Gasで【部分一致データ】の抽出プログラムを作ってみた

Google Apps Script(gas)を学習し、初めて自分でツールを考え作成してみました。
作成した「部分一致データ」の抽出プログラムの主なニーズは以下の2点です。
・特定キーワードの部分一致データを集計したい。
・漢字、ひらがな、カタカナ、ローマ字(大文字小文字)、英語や表記揺れを気にせず、簡単な操作で自動集計したい。
プログラムで実現できること
・部分一致した行を自動で一括抽出してくれる
具体的には、部分一致キーワードを設定して実行することで、集計元データの特定列データと照合していき、部分一致した行を自動で一括抽出してくれます。
・表記方法、表記揺れに気を遣わずに集計できる
こちらは「設定したキーワード」と「集計元データの特定列データ」に対して、プログラムが自動で整形してくれます。(空白処理や漢字、ひらがな、カタカナをローマ字に変換することで同一表記で照合できるようになります。)
プログラムの実行例
【元データ】

【設定した部分一致キーワード】
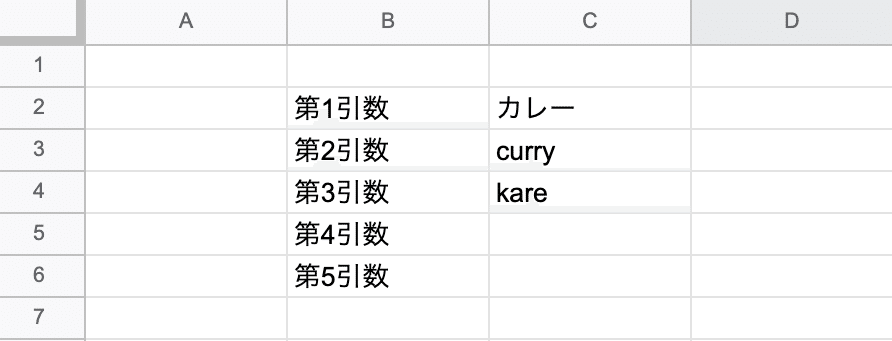
【出力結果】

プログラムの実行手順

部分一致の照合は、キーワードをローマ字変換することで解決しました。
ひらがな、カタカナ、漢字と様々な表記であっても最終的にローマ字に変換することで、照合ができるようになります。
ただし、注意点もあるため後に解説します。
①集計元データを用意する。
②部分一致データ抽出用のキーワードを設定する。(設定キーワードは複数指定可)
※元データに英語キーワードが含まれる場合は、複数抽出用のキーワードを設定しなければならないケースあります。
※1:外国語の表記も抽出したいケース
例)りんご、apple
→設定キーワード:「りんご」「apple」
※2:日本語をローマ字変換した際に不一致が発生するケース
例)格安しむ→shimu、格安sim
→設定キーワード:「格安しむ」「格安sim」
※3:「漢字→ひらがな」変換時に意図しない変換結果になるケース
今回のプログラムはローマ字変換することで照合しています。もし、「漢字→ひらがな」変換時に意図しない変換が起こると、元データ内に存在する”ひらがな”、”カタカナ”表記と照合できなくなります。
例)1月→「1がつ」or「1つき」
こちらは、今回使用するgooのひらがな化APIによるため、テスト的に「漢字→ひらがな」変換をして試すしかありません。
意図しない変換結果だった場合は抽出用キーワードを以下のように2つ設定します。
→設定キーワード:「漢字表記」、「ひらがな表記」
③プログラムを実行する。
④「出力用シート」に反映される。
プログラムの処理の概要
以下、部分一致データ抽出用のキーワードを「照合キー」とする。
【関数の概要】
・main.gas:「照合キー」と部分一致した行を「出力シート」に出力。
- partialMatch.gas:「照合キー」と部分一致した行を返す。
- strConversion:(漢字、ひらがな、全角カタカナ)をローマ字変換。
- kanjiToKana:漢字→ひらがな変換。※gooのひらがな化APIを使用。
- kanaToRoman:ひらがな、全角カタカナ→ローマ字変換 ※半角カタカナを除く。
※活用させて頂いたコード
「ひらがなまたはカタカナからローマ字へ変換」
-replaceFullToHalf
※活用させて頂いたコード
JavaScriptで全角⇔半角の変換をサンプルコード付き解説!
【作成プログラム】
main.gas:「照合キー」と部分一致した行を「出力シート」に出力。
function main() {
//処理速度の測定開始
const label = 'main() time'
console.time(label);
// 現在開いているスプレッドシートを取得
const ss = SpreadsheetApp.getActiveSpreadsheet();
// 照合キーを取得して、一次元配列に変換
const inputData = ss.getSheetByName('照合キー設定用');
const query = inputData
.getRange(2,3,inputData.getLastRow()-1)
.getValues().flat();
// 集計元データの取得
const values = ss.getSheetByName('データ').getDataRange().getValues(); //「データ」シートのセル内容を取得する
const header = values.shift(); //一行目の見出し行を格納
// 照合キーに対して、文字変換処理&空白削除、大文字を小文字に変換
for(let i=0; i<query.length; i++){
query[i] = strConversion(query[i]).replace(/\s+/g, "").toLowerCase();
}
// 部分一致判定の関数を実行
let target =partialMatch(values,query);
target.unshift(header); //見出しを追加
// 部分一致データを出力
if(target.length !=0){
const extraction = ss.getSheetByName('出力');
extraction
.getRange(2,2,target.length,target[0].length)
.setValues(target);
}
//処理速度の測定終了
console.timeEnd(label);
}partialMatch.gas:「照合キー」と部分一致した行を返す関数。
function partialMatch(array,query) {
const queryList = query.filter(e => e); //照合キーのうち、空白要素を削除して配列に格納
// 部分一致した行を配列で返す
return array.filter(record => {
const currentRecord = record; //表の行を上から順に抽出
keyword = strConversion(currentRecord[2]).replace(/\s+/g, "").toLowerCase(); //表内の対象キーワードに対して、文字列処理&空白削除、大文字を小文字に変換
// 照合キーと対象キーワードとの部分一致を判定
for(let i =0; i<queryList.length; i++){
if(keyword.indexOf(queryList[i]) !== -1){
return queryList[i];
}
}
});
};strConversion:(漢字、ひらがな、全角カタカナ)をローマ字変換する関数。
function strConversion(str) {
let newStr = str;
let regexp = /[\u4E00-\u9FFF]/; //漢字の正規表現
// 漢字が含まれている場合
if(regexp.test(newStr)){
newStr = kanjiToKana(str); //漢字→ひらがな変換
}
newStr = kanaToRoman(newStr); //ひらがな、カタカナ(全角)→ローマ字変換
newStr = replaceFullToHalf(newStr); //全角→半角変換
return newStr;
}kanjiToKana:漢字をひらがな変換する関数。※gooのひらがな化APIを使用。
function kanjiToKana(kanji) {
//APIのリクエストでPOSTデータするパラメーターを設定する
let payload = {
'app_id': 'ID名を入力する', //ID名を入力する必要あり
'sentence': kanji,
'output_type': 'hiragana',
};
//HTTP POSTで前述で設定したパラメーターをオプションで設定する。
let options = {
'method' : 'post',
'payload' : payload
};
let response = UrlFetchApp.fetch('https://labs.goo.ne.jp/api/hiragana', options);
let json = JSON.parse(response);
return json['converted'].replace(/\s+/g, ""); //空白を削除
}仕様や注意点
【APIの仕様や注意点】
・gooのひらがな化APIの仕様
「漢字→ひらがな」変換時に、APIの仕様により、変換した文字と次の文字の間に空白が入る。そのため、変換後に空白処理を行う必要がある。
※作成したプログラムでは空白処理を施しています。
例)
変換前:「今日は良い天気です!」
変換後:「きょうは よい てんきです!」
・gooのAPIの提供が終了した場合に使えなくなる
gooのひらがな化APIを活用させて頂いているため、サービス提供が終了したら今回のプログラムも動かなくなってしまいます。
gooラボの利用規約
kintone(キントーン)さんのブログで、ひらがな化APIを活用しないケースについて詳しく書かれているため、気になる方は是非チェックしてみてください。
「いかにしてカスタマイズの方法を選ぶか 〜 ふりがなを自動的に補完するカスタマイズの時の技術選択」
【gasの仕様や注意点】
gasの仕様による制限gasは1日あたりのURLFetch回数や実行あたりのデータ受信量について制限があります。また、gmail.comあるいはG Suite無料版(廃止)アカウントとGoogleWorkspaceアカウントで制限も変わってきます。
制限については更新される可能性があるので、公式サイトで最新版をご確認ください。
Googleサービスの割り当て
・URLFetch のデータの送受信 (50MB/1回のpost・response)
1MB = 1,024(1KB)×1,024=約100万バイト。
1MBは、日本語1文字3バイトで約33万文字。
50MBを日本語データ量に換算すると約1,500万文字ということになります。
1キーワードを10文字とした場合、受信できるデータはpostあたり150万未満のキーワード数になります。※データ受信=文字のみとして計算した場合。
ただし今回の場合、gooのAPI側にもリクエストのデータ量に制限があるため、gasとAPIの両方でデータ制限があると認識しておく必要があります。
・URLFetch の呼び出し(20,000 個/日)
「漢字→日本語」変換をするには、URLFetchを利用してgooのAPIと通信する必要があります。
つまり、変換できるキーワード数は1日20,000個までということになります。
1日に複数の集計元データに対して、部分一致集計したい場合には20,000という上限を超えてしまう懸念があります。
【1日20,000キーワード以上を変換するための対応策】
ざっくり説明すると、漢字を含むキーワードに対して、都度URLFetchするのではなく、漢字を含むキーワードを結合して1つの文字列にします。
そして、その文字列をURLFetchすることで、1回のURLFetchで「漢字→ひらがな」変換を完了させる。という流れです。
①漢字を含むキーワードをカンマで区切って結合し、1つの文字列にする。
②URLFetchを一度実行して、「漢字→ひらがな」変換する。
③カンマ区切りで配列に変換して、元データを変換後の文字列に書き換える。
④更新された元データと照合キーで部分一致集計をする。
ちなみに、URLFetch回数を削減する方法として、配列を渡たすことを試みましたが実行不可でした。
コードは以下になります。
元データ内にある漢字データをひらがなに変換して、元データのコピーを作成する関数。
function main2() {
// 処理速度の測定開始
const label = 'main2() time'
console.time(label);
// 現在開いているスプレッドシートを取得
const ss = SpreadsheetApp.getActiveSpreadsheet();
// 元のデータから「漢字→ひらがな」変換したい列データを取得
const sheet =ss.getSheetByName('データ');
const data = sheet.getRange(1,4,sheet.getLastRow());
let values = data.getValues().flat(); //「漢字→ひらがな」変換したい列データを一次元配列に変換
const header = values.shift(); //一行目の見出し行を格納
// 「漢字→ひらがな」変換したい列データをコピーする
let targetArray = [];
for(let i =0; i<values.length; i++){
targetArray.push(values[i]);
}
targetArray = kanjiExtract(targetArray); // 漢字が含まれているキーワードを配列に格納
newStr = targetArray.join(); //「配列→文字列」変換
targetArray = kanjiToKana(newStr).split(','); //「漢字→ひらがな」変換後に、「文字列→配列」変換
let regexp2 = /[\u4E00-\u9FFF]/i;
// 元データについて漢字が含まれている場合は、今回変換したデータを代入
for(let i =0;i<values.length; i++ ){
if(regexp2.test(values[i])){
values[i]=targetArray.shift();
}
}
// 1次元配列をn行1列の2次元配列に変換
let values2D =[];
for(i=0;i<values.length;i++){
values2D[i]=[values[i]];
}
// 元データをコピーして、「漢字→ひらがな」変換バージョンのデータにする
let copyss= ss.getSheetByName('データ').copyTo(ss);
copyss
.getRange(2,4,values.length)
.setValues(values2D);
//処理速度の測定終了
console.timeEnd(label);
}漢字が含まれている配列を返す関数。
function kanjiExtract(array) {
const regexp = /[\u4E00-\u9FFF]/i;
let kanjiArray =[];
//漢字が含まれている場合
for(let i =0;i<array.length; i++ ){
if(regexp.test(array[i])){
kanjiArray.push(array[i]);
}
}
return kanjiArray;
};※リクエストサイズの制限(goo側)
gooのひらがな化APIではリクエストサイズ制限が設けられているため、大量の文字列を連結して送信するとエラーになります。
公式サイトで具体的なデータ量は明記されていないものの、制限が掛からないように「実行データ数を減らしてデータ量を削減する」、「1度にリクエストするのではなく分割して、リクエストあたりのデータ量を減らす」などの配慮は必要になります。
「gooラボAPIは実験サービスのため、1日に大量アクセスがあった場合やリクエストサイズが大きい場合に対して制限がかかることがございます。レスポンスが正常に戻らない場合には、リクエスト内容の確認に加えリクエストサイズの削減などをご検討ください。」
gooラボAPI利用方法
例えば、試験的に1キーワード6文字程で5,000行分を連結してリクエストしたら実行エラーになりました。
ちなみに1,000行分で試した所、処理ができました。以下にその際の処理時間も参考として記しておきました。
検証内容と結果
・集計元データを1,000行用意して、1,000キーワード(1キーワード6文字ほど)に対して「漢字→ひらがな」変換を施し、集計元データを更新した際の処理時間は2,209ms。
・また、上記の更新データに対する部分一致データ集計処理には2,152ms掛かりました。
・上記より1,000行(1キーワード6文字ほど)に対して部分一致集計するのに掛かる時間は、約4秒という結果になりました。
gasは一度のスクリプトの実行時間に6分間という制限が設けられていますが、処理速度的に実用面で問題はなさそうですね。
以上が部分一致データの抽出プログラムでした!
最後までお読み下さりありがとうございました!!
この記事が気に入ったらサポートをしてみませんか?