り込んでもらう必要があります。
(2024年1月現在では、ComfyUI Managerのcustom-node-listというjsonファイルで管理されています。)
https://github.com/ltdrdata/ComfyUI-Manager/blob/main/custom-node-list.json
また、custom-node-listに登録してもらう以外に、以下のInstall via Git URL から直接URLを入力してカスタムノードをインストールさせることもできます。

少し脇道にそれてしまいましたが、画面の基本的な機能をお伝えします。
まずはカスタムノードのフィルタリング機能。
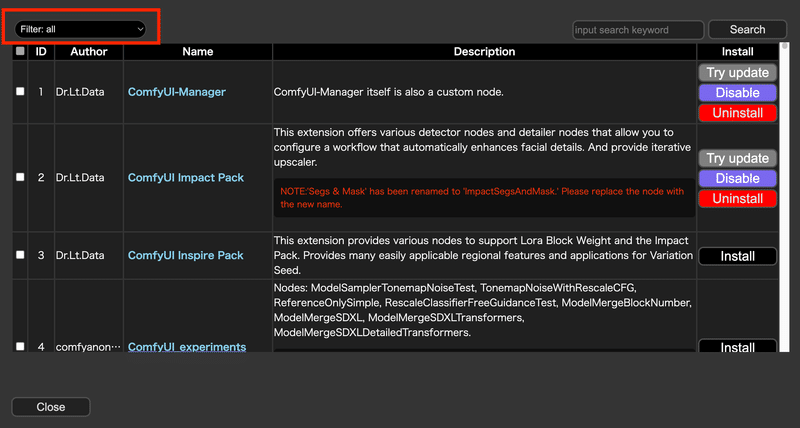
このフィルタリングのセレクトボックスを変更することで、インストール済みの拡張機能や無効化している拡張機能のみをフィルタリングして表示させることができるようになります。
既にインストールしているカスタムノードについては、上のスクリーンショットにも表示されているように、拡張機能のアップデートや無効化、アンインストールなどを行えます。
そのためこのフィルタリングは拡張機能を管理する、という側面からもとても便利です。

欲しい拡張機能を検索する際は画面右上にある赤枠からテキストを入れて検索します。
先ほどもお伝えしたようにここの検索に引っかかるのは、あくまでComfyUI Managerに登録されているカスタムノード(拡張機能)のみとなる点には注意してください
しかし今回の入門記事で目指している、誰か作成したワークフローを利用して、ComfyUI上で画像生成・動画生成を行いたい!というユースケースであれば、ほぼほぼComfyUI Managerで登録されているカスタムノードだけで事足りるかと思うので、現状であまり不満はないかとも思います。
足りないカスタムノードを検出してくれるInstall Missing Custom Nodes

ComfyUIをインストールしたての状態で誰かが作成したワークフローを動かすと、大抵の場合「このカスタムノードがないよ!」というエラーが出ます。

そんなときはこのボタンを押すと、現状足りていないカスタムノードを検出して一覧に表示してくれます。

あとは左側のチェックボックスにチェックをそれぞれ付けて、インストールボタンを押せば良いだけ!
そのため誰かが作成したワークフローを利用してカスタムノードが足りないエラーが出たら利用してみてください。
他にも、先ほどもちらっと話したgitのURL経由でインストールできる機能など様々な機能はありますが、いきなり詰め込みすぎず、まずはこれらの機能をしっかり使いこなせればよいかと思います。
ワークフローjsonについて
ComfyUIでは作成したワークフローはJSON形式のテキストファイルで表現することができます。
試しにComfyUIの画面右側にあるメニューからSaveを押してみましょう。
以下のような画面になるかと思います。

Saveボタンを押してから保存したいファイル名を入力してOKを押すと、JSON形式のファイルでワークフローを保存できます。
ここでダウンロードしたJSONファイルは、ComfyUIの画面上にドラッグアンドドロップで読み込むことができ、保存当時の状態を簡単に再現できます。
また、ComfyUIで生成した画像にはワークフロー形式でファイル内のPNG Infoに保存されているほか、生成した動画についてもワークフロー形式の情報が書き込まれていることを確認しています。
(すべての動画が保存されているかは分かりませんが、動画生成時に利用するVideo Combineノードで作成した動画は少なくともワークフロー情報がファイル内部に保存されていることを確認しています)
そのようなわけで、簡単に生成当時のワークフローを再現できるというのは、作成したワークフロー情報を共有する上ではとても便利な仕組みとなっています。
Stable Diffusion web UIの画像(infotext)を読み込むことが可能?
ちなみにStable Diffusion web UIにもinfotext形式という形で生成時のプロンプト情報が格納されています。
実はこのinfotext形式を読み取る機能がComfyUIには搭載されているようで、Stable Diffusion web UIで生成した画像をComfyUIの画面にドラッグアンドドロップすることで、生成時のプロンプトなどを読み取ることができる…だけじゃなく、なんと画像生成のためのワークフローも再現してくれます。
といっても、Stable Diffusion web UI側でAfterDetailerを利用している場合はComfyUI側でFace Detailerを用意してくれる、といった気の利いた形での再現ではなく、必要最低限の画像生成ワークフローを整えてくれるだけのようです

ただ、Stable Diffusion web UIで生成した画像を元にComfyUI側でにワークフローを組んで生成を行いたい場合は便利な機能ですね。
infotextとは?と思った方は以下の動画で解説もしているので、よろしければご覧になってみてください
実際に公開されているワークフローで遊んでみよう
ではComfyUIや、ComfyUIで利用するワークフローについての基礎をお伝えしたところで、ここからは実際に動かして生成を行ってみましょう!
今回紹介するワークフローはすべて素晴らしい先人たちが公開してくれているものです。ありがたく巨人の方に乗ったつもりで利用させてもらいました。
Stable Video Diffusionでimg2vid + フレーム補間
まずはStable Video Diffusionで画像から動画を生成するためのワークフローを公開してくれている方の紹介です。
詳細な内容は以下のnoteで公開してくれていますので要チェックです。
利用するワークフローは上のリンクからnoteのページに遷移していただき、一番の下の方にある以下のワークフローを利用させていただきます。

こちらのワークフローを利用するためには以下2つの拡張機能が必要になります。
インストール方法はComfyUI Managerからそれぞれ検索を行うことで問題なくインストールが可能です。
ComfyUI-VideoHelperSuite
ComfyUIで動画周りを扱う際には必須となる拡張機能。Stable Video Diffusion以外でも必要になる機会は多いので、入れておいて損はないでしょう
ComfyUI Frame Interpolation (ComfyUI VFI)
動画のフレーム補間を行うことで動画のヌルヌル化を達成するための拡張機能。こちらをワークフローに組み込むことで、別のソフトウェアでいちいちフレーム補間をかけずとも、生成時に合わせてヌルヌル化が行えるので手間が少し減ります
Google Colab環境の方はリンク先のnoteの方にある以下のリンクをクリックしてColab環境を起動してください。
上の拡張機能についてのインストールコマンドも書かれているので、実行するだけですぐに使えるようになります。
便利!

ランタイムを設定してからComfyUI ManagerのColabノートブック同様に上3つのコードセルを実行すれば起動できます
Windows環境でもColab環境でもComfyUIを起動したら、まずは先ほどダウンロードしたワークフローファイルを画面にドラッグアンドドロップで入力します。
すると以下のような画面になるので、赤枠のノードから動かしたい画像をアップロードします。

次にアップロードした画像のサイズに合わせて、幅を設定します。
(画像サイズに合わせなくても、そこまで大きく崩れるわけではありませんが、幅は画像サイズに合わせたほうがクオリティが安定します)
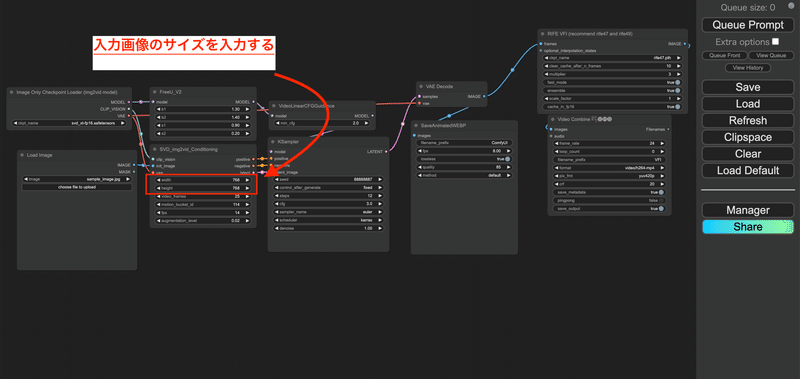
後は実行して完成を待つだけ!
びっくりするぐらい簡単ですよね!

実際に作成してみたところのスクリーンショットです

このように簡単にStable Video Diffusionを試すことができますのでオススメです。
ちなみにGoogle ColabでランタイムをV100 + ハイメモリで実行した場合でも、5分以内に動画化が終わります。
これは512x1024の画像サイズで試したときに測ってみたものですが(と言っても厳密には測っていません)、およそ2~3分ぐらいで終わっていたので、動画生成にしてはかなり速い部類かなと思います。
なお、こちらの内容については以前動画でも紹介させていただいています。
サクッと画像を動画化したい方、実現するための手順も明確で非常にわかりやすいので、オススメですよ
AnimateDiff + FaceDetailerで顔を崩さずに動画生成
次は以下のnoteの記事で紹介されているワークフローを紹介させていただきます。
こちらはFaceDetailerを用いてAnimateDiffでの動画生成時に、顔が崩れないように動画を作成するためのワークフローとなっています。
FaceDetailerの使い方についても詳しく書かれているので、是非一度してみることをおすすめします。
まずは上のnoteで公開されているワークフローの実現方法から見ていきましょう。
その後に今回は上のnoteを改造したワークフローを作成したので、そちらについても併せて紹介していきます。
これを読むことで実際に自身でワークフローを作成する手立ての一つになれば幸いです。
まずはComfyUIを起動させます。Google Colabの方は、先ほど紹介したComfyUI Managerが提供しているColabノートブックでComfyUIを起動してください。
ComfyUIが起動後、上のnoteで配布されているワークフローをドラッグアンドドロップで入力します。
するとご覧のように必要な拡張機能が入っていない場合は、真っ赤な画面になります。
(Windows環境などで既に必要な拡張が入っている場合は赤くならないかもしれません)

そうしましたらComfyUI Managerを開いて Install Missing Custom Nodesを押します。

すると、足りないカスタムノードが出てくるので、左側のチェックボックスをすべてチェックしてインストールボタンを押します

次に一度ComfyUIを止めます。Colab環境の方はコードセルを新規で追加して以下のコマンドを実行します。
コマンドを実行したら、再度ComfyUIを起動して先ほどのワークフローファイルを適用した形で、再度実行します。
!wget https://civitai.com/api/download/models/249532 --content-disposition --directory-prefix=/content/ComfyUI/models/checkpoints
# ワークフロー側で呼び出しているファイル名と異なるためファイル名の方を変更
!mv /content/ComfyUI/models/checkpoints/megane_a3.safetensors /content/ComfyUI/models/checkpoints/MeganeA3.safetensors
!wget https://huggingface.co/guoyww/animatediff/resolve/main/mm_sd_v15_v2.ckpt --directory-prefix=/content/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/modelsWindows環境の方は以下のモデルと、AnimateDiff用のモデルをダウンロードしてください。
利用するモデルはCivitaiからダウンロードできます。
なお、こちらのワークフローでは megane_a3.safetensors というファイル名ではなく MeganeA3.safetensors というファイル名で参照しているようです
ファイル名自体を修正しても良いですし、Load Checkpointノードからモデル名を選択し直すでも良いでしょう。
(Colab側はファイル名を選択し直す方針でコマンドを書きましたが、どちらでも良いと思います)
また、AnimateDiff用のモデルは以下からダウンロード可能です。
こちらのmm_sd_v15_v2.ckptというのをダウンロードして、ComfyUI¥custom_nodes¥ComfyUI-AnimateDiff-Evolved¥modelsに格納してください。
この状態でComfyUIを起動すると、先ほどのワークフローを用いて動画の作成ができるようになっていると思います。
こちらのワークフローの特徴はAnimateDiff + FaceDetailer(SD web UIでのAfter Detailer)を組み合わせているワークフローになっているところです。
FaceDetailerは顔が崩れないように動画を作成するためにはComfyUIでも必須のカスタムノードとなっているので、こちらも絶対に抑えておくべきワークフローとなります。
早速ワークフローを改造して、AnimateDiffでの動画をヌルヌル化してみよう!
さて、上のワークフローを動かすことでAnimateDiffで動画が作れるようになりましたね。
せっかくならここで最初に紹介したStable Video Diffusionワークフローに組み込まれていたComfyUI Frame Interpolationを用いて、動画をヌルヌル動かしていきたいですよね!
【ComfyUI学習のポイント】
まずは既存のワークフローに一つだけ機能を組み足すこと
ComfyUIでワークフロー周りを学習する上で最初に心がけたいのは、このように小さく機能を足すことです。
ComfyUIは沢山のスクリーンショットとともに紹介してきたように、非常に敷居の高いソフトウェアです。
いきなり最初から『私の考えた最強の生成ワークフロー』を作ろうとすると、出現する大量のエラーに大半の人は心が折れてしまうでしょう。
そのため、まずは
・一つだけ機能を追加する
・一つだけ機能を変更する
というふうに小さくステップアップしていくことをおすすめします。
というわけで、ComfyUI Managerを立ち上げて、Install Custom Nodesを起動し、検索窓からComfyUI Frame Interpolationと入力してカスタムノードをインストールします。
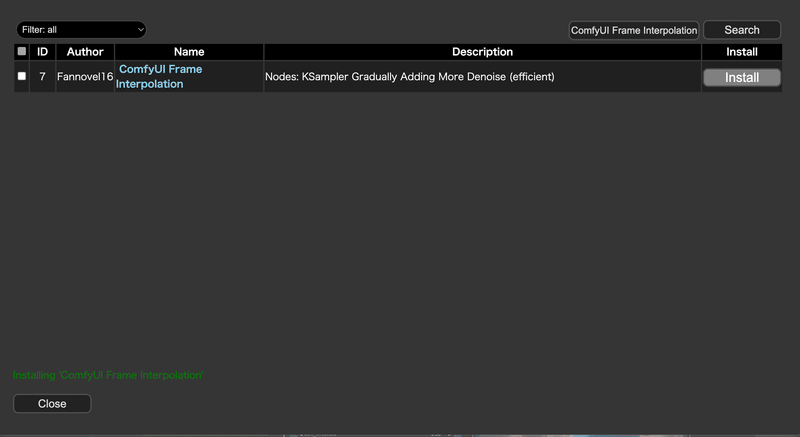
インストールが完了してアプリの再起動が完了したら、次は先ほどのワークフローを開いた状態で、右クリックを押して "RIF"と入力します。

するとRIFE VFIというのが出てくるのでこちらを選択します。
ちなみにこのRIFE VFIというのは、ビデオフレーム補間(Video Frame Interpolation、VFI)を行うためののカスタムノードとなります。
少し脇道にそれますが、ビデオフレーム補間とは既存のフレーム間に新しいフレームを生成し、ビデオのフレームレートを効果的に増加させる技術であり、動画生成AI界隈だと動画のヌルヌル化という表現でよく言われているような技術となります。
(フレームを補完させることにより、結果的に動画がなめらかに動くようになることから、こう呼ばれたりしています)
また、RIFEというのはReal-Time Intermediate Flow Estimationの略称でビデオフレーム補間(VFI)に使用されるアルゴリズムの一つとなり、このRIFEは特にリアルタイム処理に焦点を当てたアルゴリズムとなっています。
つまりこのRIFE VFIというのは入力として渡された動画のフレームを見て、フレーム補間処理を行い、その結果を出力してくれるノードとなります。

そして次はこのノードを使って、ノード間の接続を行っていきます。これぞComfyUIの醍醐味!
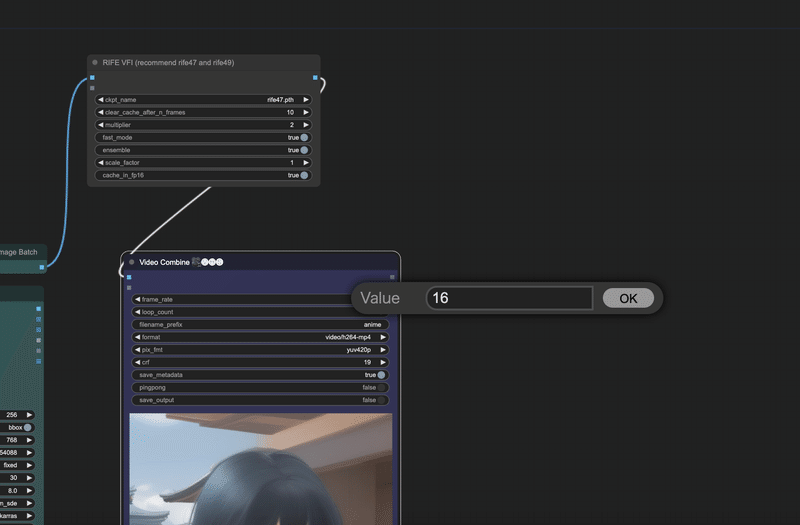
上の画像にあるImage List to Image Batchというノードのアウトプット先をVideo Combineから、先ほど追加したRIEF VFIノードの方につなぎ直します。
さらにRIFE VFIの出力をVideo Combineにつなぎ直します。

やっていることはVideo Combineの前にRIFE VFIを通すうようにしただけです。
そしてこれをすることによってRIFE VFIノード内でフレーム補間に関する処理を行うことができ、結果的に動画のヌルヌル化を実現できます。
最後にVideo CombineノードのFrame rateを16に変更しましょう。これでよりヌルヌル感が強調されます。
これで実行してみた結果がこちらです
こちらで公開されているワークフローにFrame Interpolationを足して、ヌルヌル動画を作成してみましたhttps://t.co/8AGGeey2XJ
— サファ【AIイラスト多め】 (@safa_dayo) January 23, 2024
既に公開されている素晴らしいワークフローに対して、ノードを追加して独自の処理を追加しやすい点はComfyUIの良いところですね#AI動画 pic.twitter.com/KpvcBrXJv3
そして実際に作成したワークフローファイルは以下となります。
もしうまく動かなかった方、実際にどんな動画は生成されるのかをまずは動かして試してみたい方は、ぜひこちらのワークフローをダウンロードして利用してみてください!
ポーズ制御からIP Adapter、アップスケールまでてんこ盛りの動画制作ワークフロー
次に紹介するのは、
ControlNet + DW Poseでのポーズ制御
IP Adapterでの特定のキャラの参照
AnimateDiffでの動画生成
生成した動画のアップスケール
Face Detailerの表情補正
などなど、動画を生成する際に欲しい機能が全て詰まったようなワークフローを紹介します。
といっても、ここにあるのものを一つ一つ紹介していったら記事の量が限界突破してしまうので、実際に作成された方のnoteの記事をじっくり読み込んでいただくことをオススメします。
最近では、以下の動画で利用しているワークフローも、元はこちらのワークフローをベースに改造させていただき利用させてもらっています。
上の動画内ではControlNet + DW Poseでのサンプル動画のポーズを抽出してAnimateDiffとして別の動画を生み出す処理や

生成した動画の表情を修正するためにFace Detailerを通すところなど、様々な部分でこちらのワークフローを取り入れさせていただいています。

様々な機能が詰まったワークフローであり、処理(ノード)の組み方の勉強にもなると思います。要チェックです!
ちなみにnote内で公開していただいているワークフローファイルを適用するとアップスケール処理なども動くような状態で入っています。
そのため、そのまま実行するとそれなりに時間が掛かる処理が動きます。
もしサクッと挙動を見てみるだけであれば、Upscale部分のノードだけでバイパスするように設定して試してみるのが良いと思います。
AnimateLCMを用いた高速AI動画生成ワークフロー
次に紹介するのは2024年3月に発表されたAnimateLCMを用いた、高速に動画生成を行うComfyUIワークフローとなります。
こちらについては以下の動画で実施している『FF7のティファさんを実写化して踊らせる』という試みの中で利用しています。
この動画内で試したセッティングの場合、ステップ数を8で生成することが可能です。
現在の技術ではSDXL Turboなどを始めとする高速化手法を用いることにより、最大で1ステップでの生成もできるようになっているので、8ステップと聞いてそこまでインパクトを感じない方もいるかもしれませんが、動画生成を行う場合、生成するフレームごとの画像数もそれなりに多いため、8ステップでもかなり高速化に寄与します 。
また私の場合、AnimateDiffで生成する際は基本的に顔が崩れないように、Face Detailerを挟みます
そのFaceDetailerでの生成フェーズでも、以下の画像のように8ステップで抑えられるため、動画生成にかける全体的な時間を考えるとかなりの高速化に繋がります。
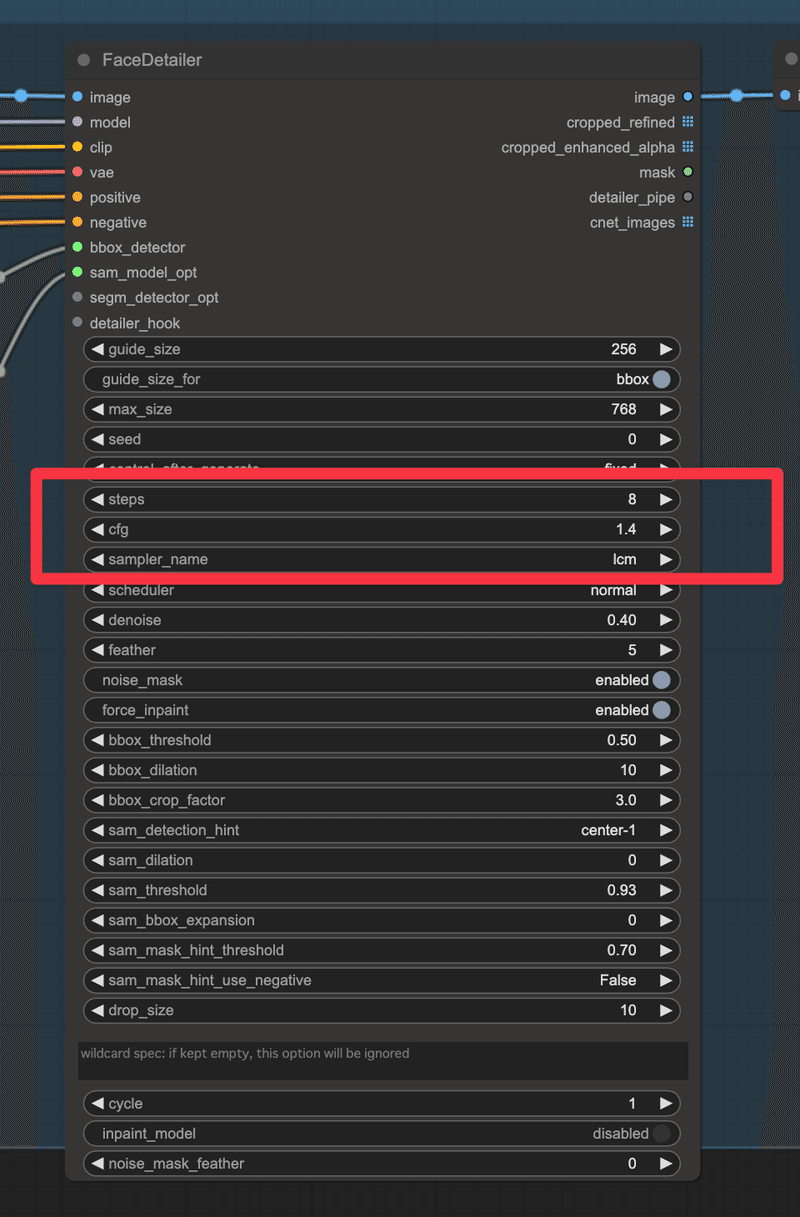
生成はご覧のように8ステップで実行しています
では、早速AnimateLCMを利用した動画生成フローについてご紹介していきます。
といっても、一つ一つ紹介していくと長くなってしまうので、まずは最初に利用しているワークフローファイルを共有します。
こちらのワークフローファイルは『ポーズ制御からIP Adapter、アップスケールまでてんこ盛りの動画制作ワークフロー』内で紹介した花笠さんのnote記事内のワークフローファイルをベースに一部をAnimateLCM用に改良させていただいたものです。
実際にこちらのワークフローを用いて生成したAI動画がこちらです。
(動画生成後にフレーム補間を追加で行っています)
おはようございます!
— サファ【AIイラスト多め】 (@safa_dayo) March 13, 2024
部屋着でダンスです😊 pic.twitter.com/rJj9gLImMj
ComfyUIにこちらのワークフローファイルを読み込ませることで、このようにAnimateLCMを用いた AI動画生成ワークフローを利用できます。
モーションモジュールや足りない拡張機能などは別途インストールが必要となりますが、何をインストールすべきかは後述するColabノートブックを参照していただければと思います。
ここからはAnimateLCMの設定についての話となります。
AnimateLCM用に具体的に改良したポイントは以下の4つです。
まずはAnimateLCMの設定のために、AnimateDiff LoaderにAnimateLCMのモーションモジュールを設定します。

bata_scheduleはlcm以外にも検討の余地がありそうでしたが、他のLCM系のスケジューラについても比較してみたところ、どれが最適かはいまいちはっきりしなかったため、今回はlcmにしています。
もしかしたらここは他を利用してみても良いかもしれません。

それぞれ試してみて生成したい雰囲気に近いものを採用するのも良いかもしれません
AnimateLCMのモーションモジュールは以下からダウンロードできますが、後述するGoogle Colab用のノートブックに書かれた記述(ダウンロードURL)を参考にしてみると分かりやすいかもしれません。
次にAnimateLCMのモーションモジュールを使うために、同じくAnimateLCM用のLoRAも利用する必要があるため、以下のようにLoRAを設定しています。

あとは画像生成に利用するKSamplerとFaceDetailerにAnimateLCMで利用するためのステップ数やCFGスケール、サンプラーを設定していくだけです。
サンプラーはlcmを利用しています。

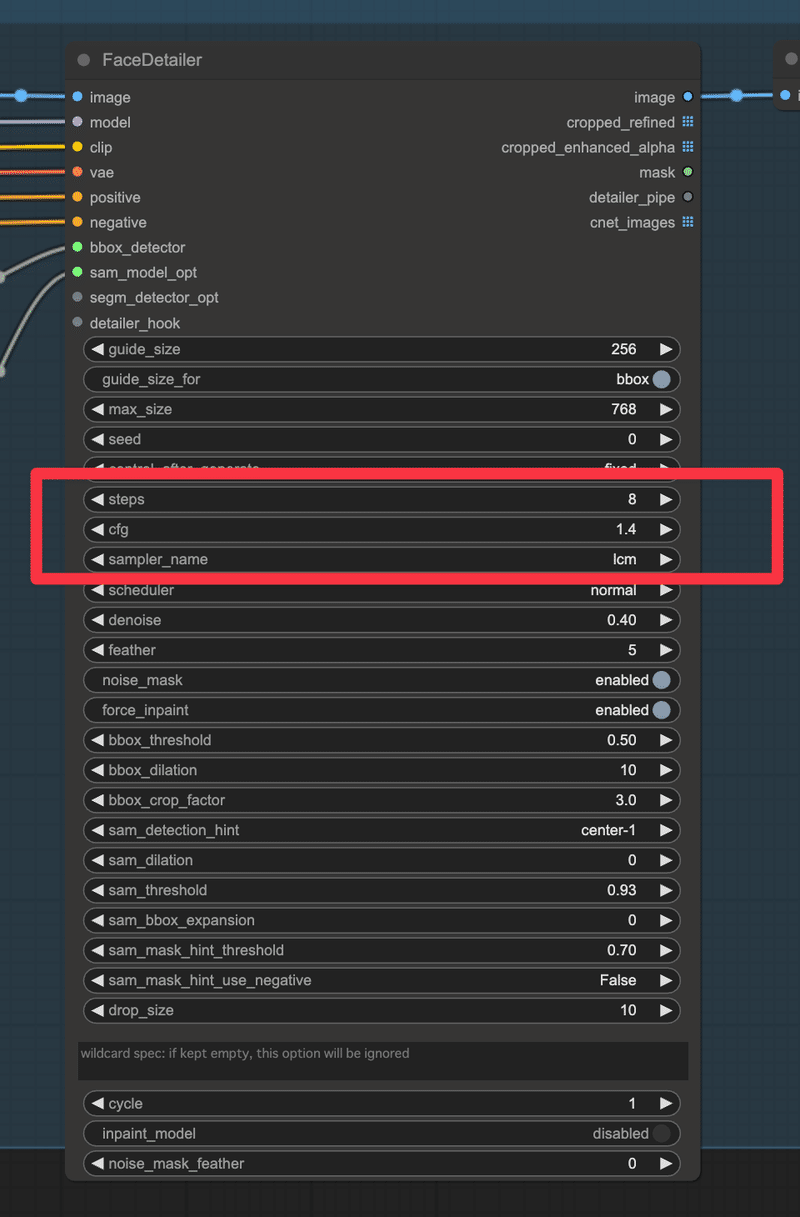
これで生成を行うと、この章の最初に示したYouTube動画内のティファさんのように高速生成ながらも、AnimateDiffによる動画生成がキッチリと行えます
なお、こちらのワークフローファイルは元となる動画をアップロードして利用することで、その動画通りの動きをしてくれるワークフローとなっています。
動画ファイルのアップロードなどについては実際にワークフローをご覧いただければ分かるかと思うのでここでは割愛します。
もし分かりにくかったらnoteやXなどでコメント下さい。
最後にこちらの内容をGoogle Colabで実行するためのノートブックのリンクも貼っておきます。
Windows環境で実行する場合も、こちらのノートブック内の記述を参照することで具体的にどういうライブラリを入れているのかは分かると思うので、参考にしてみてください。
https://gist.github.com/safa-dayo/b2393d648e4703c2c8ef28082952e176
上のColabノートブックを利用する際の注意点についてですが、
「### ここから別のコードセル」と書かれているところから以下を別のコードセルに分けて貼り付けるようにお願いします。
1つ目のコードセルを実行した際にランタイムを再起動する必要がある、というメッセージが表示されますが、無視して2つ目のコードセルを実行してもらって構いません
ぜひ試してみてもらえたらと思います。
ComfyUIでAnimateDiffとAnimateLCMとAnimateDiff Lightning環境をそれぞれ構築するためのColabノートブックを作成しました
作成したといっても、上の章で書いているGoogle Colabノートブックを更新して
AnimateDiff
AnimateLCM
AnimateDiff Lightning
それぞれを使い分けられるようにしたに過ぎません。
ColabノートブックのURL
https://gist.github.com/safa-dayo/b2393d648e4703c2c8ef28082952e176
しかしGoogle Colabを触っていると、毎回最初から環境構築する必要が関係上、それぞれの環境を簡単に使い分けられる仕組み(というほどでもないですが)が欲しかったので、今回作成しました。
使い方についてですが、上のColabノートブックをコピペすると画面右側に以下のようなチェックボックスが表示されるので、あとは利用したいAnimateDiff用のモデルにチェックをつけるだけです。

あとは実行すれば勝手に選択したモデルがダウンロードされ利用できる状態になります。
モデルはBellyUseがダウンロードされるようになっているので、ここは適宜利用したいモデルのURLに差し替えて利用していただけたらと思います。
AnimateLCMについては上の章に書いたワークフローを利用することで直ぐに利用を開始できます。
AnimateDiff Lightningについてはこちらのnoteに追記する予定ですので、しばしお待ちいただけたらと思います。
Stable Diffusion web UIとの違いを説明
実際にComfyUIを利用して動画生成を行ってきました。
ここまでくれば、もう皆さんは次はどういう画像や動画を作ろうかと考えを巡らせていたり、こんなワークフローを作ってみるのはどうだろう?と考えを巡らせているかもしれません。
というわけで、既にComfyUI入門を果たしている状態なのではないでしょうか?
さて、ここで記事を終わりにしても良いのですが、最後におまけパートとしてStable Diffusion web UIとの違いについて書いていこうと思います。
というのも、私もそうですが実際にComfyUIを触ってみて「Stable Diffusion web UIでやれるこの機能、ComfyUIでやるにはどうしたら良いんだろう?」と思うことが多々ありました。
そこでStable Diffusion web UIとComfyUIとの操作比較についていくつか書いていこうと思います。
内容としては初歩的なことが多いですが、触り始めたばかりの方には役立つかと思います。
EasyNegativeなどのembeddingsはどうやって使うの?
EasyNegativeなどのembeddingsはStable Diffusion web UIの場合、ネガティブプロンプト欄にEasyNegativeと書けばよかったのですが、ComfyUIの場合は
embedding:EasyNegative
と書きます。
また拡張子付きで
embedding:EasyNegative.safetensors
とも書けます。
強調したい場合は
(embedding:EasyNegative:1.2)
と書くと機能します
ComfyUIで生成した画像をStable Diffusion web UIやちちぷいなどにドラッグアンドドロップしてもプロンプトが反映されない…

ComfyUIで生成した画像はワークフロー形式でファイル内のPNG Infoに保存されています。
当然Stable Diffusion web UIでのPNG Info形式とは異なるため、生成した画像をStable Diffusion web UIや、『ちちぷい』の画像投稿画面にドラッグアンドドロップしても、プロンプトは表示されません
残念ながら現在は諦めるしかないですが、将来ここの不満を解消する仕組みが出てきたら嬉しいですね…!
Stable Diffusion web UIとComfyUIでは表示される画像が違う?
違います。
これは内部処理なども違うと思いますし、仕方ないのかもしれません。
実際に生成させてみた際の比較などは以下の投稿を参照してください。
スレッド内のこれに関する検証を実施
— サファ【AIイラスト多め】 (@safa_dayo) January 6, 2024
左がStable Diffusion webUI
右がComfyUI
結論:
ソフトウェアをまたいだ場合、異なる画像が生成されるhttps://t.co/bLEJSGYNV0 pic.twitter.com/UpcXWQXdMy
Stable Diffusion web UIのようにランダムなシード値で生成したい

上の画像の赤枠のように、KSamplerノードにあるcontrol_after_generateの項目をrandomizeにするとランダムなシード値で生成されるようになります
Stable Diffusion web UIのようにbatch countを設定したい
Stable Diffusion web UIでは以下のようにbatch countを設定することによって、一度に生成できる枚数を変更できます。
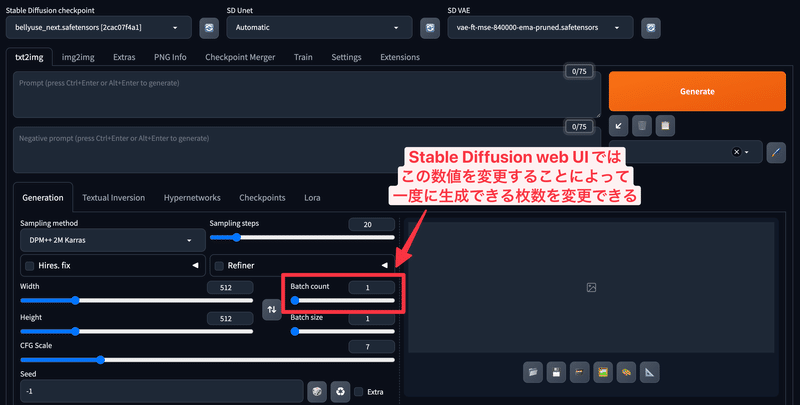
ComfyUIではQueue Promptの下にある、Extra Optionsというところにまずはチェックを入れます。
すると以下のようにBatch countの設定項目が出てくるので、底に直接数値を入れるか、下のスライダーを調整することでBatch count数を変更できます。
これにより、複数枚の一括生成が可能です。

Stable Diffusion web UIのGenerate forever機能はAuto Queueで実現できる
Stable Diffusion web UIでは生成を無限に繰り替えることができるGenerate foreverという機能があります。
こちらについては以前動画でも機能を紹介しているので、詳細はそちらを参照してみてください。
ComfyUIでは上に書いたBatch countと同様にExtra Optionsをチェックして表示されるAuto Queueというチェックボックスにチェックをつけると、無限に生成を繰り替えるAuto Queueモードになります。

さらにAuto Queueの下には
instant
change
という2つのラジオボタンですが、
instantの場合はAuto Queueを実行時点でのキューが0になり次第、新しいプロンプトがキューに入るようになります
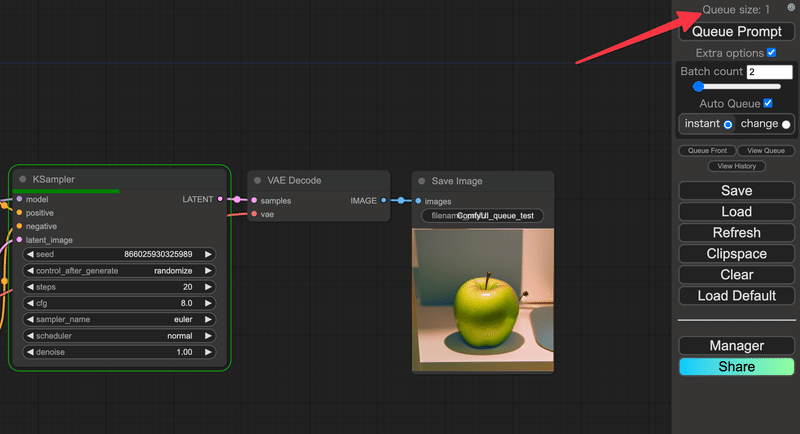
(Auto Queueモードを除く)
キューというのは、実行待ちの回数のようなもので、ここを見ることであと何回実行が行われるのかがわかるようになります。
※ただしAuto Queueモードの場合は、この数に関係なく実行は繰り返し行われるので要注意です。
つまりキューが2の状態で実行を行っている際に、プロンプトを変えると、その時点で入っているキューの回数である2階分が終了した、次のターンで変更したプロンプトが適用されることになります。
そしてchangeの場合はこれに加えて、グラフが変更されることが新しいプロンプトが適用される条件となります
…と公式のソースコードには記載されているのですが、実のところ、こちらの挙動はよく分かりません。
プロンプトが変更された時点で適用されているようにも見えるし、もうすこし検証してから、こちらは追記しています。
いずれにせよ、適用条件としてはinstantのほうがシンプルではあるので、最初はinstantにチェックを入れた状態で利用していくと良いでしょう。
ComfyUIでのLoRAの適用方法
Stable Diffusion web UIではLoRAはプロンプト欄に直接書けましたが、ComfyUIではLoRAを読み込むためのノードを設定する必要があります。
ノードの呼び出し方は、画面上のなにもないところでダブルクリックをして検索画面を呼び出し、loraと検索窓に入れれば出てくる Load LoRAというノードを利用します
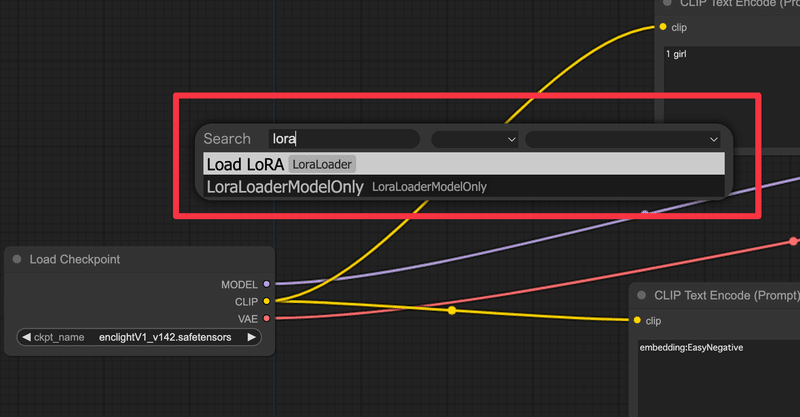
このLoRAに利用したいLoRAを設定し、Load Checkpointの後ろにつなぎます

これであとはプロンプト欄にトリガーワードなどを設定すればStable Diffusion web UIのようにLoRAを利用することが出来ます
ちなみに複数のLoRAを利用したい場合、このLoad LoRAを直列に並べて利用します。
以下のように設定することで複数のLoRAが利用できます
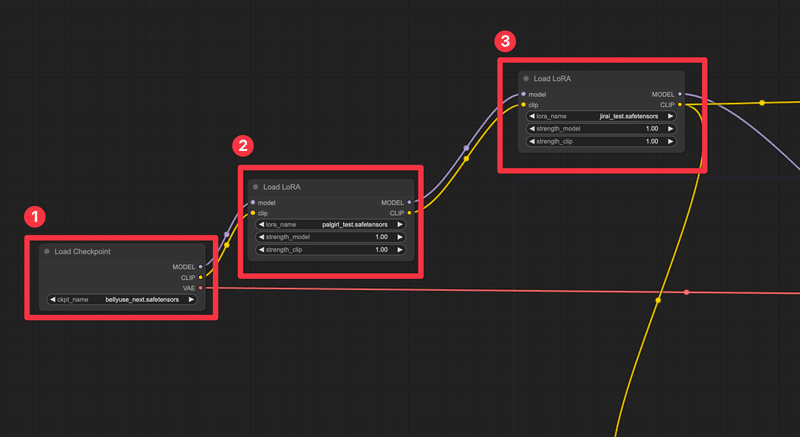
2と3がLoRAを呼び出しているLoad LoRAとなります
ちなみにLoad LoRAノードには
strength_model
strength_clip
という2つのパラメーターがあります。
これは最初のうちは単純にLoRA適用の強さと考えてしまって良いでしょう。

現時点では公開はしていません
このようにパラメーターが2つに分かれている理由ですが、CLIPモデルとメインで利用されるモデルに別々に適用されるLoRAの強さを制御するために存在しているようです。
ComfyUIで両方を調整できる理由は、LoRAのCLIPとMODEL/UNETの部分は異なる概念を学習している可能性が高いため、別々に調整することでより良い画像を得ることができるから、ということらしいですが、最初はあまり考えなくても良いかもしれません。
というか、私自身があまり理解できていません。今度調べてみます。
なお、この記述はComfyUIの以下のドキュメントに記載があります。
知っておくと便利なComfyUIテクニック
ここからはComfyUIを触る上で知っておくと便利なテクニックについてご紹介していきます。
ComfyUIは自由度の高い反面、Stable Diffusion web UIと比べると設定方法が非常に分かりにくいため、これからComfyUIを始める方の参考に少しでもこれらの文章がなっていけば幸いです。
保存時のファイル名の設定方法
ComfyUIではSave ImageノードやVideoCombineノード内にfilename_prefixという項目で、画像や動画生成時のファイル名を設定できます。

デフォルトでは上の画像のようにComfyUIとなっており、この場合はoutputフォルダ配下にComfy_00001という形で、末尾に5桁の数値が付く形で自動的にファイル名が設定されます。
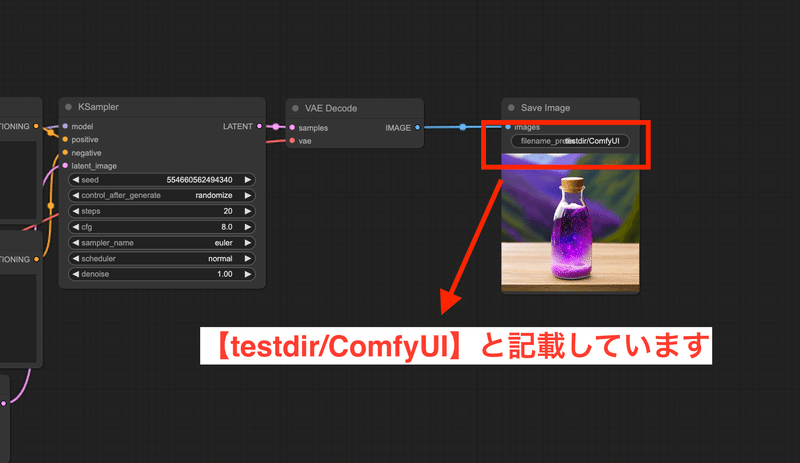
このfilename_prefixは例えばtestdir/Comfyとフォルダ名を設定することで、自動的にoutput配下にtestdirフォルダを作成し、その下にComfyUI_00001.pngというファイルを生成してくれます
(もちろんこの設定のまま2枚目の画像を生成した場合、ComfyUI_00002.pngというファイルが生成されることになります)

(画像はmacOS環境となります)
このようにフォルダ名も込みで直接指定できるのは便利ですが、これだけではありません。
ComfyUIでは以下のようなフォーマットでファイル名を設定することが出来ます。
(すべて網羅できている自信はありません。足りていない項目があればコメントいただけると嬉しいです!)
%date:FORMAT% - 生成日時を指定可能(フォーマットの指定は以下)
yy, yyyy - 年
MM, MMMM - 月
d, dd - 日
h, hh - 時
m, mm - 分
s, ss - 秒数
%width% - 画像横幅
%height% - 画像縦幅
そのため、例えば以下のようなfilename_prefixを設定した場合、
%date:yyyy-MM-dd%/ComfyUI_%width%_%height%以下のようなファイル名で画像が保存されます。

どんなfilename_prefixを設定すれば良いか分からない人はまずはこれを設定しよう
これは手元で画像生成している人あるあるですが、画像を生成しているとoutput配下が画像だらけになってしまいます。
そのため、基本的には日付単位でフォルダを分けるようにしています。例えば以下のような形です。
%date:yyyy-MM-dd%/ComfyUI%これは先ほども紹介した内容ではありますが、これを行うことで日付単位で自動的にフォルダが分けられますので、必須の設定と言っても良いでしょう。
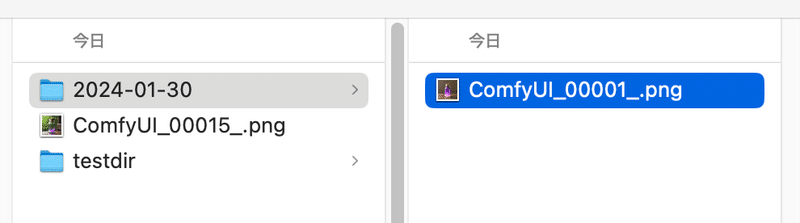
どんな設定をすればよいか分からない、という人は手始めにこの設定をしておくとファイルが散乱せずに管理がしやすいです
ComfyUI利用時に、個人的に必須なfilename_prefix設定
ただ、もっと様々なワークフローを組んでいると、生成した画像だけでなく、そこから作成された動画、Face Detailerを通した動画など一回の実行で複数画像が生成されるタイミングが出てきます。
そしてComfyUIではネストされた形でのフォルダ指定も可能です。
そのため、以下のようにすれば日付のフォルダの中に、複数の処理ごとにフォルダを分けて格納できるのでファイル整理がだいぶ楽になります。
%date:yyyy-MM-dd%/txt2img/ComfyUI
%date:yyyy-MM-dd%/animatediff/ComfyUI
%date:yyyy-MM-dd%/upscaled/ComfyUIこのようにComfyUIでは一度filename_prefixを設定してしまえば、あとは作成したフォルダ構成の中にファイルは生成されるようになっています。
最初は少しとっつきにくいですが、慣れれば楽に設定できるのでぜひ試してみてください!
この『2024年のComfyUI、完全入門』は引き続き更新していきます

さて、大変長々と書いてしまいましたが、この記事はここで終わりとなります。
しかしComfyUIの世界はかなり深く、私もまだまだ知識が足りていません。
今後、「こういうことも入門記事に書いておけばよかった…」と後悔することも必ず出てくると思うので、この記事は今後も必要な情報などを随時に追加していくスタイルで行こうと思います。
そのためこの記事のURLはぜひ覚えておいていただき、暇なときにふらっと立ち寄っていただけると幸いです。
(追加した内容はページ下部の更新履歴という箇所から確認できるようにしておきます)
また最初の方にも紹介させていただきましたが、私自身は画像・動画生成AIを中心としたテーマで日々YouTubeに動画を投稿しています。
今回のComfyUI以外にもStable Diffusion web UIやFooocusなどについても扱っていますし、TensorRTで画像生成を高速化する方法やLCMなど、最近流行りの高速化手法に関する内容なども発信しています。
もしよろしければこれらの動画もご覧いただけると嬉しいです。
まだまだ動画制作も修行中の身ですが、動画で見てみたいテーマなどもありましたらお気軽にコメントいただけたらと思います。
それでは、これで以上となります。
最後までお読みいただき、ありがとうございました!
更新履歴
記事作成(2024/1/23)
以下の章を追加(2024/2/3)
ポーズ制御からIP Adapter、アップスケールまでてんこ盛りの動画制作ワークフロー
Stable Diffusion web UIのようにbatch countを設定したい
Stable Diffusion web UIのGenerate forever機能はAuto Queueで実現できる
ComfyUIでのLoRAの適用方法
知っておくと便利なComfyUIテクニック
保存時のファイル名の設定方法
以下の章を追加(2024/3/13)
AnimateLCMを用いた高速AI動画生成ワークフロー
以下の章を追加(2024/3/29)
ComfyUIでAnimateDiffとAnimateLCMとAnimateDiff Lightning環境をそれぞれ構築するためのColabノートブックを作成しました
この記事が気に入ったらサポートをしてみませんか?