
RAGに関する主要な論文を時系列順にまとめていく(2024年度版)

RAGに関する主要な論文まとめていきます。(過去の分含めて随時更新予定)
見つけたものからまとめているので、最新の2024年以降の論文多めです。
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(22/05/2022)
一言紹介
❓ LLMって、事前学習された知識に関しては答えてくれるけど、最新のニュースだったり、専門的な情報や組織固有の情報には対応できないよなぁ
💡 外部知識をLLMに検索させよう!→RAGの誕生
Abstract日本語訳
大規模な事前学習済み言語モデルは、そのパラメータに事実知識を蓄積し、下流の自然言語処理(NLP)タスクに微調整されたときに最先端の成果を達成することが示されています。しかし、知識をアクセスして正確に操作する能力は依然として限られており、知識集約型タスクでは、タスク固有のアーキテクチャに比べてパフォーマンスが劣ります。さらに、彼らの決定の根拠を提供し、その世界知識を更新することは、未解決の研究課題です。事前学習済みモデルに明示的な非パラメトリックメモリへの微分可能なアクセスメカニズムを備えることでこの問題を克服できますが、これまでのところ抽出的な下流タスクでしか調査されていません。
私たちは、事前学習済みパラメトリックおよび非パラメトリックメモリを言語生成に組み合わせた、検索強化生成(RAG)のための汎用的な微調整レシピを探ります。私たちは、パラメトリックメモリとして事前学習済みのseq2seqモデルを使用し、非パラメトリックメモリとして事前学習済みのニューラルリトリーバーでアクセスされるWikipediaの密ベクトルインデックスを使用するRAGモデルを紹介します。生成されるシーケンス全体で同じ検索パッセージを条件とするものと、トークンごとに異なるパッセージを使用できるものの2つのRAGフォーミュレーションを比較します。
私たちは、広範な知識集約型NLPタスクでモデルを微調整および評価し、3つのオープンドメインQAタスクで最先端の成果を達成し、パラメトリックseq2seqモデルおよびタスク固有の検索抽出アーキテクチャを上回る結果を示しました。言語生成タスクにおいて、RAGモデルは、最先端のパラメトリックのみのseq2seqベースラインよりも、より具体的で多様かつ事実に基づいた言語を生成することがわかりました。
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection(17/10/2023)
一言紹介
❓ 通常のRAGだと検索する必要がない質問だったり外部知識の質が低かったら逆に性能が下がるよなぁ
💡"質問の回答にRAGが必要かどうかの判断"と"外部知識を元にLLMが生成した回答が正しいかどうか"をチェックしてから回答するようにしよう!
→Self-RAGの誕生
Abstract日本語訳
大規模言語モデル(LLM)は、その優れた能力にもかかわらず、内部に含まれるパラメトリック知識のみに依存するため、事実誤認を含む応答を生成することがよくあります。Retrieval-Augmented Generation(RAG)は、関連知識の検索を通じてLMを強化する即席のアプローチであり、このような問題を軽減します。しかし、検索が必要かどうかや、検索されたパッセージが関連しているかどうかに関係なく、一定数の検索されたパッセージを無差別に取り込むことは、LMの柔軟性を低下させたり、有益でない応答を生成したりすることにつながります。私たちは、自己反省を通じてLMの質と事実性を向上させる新しいフレームワーク「Self-Reflective Retrieval-Augmented Generation(Self-RAG)」を紹介します。このフレームワークは、オンデマンドでパッセージを適応的に検索し、特別なトークン(リフレクショントークン)を使用して検索されたパッセージと自身の生成物を生成および反省する単一の任意のLMを訓練します。リフレクショントークンを生成することで、推論フェーズ中にLMを制御できるようになり、多様なタスク要件に合わせてその挙動を調整することができます。実験により、Self-RAG(7Bおよび13Bパラメーター)は、多様なタスクにおいて最新のLLMや検索強化モデルを大幅に上回ることが示されました。具体的には、Self-RAGはオープンドメインQA、推論、および事実確認タスクにおいてChatGPTや検索強化Llama2-chatを上回り、これらのモデルに対して長文生成における事実性および引用の正確性を大幅に向上させる成果を示しています。
処理の流れ
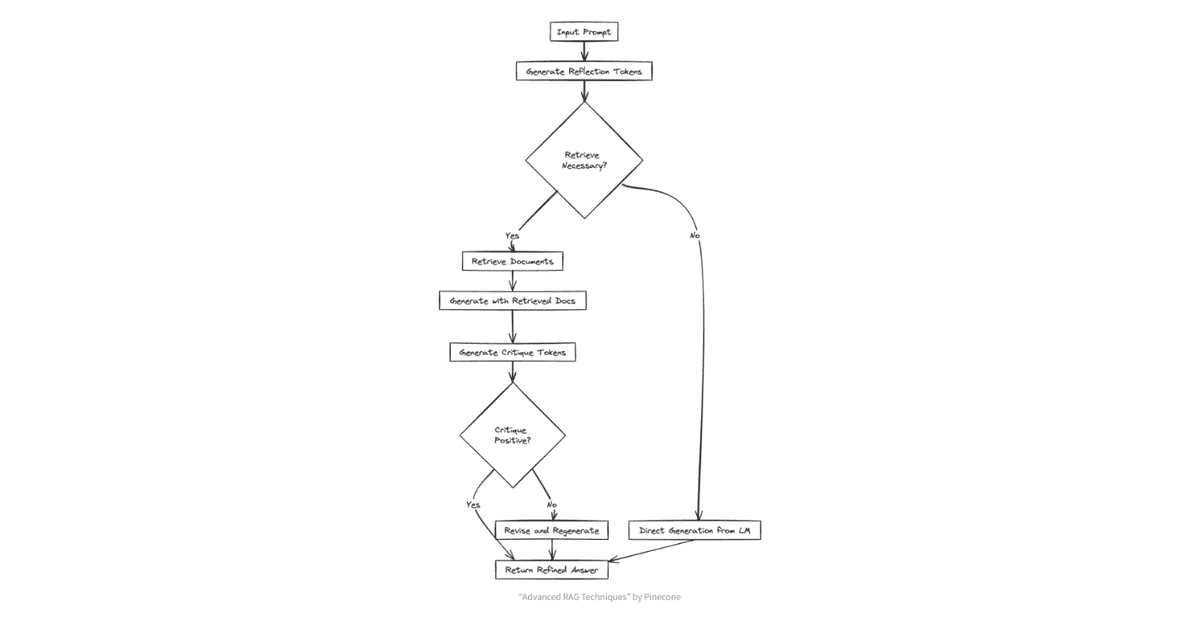
【事前準備】LLMをファインチューニングし文章の生成の途中でreflection tokenを混ぜ込めるようにする
Self-RAGでは、独自にファインチューニングしたモデルを生成に利用ユーザーの質問に対し、まず検索の要否を自己判断
不要と判断した場合は文書検索はせず、独自の知識だけで回答を生成します。以下、検索した場合を説明検索で取得した複数の文書を基に、それぞれ回答生成
それぞれのドキュメント1つずつ+元の質問をもとに、LLMが複数の回答を生成回答を評価、最も良い応答を選択
生成された複数の回答について、質問にして関係あるか、証拠になるか、有用かどうかを判断し、最もスコアの高い回答を採用
Source Code
参考
Retrieval-Augmented Generation for Large Language Models: A Survey(18/12/2023)
一言紹介
❓2023年はRAGの論文とか色々出てきて、ややこしいからまとめたった
💡まとめるとこんな感じ
■RAGとは
① LLMが事前学習データに加えて外部のデータを取り入れて動くようにするための技術
② 社内データを参照させる際などにも使用される
③ プロンプトやファインチューニングと並ぶ選択肢
■構成要素
① リトリーバー(Retriever): 大規模なデータベースから、クエリに基づいて最も関連性の高い情報を見つけ出す役割を持つ
② ジェネレーター(Generator): リトリーバーから提供された情報を基にして、自然言語の回答やテキストを生成する
③ 拡張(Augmentation): リトリーバーとジェネレーターに追加的な情報や機能を提供する手段。(検索アルゴリズムの改善など)
■RAGの評価
① 正確性、情報更新速度、透明性などが主要な指標
② RAGASやARESなどの自動評価手法がある
■今後の発展
① さらなる最適化が必要
② 応用範囲の拡大が期待される
③ 技術スタックとエコシステムが発展すべき
Abstract日本語訳
大規模言語モデル(LLM)は優れた能力を示していますが、幻覚(誤った情報の生成)、古い知識、および透明で追跡可能な推論プロセスの欠如といった課題に直面しています。Retrieval-Augmented Generation(RAG)は、外部データベースから知識を取り込むことで有望な解決策として浮上しています。これにより、特に知識集約型タスクにおいて生成の正確性と信頼性が向上し、継続的な知識の更新やドメイン固有の情報の統合が可能になります。RAGは、LLMの内在的な知識と外部データベースの広大で動的なリポジトリを相乗的に統合します。
この包括的なレビュー論文では、Naive RAG、Advanced RAG、およびModular RAGを含むRAGパラダイムの進展を詳細に検討します。RAGフレームワークの三つの基盤である、検索、生成、および拡張技術について細かく精査します。この論文では、これらの重要なコンポーネントに埋め込まれた最先端技術を強調し、RAGシステムの進歩に対する深い理解を提供します。
さらに、本論文では最新の評価フレームワークとベンチマークを紹介します。最後に、現在直面している課題を概説し、研究と開発の将来の方向性を指摘します。
Seven Failure Points When Engineering a Retrieval Augmented Generation System(11/01/2024)
一言紹介
❓RAGがうまくいかない要因は何なんだろうか?
💡RAGの失敗パターンは以下の7種類に分類できるよ
(1)データ不足
(2)検索漏れ
(3)コンテキスト化の失敗
(4)プロンプト処理の失敗
(5)フォーマットの不一致 (6)具体性の欠如
(7)回答の不完全さ
Abstract日本語訳
ソフトウェアエンジニアは、Retrieval Augmented Generation(RAG)という戦略を使用して、アプリケーションにセマンティック検索機能を追加することが増えています。RAGシステムは、クエリとセマンティックに一致する文書を見つけ、それをChatGPTのような大規模言語モデル(LLM)に渡して正しい回答を抽出するというものです。RAGシステムの目的は、a) LLMからの幻覚応答の問題を減らす、b) 生成された応答にソースや参考文献をリンクする、c) 文書にメタデータを付与する必要をなくすことです。しかし、RAGシステムは情報検索システムに固有の制限やLLMへの依存から生じる制約に苦しんでいます。
本論文では、研究、教育、バイオメディカルの3つの分野のケーススタディから得られたRAGシステムの失敗点に関する経験報告を紹介します。得られた教訓を共有し、RAGシステムを設計する際に考慮すべき7つの失敗点を提示します。我々の作業から得られた2つの重要なポイントは、1) RAGシステムの検証は運用中にのみ実行可能であること、2) RAGシステムの堅牢性は設計時ではなく運用中に進化するということです。最後に、ソフトウェアエンジニアリングコミュニティのためのRAGシステムに関する潜在的な研究方向をリストアップして締めくくります。
The Power of Noise: Redefining Retrieval for RAG Systems(26/01/2024)
一言紹介
❓RAGではコンテキストとしてタスクと関係のある情報を渡すのが普通だけど、あえて無関係な文書も「ノイズ」として渡したらどうなるんだろう??
💡なんと”タスクと無関係な情報”がコンテキストに混ざったほうがLLMの出力精度が上がることがあることがわかったよ!!
→プロンプトにランダムな文書を追加すると、LLMの正確性が最大35%向上することがわかった
Abstract日本語訳
Retrieval-Augmented Generation(RAG)は、情報検索(IR)システムによって取得された関連するパッセージや文書を使用して、元のプロンプトを拡張することで、大規模言語モデル(LLM)の事前学習された知識を超えるための方法として最近登場しました。RAGは、特にエンタープライズ環境や知識が絶えず更新され、LLMに記憶させることができないドメインにおいて、生成型AIソリューションにとってますます重要になっています。ここでは、RAGシステムの検索コンポーネント(密または疎にかかわらず)が研究コミュニティからの注目を増すべきであると主張し、RAGシステムの検索戦略について初の包括的かつ体系的な検討を行います。特に、RAGソリューション内のIRシステムが取得すべきパッセージの種類に焦点を当てます。
我々の分析は、プロンプトコンテキストに含まれるパッセージの関連性、その位置、および数など、複数の要因を考慮しています。本研究の一つの逆説的な発見は、クエリに直接関連しない(例えば、回答を含まない)検索者の最高得点の文書がLLMの有効性に悪影響を与えることです。さらに驚くべきことに、プロンプトにランダムな文書を追加すると、LLMの正確性が最大35%向上することがわかりました。これらの結果は、LLMと検索を統合する際の適切な戦略を調査する必要性を強調しており、この分野の今後の研究の基盤を築くものです。
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries(27/01/2024)
一言紹介
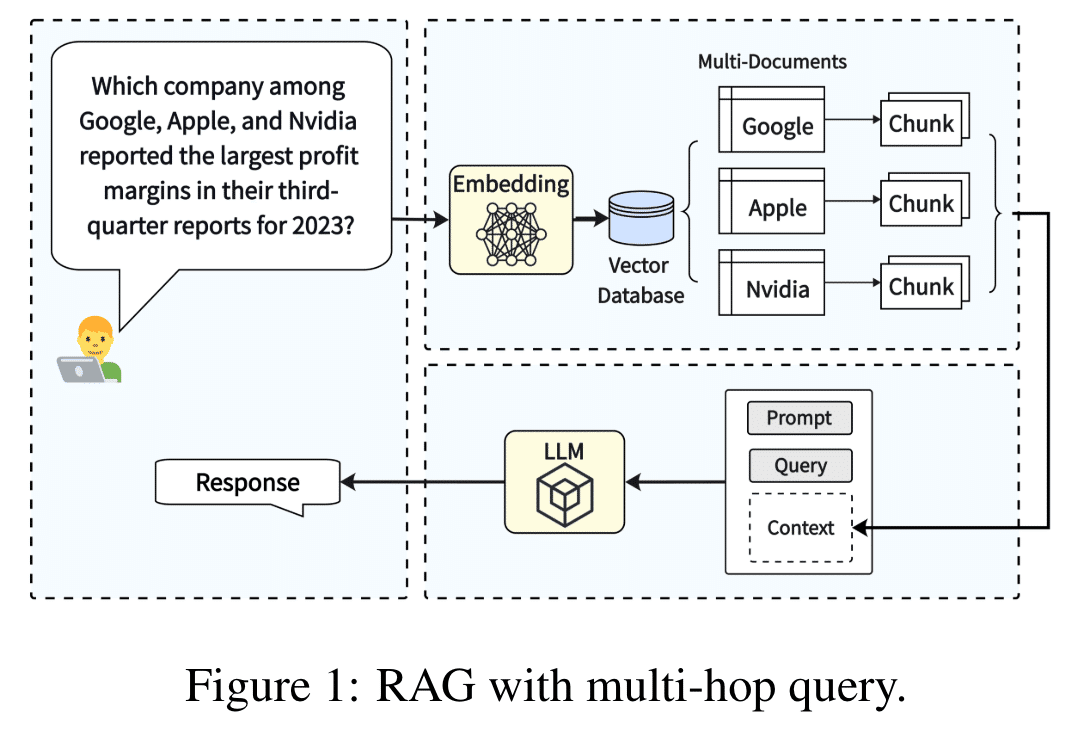
❓ マルチホップクエリ(複数のソースにまたがる情報源もしくは複数のステップを経て情報を取得すること)を検索して質問に回答するようなシチュエーションだとRAGの性能下がるよな?
💡 検証して既存のRAGシステムでは性能が下がっていることを発見しました!
Abstract日本語訳
Retrieval-augmented generation(RAG)は、関連知識を検索することで大規模言語モデル(LLM)を強化し、LLMの幻覚を軽減し応答の質を向上させる有望な可能性を示しています。これにより、LLMの実際の利用が促進されます。しかし、既存のRAGシステムは複数の支持証拠を検索して推論する必要があるマルチホップクエリの回答に不十分です。さらに、私たちの知る限り、マルチホップクエリに焦点を当てたRAGのベンチマークデータセットは存在しません。本論文では、知識ベース、マルチホップクエリの大規模コレクション、その正解、および関連する支持証拠から成る新しいデータセット「MultiHop-RAG」を開発しました。このデータセットの構築手順を詳述し、英語のニュース記事データセットを基礎となるRAG知識ベースとして利用しました。
2つの実験でMultiHop-RAGのベンチマークユーティリティを示します。最初の実験では、マルチホップクエリの証拠を検索するための異なる埋め込みモデルを比較します。2番目の実験では、GPT-4、PaLM、およびLlama2-70Bなどの最新のLLMが、証拠を与えられた状態でマルチホップクエリに対する推論と回答能力を検証します。両方の実験は、既存のRAG手法がマルチホップクエリの検索と回答において満足のいく結果を出せないことを示しています。
私たちは、MultiHop-RAGが効果的なRAGシステムの開発においてコミュニティにとって貴重なリソースとなり、LLMの実際の利用を促進することを期待しています。MultiHop-RAGと実装されたRAGシステムは、公開されています。
SourceCode
処理の流れ
参考
CRAG:Corrective Retrieval Augmented Generation (29/01/2024)
一言紹介
❓ LLMだと知識に限界があるし、検索結果を適切に出力に反映する能力もまだ低いなぁ。
💡 検索結果の品質を「正確」、「不正確」、「曖昧」などに分けて、不正確な場合はweb検索するなどにすれば精度上がるんじゃね?不要な検索結果は捨てちゃう
→標準的なRAGやSelf-RAGの性能を大幅に凌駕した
→短文や長文の生成の両方で汎用性はある。
→けど、検索結果の検証に使用する追加データの品質にやっぱり依存はする
Abstract日本語訳
大規模言語モデル(LLM)は、その内部に含まれるパラメトリック知識だけでは生成されたテキストの正確性を保証できないため、避けられない「幻覚(誤った情報の生成)」を引き起こします。検索強化生成(RAG)はLLMを補完する実用的な方法ですが、検索された文書の関連性に大きく依存するため、検索がうまくいかない場合のモデルの挙動に関する懸念が生じます。この問題に対処するために、生成の堅牢性を向上させるための「訂正検索強化生成(CRAG)」を提案します。具体的には、軽量な検索評価器を設計して、クエリに対する検索文書全体の品質を評価し、さまざまな知識検索アクションをトリガーする信頼度を返します。静的で限られたコーパスからの検索では最適な文書を返すことができないため、検索結果を拡張するために大規模なウェブ検索を利用します。また、検索された文書に含まれる重要な情報に選択的に焦点を当て、関連性のない情報をフィルタリングするために、「分解-再構成アルゴリズム」を設計しています。CRAGはプラグアンドプレイであり、さまざまなRAGベースのアプローチとシームレスに結合できます。短文および長文生成タスクをカバーする4つのデータセットでの実験により、CRAGがRAGベースのアプローチのパフォーマンスを大幅に向上させることが示されました。
Source Code
参考
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts(27/02/2024)
一言紹介
❓RAGで外部情報とモデル自身が持つ知識に矛盾がある場合はどうなる??
💡「外部情報」と「モデルの事前知識」が矛盾するとき、LLMは外部情報に説得力があるときにはそれを受け入れる傾向があるのがわかった!
また、外部情報同士に矛盾が生じている場合は、事前知識との整合性に固執する傾向があるみたいだ
Abstract日本語訳
大規模言語モデル(LLM)に外部情報を提供することで、ツールの拡張(検索拡張を含む)は、LLMの静的なパラメトリックメモリの制限に対処するための有望な解決策として浮上しています。しかし、LLMはこのような外部の証拠に対してどれほど受容的なのでしょうか、特にその証拠が矛盾する場合はどうでしょうか?私たちは、知識の矛盾に直面した際のLLMの振る舞いに関する初の包括的かつ制御された調査を行います。高品質なパラメトリックメモリをLLMから引き出し、対応するカウンターメモリを構築する体系的なフレームワークを提案し、一連の制御実験を行えるようにします。
この調査により、LLMの一見矛盾する行動が明らかになりました。一方では、これまでの知見とは異なり、外部の証拠が一貫性があり説得力がある場合、たとえそれがパラメトリックメモリと矛盾していても、LLMは非常に受容的であることがわかりました。他方では、同時に矛盾する証拠が提示されている場合でも、パラメトリックメモリと一致する情報が含まれていると、LLMは強い確認バイアスを示すこともわかりました。
これらの結果は、ツールおよび検索拡張されたLLMのさらなる開発と展開において慎重に考慮する価値のある重要な示唆を提供します。
RAFT: Adapting Language Model to Domain Specific RAG(15/03/2024)
一言紹介
❓ LLMが外部知識を取得するときの最適な方法はまだまだ課題だよね
💡RAFTという質問と取得された一連の文書が与えられたとき、質問に答えるのに役立たない文書をモデルが無視するようにトレーニングを提案するよ
→実験された全てのデータセットにおいてベースラインを上回る性能を示し、特にQAタスクでは従来の手法を大幅に上回る結果を達成したよ
Abstract日本語訳
大規模言語モデル(LLM)を大量のテキストデータコーパスで事前学習することは、現在標準的なパラダイムとなっています。これらのLLMを多くの下流アプリケーションで使用する際、RAGベースのプロンプトや微調整を通じて、新しい知識(例えば、時事ニュースやプライベートドメインの知識)を追加することが一般的です。しかし、モデルがこのような新しい知識を獲得するための最適な方法は依然として未解決の課題です。本論文では、Retrieval Augmented FineTuning(RAFT)と呼ばれるトレーニングレシピを紹介します。これは、オープンブックのドメイン内設定での質問に答えるモデルの能力を向上させます。
RAFTでは、質問と取得された一連の文書が与えられたとき、質問に答えるのに役立たない文書(我々が「ディストラクタ文書」と呼ぶ)をモデルが無視するようにトレーニングします。RAFTは、質問に答えるのに役立つ関連文書から適切なシーケンスを逐語的に引用することでこれを実現します。これに加えて、RAFTのチェーンオブソートスタイルの応答は、モデルの推論能力を向上させます。特定のドメインにおけるRAGにおいて、RAFTはPubMed、HotpotQA、およびGorillaデータセット全体で一貫してモデルのパフォーマンスを向上させ、事前学習されたLLMをドメイン内RAGに向けて改良するためのポストトレーニングレシピを提供します。RAFTのコードとデモはオープンソース化されています。
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity(21/03/2024)
一言紹介
❓ 通常のRAGだと検索する必要がない質問だったり外部知識の質が低かったら逆に性能が下がるよなぁ
💡 ユーザーから質問が来たときに、「そもそもRAGすべきか、RAGするなら複数回のドキュメント検索をすべきか?」について分類して回答しよう!(self-ragに似ている)
Abstract日本語訳
外部知識ベースからの非パラメトリックな知識を大規模言語モデル(LLM)に組み込む「検索強化大規模言語モデル(RAG)」は、質問応答(QA)などのタスクにおける応答の正確性を向上させる有望なアプローチとして浮上しています。しかし、異なる複雑さのクエリに対処する様々なアプローチが存在するものの、単純なクエリに対しては不必要な計算負荷がかかり、複雑なマルチステップクエリには十分に対応できないことがあります。実際には、ユーザーのリクエストは単純なものと複雑なもののいずれか一方にのみ分類されるわけではありません。
本研究では、クエリの複雑さに基づいて最も適切な戦略を動的に選択できる、新しい適応型QAフレームワークを提案します。この選択プロセスは、着信クエリの複雑さレベルを予測するように訓練された小型の言語モデルである分類器を用いて実現されます。この分類器は、実際のモデルの予測結果とデータセットの内在的な帰納バイアスから自動的に収集されたラベルを使用して訓練されます。このアプローチは、反復的および単一ステップの検索強化LLM、さらには検索を使用しない方法の間をシームレスに適応させ、クエリの複雑さに応じてバランスの取れた戦略を提供します。
私たちは、複数のクエリ複雑さをカバーする一連のオープンドメインQAデータセットでモデルを検証し、関連するベースライン(適応検索アプローチを含む)と比較して、QAシステムの全体的な効率と正確性が向上することを示しました。
処理の流れ
ユーザーからの質問について、簡単、中程度、複雑の3つに分類し、それぞれの場合で最適な回答手法を適用させる
簡単な質問 → 検索なしでLLMのみで回答
中程度の質問 → LLMと1回の検索を組み合わせて回答
複雑な質問 → LLMと複数回の検索を繰り返し、推論を重ねて回答

参考
FIT-RAG: Black-Box RAG with Factual Information and Token Reduction(21/03/2024)
一言紹介
❓LLMはパラメータ数大きすぎてタスクに合わせてファインチューニングなんて無理!!そのためのRAGなんだけど、RAGの検索って不要なトークン含まれてたり、性能落ちるしトークンの消費量も激しいなぁ。
💡事実情報とLLMの好みの両方をスコアリングして、外部知識が必要か判断させて不要な情報省いたろ!
→トークン数を半分にすることに成功
Abstract 日本語訳
非常に多くのパラメータが存在するため、大規模言語モデル(LLM)の微調整によってロングテールや古い知識を更新することは、多くのアプリケーションで実現不可能です。微調整を避けるために、LLMをブラックボックス(つまり、LLMのパラメータを固定)として扱い、Retrieval-Augmented Generation(RAG)システムを組み合わせることができます。これを「ブラックボックスRAG」と呼びます。最近、ブラックボックスRAGは知識集約型タスクで成功を収め、多くの注目を集めています。既存のブラックボックスRAGの手法は通常、リトリーバーを微調整してLLMの好みに合わせ、すべての取得文書を入力として連結しますが、以下の2つの問題があります:(1) 事実情報の無視。LLMが好む文書には、与えられた質問に対する事実情報が含まれていない場合があり、リトリーバーを誤導し、ブラックボックスRAGの効果を損ないます。(2) トークンの浪費。単にすべての取得文書を連結すると、LLMにとって不必要なトークンが大量に発生し、ブラックボックスRAGの効率が低下します。
これらの問題に対処するために、本論文では、検索における事実情報を利用し、強化のためのトークン数を削減する新しいブラックボックスRAGフレームワーク「FIT-RAG」を提案します。FIT-RAGは、二重ラベル文書スコアラーを構築することで事実情報を利用します。さらに、自己知識認識器とサブドキュメントレベルのトークンリデューサーを導入することでトークンを削減します。FIT-RAGは、広範な実験により、その優れた効果と効率が検証されました。3つのオープンドメイン質問応答データセット(TriviaQA、NQ、PopQA)での実験結果は、FIT-RAGがLlama2-13B-Chatの回答精度をそれぞれTriviaQAで14.3%、NQで19.9%、PopQAで27.5%向上させることを示しています。さらに、3つのデータセット全体で平均して約半分のトークンを節約することができます。
参考
Generate then Retrieve: Conversational Response Retrieval Using LLMs as Answer and Query Generators(28/03/2024)
一言紹介
❓LLMの進歩に伴って対話型検索システムの注目がまた集まってるけど、結局,RAGのような対話型検索システムを構築するときに、「検索してから生成」するアプローチと「生成してから検索」するアプローチのどっちがいいんだろ??
💡ユーザーの質問に対してLLMが一度回答し、その回答をもとに複数のクエリを作るアプローチの有効性が高そうなのがわかった
Abstract日本語訳
CISは、対話型知識アシスタントを開発することに焦点を当てた情報検索(IR)の重要な分野です。これらのシステムは、会話の文脈内でユーザーの情報要求を巧みに理解し、関連情報を検索する必要があります。この目的のために、既存のアプローチは、クエリスペース埋め込みにおいて単一のクエリリライトまたはクエリの単一の表現を生成することでユーザーの情報ニーズをモデル化しています。しかし、複雑な質問に答えるためには、単一のクエリリライトや表現では不十分なことが多いです。この課題に対処するために、システムは複数のパッセージに対して推論を行う必要があります。
本研究では、複雑なユーザークエリに対するパッセージ検索性能を向上させるために、生成してから検索するアプローチを提案します。このアプローチでは、次のことを行うために大規模言語モデル(LLM)を利用します:(i) 会話の文脈に基づいてユーザーの情報要求に対する初期回答を生成し、(ii) この回答をコレクションに基づかせる。実験に基づいて、提案するアプローチは、TREC iKAT 23、TREC CAsT 20、および22のデータセットにおいて、さまざまな設定で検索性能を大幅に向上させることが示されました。また、LLMの回答を基礎づけるには、平均して3つの検索可能なクエリが必要であり、これが人間によるリライトを上回ることも示しました。
参考
GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning(30/05/2024)
一言紹介
Knowledge Graph(知識グラフ)を使ったQAシステムでもっといい方法はないだろうか??
💡GNNを使ってKnowledge Graph(知識グラフ)からデータを取得するRAGシステムを構築しよう
従来のKnowledge Graphを使用したQAの手法と比べて8.9~15.5%性能を改善
7BレベルのLLMでもGPT-4と同等の性能
Abstract日本語訳
ナレッジグラフ(KG)は、人間が作成した事実知識をトリプレット(主語、関係、目的語)の形で表現し、それらが集まってグラフを形成します。ナレッジグラフを用いた質問応答(KGQA)は、KGが提供する情報に基づいた推論を行い、自然言語の質問に答えるタスクです。大規模言語モデル(LLM)は、自然言語を理解する優れた能力を持ち、QAタスクにおいて最先端のモデルです。一方、グラフニューラルネットワーク(GNN)は、KGに保存された複雑なグラフ情報を処理できるため、KGQAで広く使用されています。
本研究では、LLMの言語理解能力とGNNの推論能力を組み合わせた、新しい方法「GNN-RAG」を紹介します。この方法は、検索強化生成(RAG)スタイルで行われます。まず、GNNが密なKG部分グラフを推論し、与えられた質問に対する回答候補を検索します。次に、質問エンティティと回答候補を結びつけるKG内の最短経路を抽出し、KG推論パスを表現します。抽出されたパスは言語化され、RAGを用いたLLM推論の入力として与えられます。GNN-RAGフレームワークでは、GNNが有用なグラフ情報を抽出する密な部分グラフ推論者として機能し、LLMは最終的なKGQAのために自然言語処理能力を活用します。
さらに、KGQA性能を向上させるための検索強化(RA)技術も開発しました。実験結果は、GNN-RAGが2つの広く使用されているKGQAベンチマーク(WebQSPおよびCWQ)において、7BチューニングされたLLMでGPT-4の性能を上回るか同等の最先端のパフォーマンスを達成することを示しています。また、GNN-RAGはマルチホップおよびマルチエンティティの質問においても優れた性能を発揮し、競合するアプローチに対して回答F1で8.9~15.5%ポイント上回りました。

Github
参考
GRAG: Graph Retrieval-Augmented Generation(26/05/2024)
一言紹介
❓ 通常のRAGはグラフベースの文脈では使いにくいよなぁ。
💡グラフ構造の知識ベースを利用し、エンティティ間の関係性を考慮しながら情報を検索・生成するRAGの手法を提案
Abstract日本語訳
Retrieval-Augmented Generation(RAG)は生成型言語モデルの応答の正確性と関連性を向上させますが、テキスト情報とトポロジカル情報の両方が重要なグラフベースの文脈では効果が不十分です。ナイーブなRAGアプローチは、テキストグラフの構造的な複雑さを無視するため、生成プロセスにおいて重要なギャップが生じます。この課題に対処するために、Graph Retrieval-Augmented Generation(GRAG)を導入します。GRAGは、サブグラフ構造の重要性を強調することで、検索プロセスと生成プロセスの両方を大幅に向上させます。テキストベースのエンティティ検索にのみ焦点を当てるRAGアプローチとは異なり、GRAGはグラフのトポロジーを厳密に認識し、文脈的および事実的に整合性のある応答を生成するために不可欠です。
GRAGアプローチは主に4つのステージから成ります:k-hopエゴグラフのインデックス作成、グラフ検索、不適切なエンティティの影響を軽減するソフトプルーニング、およびプルーニングされたテキストサブグラフを用いた生成です。GRAGのコアワークフローは、テキストサブグラフを検索し、続いてソフトプルーニングを行うことで、関連するサブグラフ構造を効率的に特定し、NP困難な完全なサブグラフ検索に典型的な計算上の非現実性を回避します。さらに、テキストサブグラフを階層的なテキスト記述に無損失で変換する新しいプロンプト戦略を提案します。
グラフのマルチホップ推論ベンチマークに関する広範な実験により、テキストグラフに対するマルチホップ推論が必要なシナリオで、GRAGアプローチが現行の最先端RAG手法を大幅に上回り、幻覚を効果的に軽減することが示されました。
Github
参考
CRAG -- Comprehensive RAG Benchmark(07/06/2024)
一言紹介
❓ RAGの既存のベンチマーク用データセットって、実際のビジネス的な運用考えるとまだ役に立たんよね
💡CRAG(Comprehensive RAG)というRAGベンチマークを作ったよ!
→4,409の質問応答ペア
→Webおよび知識グラフ(KG)検索をシミュレートする模擬API
のベンチマークデータセット
このベンチマークでは、
最先端のLLM→正解率34%
単純にRAGを追加→正答率44%
最先端の業界RAG→正答率63%
の結果が出ている
Abstract日本語約
Retrieval-Augmented Generation(RAG)は、大規模言語モデル(LLM)の知識不足という欠点を軽減するための有望な解決策として最近登場しました。しかし、既存のRAGデータセットは、実世界の質問応答(QA)タスクの多様で動的な性質を十分に表現していません。このギャップを埋めるために、私たちは包括的なRAGベンチマーク(CRAG)を導入します。CRAGは、4,409の質問応答ペアと、Webおよび知識グラフ(KG)検索をシミュレートする模擬APIを備えた事実ベースの質問応答ベンチマークです。
CRAGは、5つの領域と8つの質問カテゴリにわたる多様な質問を取り入れ、人気のあるエンティティからロングテールのエンティティ、年単位から秒単位の時間的動態までを反映しています。このベンチマークでの評価は、完全に信頼できるQAへのギャップを浮き彫りにします。最先端のLLMの多くは、CRAGでの正確度が34%以下ですが、単純にRAGを追加すると正確度は44%に向上します。最先端の業界RAGソリューションは、幻覚を伴わずに63%の質問にしか回答できません。CRAGはまた、動的性が高く、人気が低く、複雑さが高い事実に関する質問に対する正確度がはるかに低いことを明らかにしており、将来の研究方向性を示唆しています。
CRAGベンチマークは、KDD Cup 2024チャレンジの基盤を築き、競技開始後の最初の50日間で数千の参加者と提出物を引き付けました。私たちは、RAGソリューションおよび一般的なQAソリューションの進展を支援するために、CRAGを維持し続けることを約束します。
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering(11/06/2024)
一言紹介
❓クエリごとにLLMに複数回アクセスするのはコスパ悪いなぁ。かといって、単一のクエリだと信頼性低いし。。
💡重要な文章と一部のクエリを組み合わせるだけで、残りの関連する文章見つける方法考えてみた!
→DR-RAG
Abstract日本語訳
Retrieval-Augmented Generation(RAG)は、最近、質問応答(QA)などの知識集約型タスクにおける大規模言語モデル(LLM)の性能を示しました。RAGは外部の知識ベースを取り込むことでクエリの文脈を拡張し、応答の正確性を高めます。しかし、クエリごとにLLMに複数回アクセスするのは非効率であり、単一のクエリで関連するすべての文書を取得するのは信頼性が低いです。我々は、重要な文書とクエリの関連性が低い場合でも、文書の一部をクエリと組み合わせることで残りの文書を取得できることを発見しました。この関連性を引き出すために、動的関連性検索強化生成(Dynamic-Relevant Retrieval-Augmented Generation、DR-RAG)と呼ばれる二段階の検索フレームワークを提案し、文書の検索リコールと回答の正確性を向上させながら効率を維持します。さらに、コンパクトな分類器を適用し、2つの異なる選択戦略で取得された文書がクエリの回答にどれだけ寄与するかを判断し、比較的関連性の高い文書を取得します。DR-RAGはLLMを一度だけ呼び出すため、実験の効率を大幅に改善します。マルチホップQAデータセットでの実験結果は、DR-RAGが回答の正確性を大幅に向上させ、QAシステムにおいて新たな進展を達成できることを示しています。
処理の流れ

From RAGs to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries(18/06/2024)
一言紹介
❓RAGの性質・傾向はまだ分かってないことが多いよね
💡RAGで取得されたコンテキストは内部の知識よりも優先されることがわかったよ
→RAGが実行された時は、(もとの質問文の文脈を無視して)取得された情報に注目して答えてしまう可能性がある
Abstract日本語訳
Retrieval Augmented Generation(RAG)は、外部コンテキストを利用して言語モデルの応答を強化することで、ユーザーのプロンプトに対する推論能力を向上させます。このアプローチは、検索、質問応答、チャットボットなどのさまざまな言語モデルの実用的な応用において人気が高まっています。しかし、このアプローチがどのように機能するかの正確な性質は明確に理解されていません。本論文では、RAGパイプラインを機械的に検討し、言語モデルがショートカットを取り、質問に答える際にコンテキスト情報のみを利用する強いバイアスがあり、パラメトリックメモリにはほとんど依存しないことを強調します。この機械的な振る舞いを次の方法で調査しました:(i) 因果媒介分析を用いて、質問に答える際にパラメトリックメモリが最小限しか利用されていないことを示し、(ii) 注意貢献度とノックアウト分析を用いて、質問の主語トークンからではなく、コンテキスト内の他の情報豊富なトークンから最終トークンの残差ストリームが強化されることを示します。この顕著なショートカットの振る舞いは、LLaMaおよびPhiファミリーのモデル全体で真実であることがわかりました。
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?(19/06/2024)
一言紹介
❓巨大なコンテキストウィンドウのLLMのせいでRAGが不必要になるかもしれないかみんな不安よな?松本動きます。
💡Geminiに長いコンテキストを挿入してRAGと性能を比較する実験をしたところ、ロングコンテキストLLMは一定のパラダイムシフトをもたらす可能性を示唆しました。
Abstract日本語訳
長コンテキスト言語モデル(LCLM)は、従来は検索システムやデータベースなどの外部ツールに依存していたタスクへのアプローチを革新する可能性があります。LCLMが全体の情報コーパスをネイティブに取り込み処理する能力を活用することで、多くの利点が得られます。これにより、ツールに関する専門知識の必要がなくなり、ユーザーフレンドリーさが向上し、複雑なパイプラインにおける連鎖的なエラーを最小限に抑える堅牢なエンドツーエンドのモデリングが提供されます。また、システム全体で高度なプロンプト技術を適用することができます。
このパラダイムシフトを評価するために、私たちはLOFTを導入します。これは、数百万トークンのコンテキストを必要とする実世界のタスクのベンチマークであり、LCLMのインコンテキスト検索と推論の性能を評価するために設計されています。我々の調査結果は、LCLMがこれらのタスクのために明示的に訓練されていないにもかかわらず、最新の検索およびRAGシステムに匹敵する驚くべき能力を持っていることを示しています。しかし、LCLMはSQLのようなタスクで必要とされる合成推論などの分野ではまだ課題に直面しています。特に、プロンプト戦略がパフォーマンスに大きな影響を与えることが明らかであり、コンテキストの長さが増加するにつれて継続的な研究の必要性が強調されています。
全体として、LOFTはLCLMのための厳密なテスト環境を提供し、既存のパラダイムを置き換え、新たなタスクに取り組むためのモデル能力の拡大を示しています。
LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs(21/06/2024)
一言紹介
❓ RAGって短い文章(例えば通常100語程度)を検索単位として使用すること多いけど、検索する候補が多くなって負担かかるし、短い文章を検索単位にすると、文章の一貫性失われたりするよなぁ。
💡長い文章を検索単位として採用すれば負担減るよね! LongRAGは長文の検索性能を良くするために最新の長文脈処理技術をたくさん詰め込んだフレームワークだよ!
→従来のRAGシステムより長い検索ユニット(平均6,000トークン)を使用し、検索性能を大幅に向上させたよ
→ーパスサイズを30倍圧縮(22Mから600Kへ)しながら、トップ1回答再現率を20ポイント向上(52.24%から71.69%へ)させたよ
→従来のRAGより少ない検索ユニット数(10倍少ない)で同等の結果を達成し、効率的に関連情報を抽出できるよ
→オープンドメイン質問応答タスクにおいて、ファインチューニングなしで完全教師あり学習手法に匹敵する性能を示したよ
→長文脈読解器モデルの選択がLongRAGの性能に大きな影響を与え、GPT-4oが最も高い性能を示したよ
→現状の長い埋め込みモデルにはまだ改善の余地があり、一般的な埋め込みモデル(BGE-Large)を使用した近似方法が最も高い性能したよ
Abstract要約
従来のRAG(Retrieval-Augmented Generation)フレームワークでは、基本的な検索単位は通常短いものです。一般的なリトリーバー(検索器)であるDPR(Dense Passage Retrieval)は通常、100語のWikipediaの段落で動作します。このような設計は、リトリーバーが「針のような」単位を見つけるために大規模なコーパスを検索することを強制します。一方で、リーダー(読取器)は、検索された短い単位から答えを抽出するだけで済みます。このような「重い」リトリーバーと「軽い」リーダーの不均衡な設計は、最適ではないパフォーマンスにつながる可能性があります。
この不均衡を緩和するために、「ロングリトリーバー」と「ロングリーダー」からなる新しいフレームワーク「LongRAG」を提案します。LongRAGは、Wikipedia全体を4Kトークン単位に処理し、以前の30倍の長さにします。単位サイズを大きくすることで、総単位数を2200万から70万に大幅に削減します。これにより、リトリーバーの負担が大幅に軽減され、驚異的な検索スコアを達成しました:NQでの回答リコール@1が71%(以前は52%)、HotpotQA(全体のWikipedia)での回答リコール@2が72%(以前は47%)。
次に、上位k件の検索単位(約30Kトークン)を既存の長コンテキストLLMに入力し、ゼロショットでの回答抽出を行います。トレーニングを必要とせず、LongRAGはNQで62.7%のEM(正確一致)を達成し、これは現在知られている最高の結果です。LongRAGはまた、HotpotQA(全体のWikipedia)で64.3%を達成し、SoTA(最先端)モデルと同等のパフォーマンスを示しました。我々の研究は、長コンテキストLLMとRAGを組み合わせるための将来のロードマップに洞察を提供します。
参考
REGAS(RAG評価指標)
参考
https://zenn.dev/mizunny/articles/a92d95a26da32e
この記事が気に入ったらサポートをしてみませんか?