
高度なRAG検索戦略:Corrective Retrieval Augmented Generation(CRAG)

簡単な実装例、原則、コードの説明、およびCRAGに関する洞察
この記事では、オープンブックテスト(試験中に教科書や自分のノート、場合によってはオンライン資源を参照することが許可される試験形式)に参加するプロセスをCRAGを使って実証してみます。
オープンブックテストで解答を見つけるための手法として次の3つが挙げられます。
方法1:馴染みのあるトピックに対しては素早く回答します。馴染みのないトピックに対しては、参考書を参照します。関連するセクションを素早く見つけ、それらを整理して要約し、その後、試験用紙に回答を書きます。
方法2:各トピックについて、参考書を参照します。関連するセクションを特定し、それらを頭の中で要約し、その後、試験用紙に回答を書きます。
方法3:各トピックについて、参考書を参照し、関連するセクションを特定します。意見を形成する前に、収集した情報を「正しい」、「間違っている」、「曖昧」の3つのグループに分類します。それぞれのタイプの情報を個別に処理します。その後、この処理された情報に基づいて、それをまとめて要約します。その後、試験用紙に回答を書きます。
方法1にはself-RAGが関与しており、方法2はクラシックRAGプロセスです。
最後に、この記事ではCorrective Retrieval Augmented Generation (CRAG)と呼ばれる方法3が紹介されています。
CRAGが必要なケース

図1: これらの例は、品質の低いリトリーバーが大量の関連のない情報を導入しやすいことを示しており、これによってジェネレーターが正確な知識を獲得するのを妨げ、可能性として誤解を招くことがあります。出典:Corrective Retrieval Augmented Generation。
図1は、従来のRAG(Corrective Retrieval Augmented Generation)手法のほとんどが質問に対する文書の関連性を考慮せず、単に取得した文書を統合することを示しています。これにより、正確な知識を獲得するモデルを妨げ、誤解を招く可能性があり、幻覚の問題を引き起こすことがあります。
さらに、従来のRAG手法のほとんどは、取得した文書全体を入力として扱います。しかし、これらの取得した文書のテキストの大部分は、生成には必要なく、RAGに等しく関与すべきではありません。
CRAGの主要なアイデア
CRAGは、特定のクエリのために取得された文書の全体的な品質を評価する軽量なリトリーバー評価ツールを提供しています。また、取得結果を改善するためにウェブ検索を補助ツールとして使用しています。
CRAGはプラグアンドプレイであり、RAGに基づくさまざまな手法とのシームレスな統合を可能にします。全体的なアーキテクチャは図2に示されています。
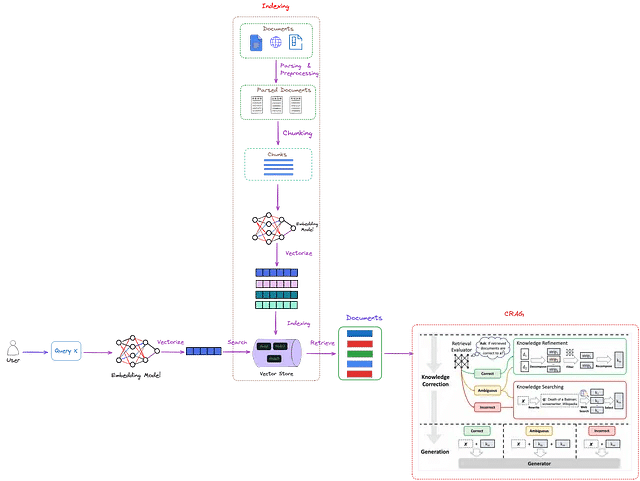
図2:RAG内のCRAG(赤い点線のボックス)の位置。検索評価者は、取得された文書の関連性を評価するために設計されています。また、異なる知識取得アクションをトリガーする信頼レベルを推定します。具体的には、{正しい、不正確、曖昧}です。ここで、"x"はクエリを表します。画像提供:著者、CRAGセクション(赤い点線のボックス)はCorrective Retrieval Augmented Generationから取得されています。
図2に示すように、CRAGは、取得された文書とクエリの関係を評価するための検索評価者を導入することで、従来のRAGを強化しています。
3つの判断結果があります。
正しい場合、取得された文書がクエリに必要なコンテンツを含んでいることを意味し、取得された文書を書き直すための知識の洗練アルゴリズムを適用します。
取得された文書が不正確な場合、クエリと取得された文書が関連していないことを意味します。その結果、文書をLLMに送ることはできません。CRAGでは、外部の知識を取得するためにWeb検索エンジンが使用されます。
曖昧な場合、取得された文書が近いが十分でない可能性があることを意味します。そのような場合、追加情報はWeb検索を通じて取得する必要があります。したがって、知識の洗練アルゴリズムと検索エンジンの両方が使用されます。

図3:評価と処理。出典:Corrective Retrieval Augmented Generation。
Web検索はユーザーの入力クエリを直接検索に使用しないことに注意してください。代わりに、プロンプトを構築し、それをGPT-3.5 Turboに提示して、検索クエリを取得します。
手法の一般的な理解を得た後は、CRAGの2つの主要なコンポーネントである検索評価者と知識洗練アルゴリズムを説明します。
検索評価者
図4に示すように、検索評価者は後続の手順の結果に大きく影響し、全体のシステムのパフォーマンスを決定する上で重要です。
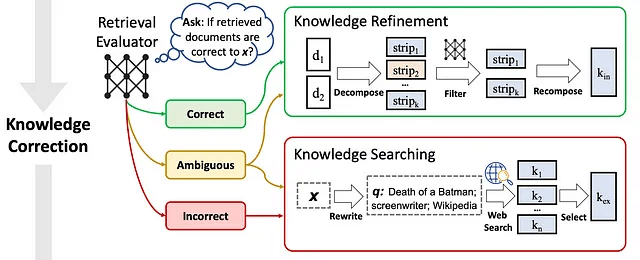
図4:CRAGにおける知識修正。出典:Corrective Retrieval Augmented Generation。
CRAGは、軽量なT5-largeモデルを検索評価器として使用し、その後微調整を行います。大規模言語モデルの時代においても、T5-largeは軽量と見なされています。
通常、各クエリに対して10件の文書が検索されます。その後、クエリはそれぞれの文書と連結され、その関連性を予測するための入力となります。微調整プロセスでは、正例にはラベル1を、負例には-1を割り当てます。推論時には、評価器が各文書に-1から1までの関連スコアを割り当てます。
これらのスコアは、閾値に基づいて3つのレベルに分類されます。この分類には2つの閾値が必要です。CRAGでは、閾値設定は実験データに応じて異なる場合があります。
3つのアクションのうち1つをトリガーするための2つの信頼度の閾値は経験的に設定されました。具体的には、PopQAでは(0.59、-0.99)、PubQAおよびArcChallengeでは(0.5、-0.91)、Biographyでは(0.95、-0.91)と設定されました。
知識精練アルゴリズム
関連する取得文書に対して、CRAGは知識抽出のための分解して再構成する手法を設計しており、図4に示されているように、最も重要な知識文をさらに抽出します。
まず、ヒューリスティックルールを適用して、各文書を細かく分割し、細かい知識ストリップを得ることを目指しています。取得した文書が1つまたは2つの文で構成されている場合、それは独立した単位と見なされます。それ以外の場合、文書は総文字数に応じて、通常は複数の文で構成されるようにより小さな単位に分割されます。各単位には独立した情報が含まれることが期待されています。
次に、取得評価者を使用して各知識ストリップの関連スコアを計算します。関連スコアが低いストリップはフィルタリングされます。残りの関連する知識ストリップは再構成され、内部知識を形成するために使用されます。
コードの説明
CRAGはオープンソースであり、LangchainとLlamaIndexはそれぞれ独自の実装を提供しています。私たちは、説明のためにLlamaIndexの実装を参照します。
環境構成
(base) Florian:~ Florian$ conda create -n crag python=3.11
(base) Florian:~ Florian$ conda activate crag
(crag) Florian:~ Florian$ pip install llama-index llama-index-tools-tavily-research
(crag) Florian:~ Florian$ mkdir "YOUR_DOWNLOAD_DIR"インストール後、LlamaIndexとTavilyの対応バージョンは次のとおりです:
(crag) Florian:~ Florian$ pip list | grep llama
llama-index 0.10.29
llama-index-agent-openai 0.2.2
llama-index-cli 0.1.11
llama-index-core 0.10.29
llama-index-embeddings-openai 0.1.7
llama-index-indices-managed-llama-cloud 0.1.5
llama-index-legacy 0.9.48
llama-index-llms-openai 0.1.15
llama-index-multi-modal-llms-openai 0.1.5
llama-index-packs-corrective-rag 0.1.1
llama-index-program-openai 0.1.5
llama-index-question-gen-openai 0.1.3
llama-index-readers-file 0.1.19
llama-index-readers-llama-parse 0.1.4
llama-index-tools-tavily-research 0.1.3
llama-parse 0.4.1
llamaindex-py-client 0.1.18
(crag) Florian:~ Florian$ pip list | grep tavily
llama-index-tools-tavily-research 0.1.3テストコード
テストコードは以下の通りです。最初の実行には、CorrectiveRAGPackのダウンロードが必要です。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from llama_index.core import Document
# Option: Download CorrectiveRAGPack
# The first execution requires the download of CorrectiveRAGPack
# Subsequent executions can comment this out.
from llama_index.core.llama_pack import download_llama_pack
CorrectiveRAGPack = download_llama_pack(
"CorrectiveRAGPack", "YOUR_DOWNLOAD_DIR"
)
# Create testing documents
documents = [
Document(
text="A group of penguins, known as a 'waddle' on land, shuffled across the Antarctic ice, their tuxedo-like plumage standing out against the snow."
),
Document(
text="Emperor penguins, the tallest of all penguin species, can dive deeper than any other bird, reaching depths of over 500 meters."
),
Document(
text="Penguins' black and white coloring is a form of camouflage called countershading; from above, their black back blends with the ocean depths, and from below, their white belly matches the bright surface."
),
Document(
text="Despite their upright stance, penguins are birds that cannot fly; their wings have evolved into flippers, making them expert swimmers."
),
Document(
text="The fastest species, the Gentoo penguin, can swim up to 36 kilometers per hour, using their flippers and streamlined bodies to slice through the water."
),
Document(
text="Penguins are social birds; many species form large colonies for breeding, which can number in the tens of thousands."
),
Document(
text="Intriguingly, penguins have excellent hearing and rely on distinct calls to identify their mates and chicks amidst the noisy colonies."
),
Document(
text="The smallest penguin species, the Little Blue Penguin, stands just about 40 cm tall and is found along the coastlines of southern Australia and New Zealand."
),
Document(
text="During the breeding season, male Emperor penguins endure the harsh Antarctic winter for months, fasting and incubating their eggs, while females hunt at sea."
),
Document(
text="Penguins consume a variety of seafood; their diet mainly consists of fish, squid, and krill, which they catch on their diving expeditions."
),
]
from llama_index.packs.corrective_rag import CorrectiveRAGPack
corrective_rag = CorrectiveRAGPack(documents, "YOUR_TAVILYAI_API_KEY")
# From here, you can use the pack, or inspect and modify the pack in ./corrective_rag_pack.
# The run() function contains around logic behind Corrective Retrieval Augmented Generation - CRAG paper.
query = "How tall is the smallest penguins?"
print('-' * 100)
print("The response of the query " + query + " is:")
response = corrective_rag.run(query, similarity_top_k=2)
print(response)YOUR\_TAVILYAI\_API\_KEY はこのウェブサイトから申請できます。
テストコードは以下の結果を出力しました(デバッグ情報のほとんどは削除されています)。
(crag) Florian:~ Florian$ python /Users/Florian/Documents/crag.py
----------------------------------------------------------------------------------------------------
The response of the query How tall is the smallest penguins? is:
----------------------------------------------------------------------------------------------------
The smallest penguins are about 40 cm (16 inches) tall.テストコードを理解する鍵は、corrective\_rag.run() の実装にあります。それについて詳しく見てみましょう。
CorrectiveRAGPackクラスのコンストラクタ
まず、コンストラクタ関数を見てみましょう。ソースコード は以下の通りです。
class CorrectiveRAGPack(BaseLlamaPack):
def __init__(self, documents: List[Document], tavily_ai_apikey: str) -> None:
"""Init params."""
llm = OpenAI(model="gpt-4")
self.relevancy_pipeline = QueryPipeline(
chain=[DEFAULT_RELEVANCY_PROMPT_TEMPLATE, llm]
)
self.transform_query_pipeline = QueryPipeline(
chain=[DEFAULT_TRANSFORM_QUERY_TEMPLATE, llm]
)
self.llm = llm
self.index = VectorStoreIndex.from_documents(documents)
self.tavily_tool = TavilyToolSpec(api_key=tavily_ai_apikey)デフォルト設定はgpt-4です。gpt-4を使用する権限がない場合は、手動でgpt-3.5-turboに切り替えることができます。
class CorrectiveRAGPack:: run()
関数run()のソースコードは以下の通りです:
class CorrectiveRAGPack(BaseLlamaPack):
...
...
def run(self, query_str: str, **kwargs: Any) -> Any:
"""Run the pipeline."""
# Retrieve nodes based on the input query string.
retrieved_nodes = self.retrieve_nodes(query_str, **kwargs)
# Evaluate the relevancy of each retrieved document in relation to the query string.
relevancy_results = self.evaluate_relevancy(retrieved_nodes, query_str)
# Extract texts from documents that are deemed relevant based on the evaluation.
relevant_text = self.extract_relevant_texts(retrieved_nodes, relevancy_results)
# Initialize search_text variable to handle cases where it might not get defined.
search_text = ""
# If any document is found irrelevant, transform the query string for better search results.
if "no" in relevancy_results:
transformed_query_str = self.transform_query_pipeline.run(
query_str=query_str
).message.content
# Conduct a search with the transformed query string and collect the results.
search_text = self.search_with_transformed_query(transformed_query_str)
# Compile the final result. If there's additional search text from the transformed query,
# it's included; otherwise, only the relevant text from the initial retrieval is returned.
if search_text:
return self.get_result(relevant_text, search_text, query_str)
else:
return self.get_result(relevant_text, "", query_str)上記のコードと標準のCRAGプロセスには3つの主な違いがあります。
ambiguousドキュメントの判断や処理はありません。
訓練されたT5-largeモデルの代わりに、LLMを使用して取得した情報を評価します。
知識の洗練プロセスがスキップされます。
これらの違いにもかかわらず、LlamaIndexは(langchainも同様に)新しい考え方を提供します。
取得した情報を評価するためにLLMを使用する
このコードは次のとおりです:
class CorrectiveRAGPack(BaseLlamaPack):
...
...
def evaluate_relevancy(
self, retrieved_nodes: List[Document], query_str: str
) -> List[str]:
"""Evaluate relevancy of retrieved documents with the query."""
relevancy_results = []
for node in retrieved_nodes:
relevancy = self.relevancy_pipeline.run(
context_str=node.text, query_str=query_str
)
relevancy_results.append(relevancy.message.content.lower().strip())
return relevancy_results以下は、LLMを呼び出すためのプロンプトです。
DEFAULT_RELEVANCY_PROMPT_TEMPLATE = PromptTemplate(
template="""As a grader, your task is to evaluate the relevance of a document retrieved in response to a user's question.
Retrieved Document:
-------------------
{context_str}
User Question:
--------------
{query_str}
Evaluation Criteria:
- Consider whether the document contains keywords or topics related to the user's question.
- The evaluation should not be overly stringent; the primary objective is to identify and filter out clearly irrelevant retrievals.
Decision:
- Assign a binary score to indicate the document's relevance.
- Use 'yes' if the document is relevant to the question, or 'no' if it is not.
Please provide your binary score ('yes' or 'no') below to indicate the document's relevance to the user question."""
)CRAG論文によると、ChatGPTの検索の関連性を特定する性能は、T5-Largeよりも高くありません。
さらに、実践的なプロジェクトでは、元の知識の改良アルゴリズムを確かに使用できます。関連するコードはこちらで見つけることができます。
検索用のクエリを書き直す
以前にも述べたように、Web検索ではユーザーの入力クエリを直接使用しません。代わりに、プロンプトを構築し、それをGPT-3.5 Turboに提示して、フューショットアプローチを使用して検索クエリを取得します。プロンプトは次のようになります。
DEFAULT_TRANSFORM_QUERY_TEMPLATE = PromptTemplate(
template="""Your task is to refine a query to ensure it is highly effective for retrieving relevant search results. n
Analyze the given input to grasp the core semantic intent or meaning. n
Original Query:
n ------- n
{query_str}
n ------- n
Your goal is to rephrase or enhance this query to improve its search performance. Ensure the revised query is concise and directly aligned with the intended search objective. n
Respond with the optimized query only:"""
)CRAGに関する私の洞察と考え
CRAGとself-RAGの違い
プロセスの観点から見ると、self-RAGは取得なしでLLMを使用して直接的な応答を提供できるが、CRAGは評価レイヤーを追加する前に取得を行う必要がある。
構造的な観点から見ると、self-RAGはCRAGよりも複雑であり、より入念なトレーニング手順と複数のラベル生成および評価が要求されるため、生成段階で推論コストが不可避的に増加する。その結果、CRAGはself-RAGよりも軽量である。
パフォーマンスの観点からは、図5に示されているように、CRAGは一般的にほとんどの状況でself-RAGを上回る。

図5:4つのデータセットのテストセットでの総合評価結果。
結果は生成LLMsに基づいて分けられています。太字の数字は、すべての方法とLLMsの中で最良のパフォーマンスを示しています。グレーの太字のスコアは、特定のLLMを使用した最良のパフォーマンスを示しています。*はCRAGによって再現された結果を示しており、それ以外の結果は当社のもの以外は元の論文から引用されています。出典:Corrective Retrieval Augmented Generation。
検索評価モデルの改善
検索評価モデルは、スコアリング分類モデルと見なすことができます。このモデルは、RAGの再ランキングモデルと同様に、クエリとドキュメントの関連性を決定するために使用されます。
このような関連性判断モデルは、現実世界のシナリオに合致するより多くの特徴を統合することで改善することができます。たとえば、科学論文の質問応答RAGには多くの専門用語が含まれていますが、観光分野のRAGにはより口語的なユーザークエリが含まれる傾向があります。
検索評価モデルのトレーニングデータにシーン特徴を追加することで、取得されたドキュメントの関連性をよりよく評価することができます。ユーザーの意図や編集距離などの他の特徴も、図6に示すように組み込むことができます。

図6:追加の特徴の統合によるCRAG内の検索評価者のトレーニングの改善。著者による画像。
さらに、T5-Largeによって得られた結果を考慮すると、軽量モデルも良い結果を達成できる可能性があります。これは、小規模チームや企業でのCRAGの適用に希望をもたらします。
検索評価者のスコアと閾値
先に述べたように、閾値はさまざまなタイプのデータによって異なります。さらに、曖昧と不正確の閾値は基本的に-0.9程度であり、取得された知識の大部分がクエリに関連していることを示唆しています。この取得された知識を完全に破棄し、ウェブ検索だけに頼ることは適切ではないかもしれません。
実際の応用では、実際の問題やニーズに応じて調整する必要があります。
結論
この記事は直感的な例から始まり、CRAGの基本的なプロセスを概説し、コードの説明を補足しています。また、私自身の洞察と考えも含まれています。
要約すると、プラグアンドプレイのプラグインとしてのCRAGは、RAGのパフォーマンスを大幅に向上させることができます。これは、RAGの改善のための軽量なソリューションを提供します。

データ元:
この記事が気に入ったらサポートをしてみませんか?