
Qosmo Mask 2022
Qosmoでは、2022年の新年のご挨拶として、昨年同様オリジナルのマスクをデザインしました。今年は、CLIPと画像生成モデルを使用してデザインを行いました。この記事では、そのデザインにおけるコンセプトや手法について記します。
Concept
改めまして「Stay safe with an AI-generated tiger mask, Best wishes for 2022!」


2022年の干支は寅年、QosmoはAI技術を用いてタイガー・テクスチャのマスクを制作しました。2021年のAIにおける先端的なトピック、テキストから画像を生成する手法:CLIPと画像生成モデルを採用しました。一見写真のように見えるテクスチャは実はAIによって生成されたタイガー・テクスチャです。
タイガー・テクスチャといえばイエロー+ブラックカラーが典型的ですが、Qosmoのアイデンティティであるネイビー・トーンにアレンジし日常的な着用に適したものになっています。
Technology
今年のQosmo Maskでは、CLIPと画像生成モデルを組み合わせて柄を生成しました。
CLIPは、OpenAIによって開発された画像とテキストの関連性を学習するモデルです。Webから大量の画像とテキストのペアデータ(約4億ペア)を取得し、そのペアを予測するように学習を行います。CLIPはContrastive Language–Image Pre-trainingの略称であり、学習ではContrastive Learningを用いている点が特徴です。このContrastive Learningでは、簡単に言えば似ているデータは似たベクトル表現に、異なる(=似ていない)データは異なるベクトル表現になるように学習を行います。この学習を経て、CLIPは画像とテキストを関連付けることができるようになります。

画像・テキストをベクトル化。その際、似たデータは似たベクトルに、異なるデータは異なるベクトルになるよう学習する(https://openai.com/blog/clip/より引用)
またCLIPでは、ゼロショット分類の精度を向上させることに重点を置いています。ここでのゼロショットとは、モデルが初めて見るデータに対してうまく機能することを指します。これまで、画像分類モデルは特定のデータセットを用いて特定のタスクに専念することで精度を向上させてきました。しかしこうした手法では、モデルは初めて見る(=データセットに含まれていない)データに対してはうまく機能しません。そこで近年では、学習データセットに含まれていない、新規のデータに対してうまく機能するモデルの研究が進められています。自然言語の領域においてはGPT-2、GPT-3がその汎用性で話題となりましたが、その汎用性を画像処理においても実現することを目指した手法がCLIPになります。
さて、このようにCLIPは画像とテキストを関連付けることが可能なうえ、ゼロショットにおいても高い精度を誇るモデルです。それでは、このCLIPを用いることで、アートの領域においてはどのような表現が可能になるでしょうか?
CLIPが登場して以降、アーティスト達によって様々な実験が行われました。特に多く見られたのが、CLIPと画像生成モデルを組み合わせることで入力テキストにマッチする画像を生成するような手法です。GANなどの画像生成モデルは、入力ベクトルを変化させることで、生成する画像をコントロールすることができます。また、上述したように、CLIPを使用することで画像・テキストをそれぞれ特徴量としてベクトル化し、その類似度を数値として計算することができます。これにより、画像生成モデルが生成した画像がテキスト入力とどの程度マッチしているかどうか、実際に計算することが可能になります。最初はランダムな入力ベクトルを用いて画像を生成し、CLIPを用いてその類似度を計算、その後は生成する画像がテキスト入力にマッチするように、勾配を計算し誤差逆伝搬法で入力ベクトルを最適化していきます。このプロセスを何度も繰り返すことで、入力テキストにマッチした入力ベクトルを見つけることが可能になり、この入力ベクトルを使用してマッチする画像を生成することができます。

CLIP + 画像生成モデルのシステム図(https://ml.berkeley.edu/blog/posts/clip-art/より引用)
この手法を用いて、多くのアーティスト達によって実験が行われています。”unreal engine”や”trending on ArtStation”というワードを入れることで生成する画像のクオリティが向上することが知られており、アーティストは様々な入力テキストを試すことでシステムと対話し画像を生成していきます。
CLIPと画像生成モデルを組み合わせたCLIPアートについては、以前弊社が運営するメディア、Create with AIでも紹介しています。併せてご覧ください。
Experiments
今年のQosmo Maskでは、これまで紹介してきたCLIPと画像生成モデルを組み合わせる手法を用いて柄を生成しました。画像生成モデルはVQ-GANやStyleGANなど様々なモデルが使用されていますが、今回はDiffusionモデルを使用しました。DiffusionモデルはGANとは異なり入力信号からノイズを取り除いていくことで徐々に高精度の画像を生成していくモデルであり、現時点ではGANよりも生成に時間はかかりますが、解像度の高い画像を生成することができます。以下、入力として使用したテキストとその生成結果です。
“Tiger texture, trending on ArtStation”



“dark blue tiger texture pattern, trending on ArtStation”


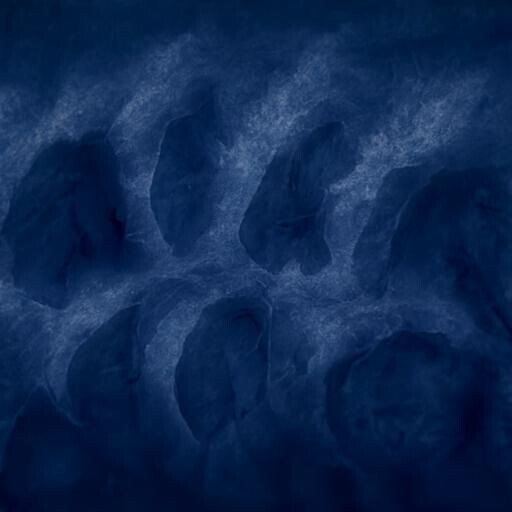
“animal stripe, trending on ArtStation”



“trending on ArtStation”というワードを入れることで、リアリスティックな画像を生成することができます。Art Stationとは、世界中のクリエイターがCG系の作品を公開しているサイトです。”trending on ArtStation”と入力することで、「Art Stationにおいて流行している」という意味になり、Art Stationの作品の傾向を生成する画像に反映することができます。また、”dark blue”というワードを入れることで、色を青色に限定することも可能です。このように様々な入力テキストを試しながら、柄のスタディを行っていきました。
ネイビー・トーンにアレンジすることは想定していたので、テクスチャ自体がタイガーらしいものを求めていました。そしてスタディの中から“Tiger texture, trending on ArtStation”の三点を選びました。
まずオリジナルを入れてみました。



カラーをダークブルー系に。



普段でも着けられそうなマスクになってきました。
この中から選択したテクスチャをベースに、Qosmoのネイビーカラーに調整をし完成となりました。

このようにして、2022年のQosmo Maskを制作しました。このMaskを着けて、皆様が2022年も健康に過ごすことができるよう願っております。
この記事が気に入ったらサポートをしてみませんか?