
Google driveのOCR文字抽出機能でお手軽リザルト画像解析

Google driveのOCR文字抽出機能
「画像認識」「AI」というキーワードが並んだ時多くの方が思い浮かべるのが、「OCR」ではないだろうか。
「eスポーツ×⽣成AI 技術イノベーション研究会」の最大の目的は、ゲームのマッチ終了後のリザルト画像から、情報を抽出し業務の効率化を図ること。
真っ先に「OCR」をリサーチしたことは言うまでもない。
その「OCR」を簡単にお手頃価格で利用し、お得に業務効率化できれば最高ではないか、ということで目をつけたのが「Google driveのOCR文字抽出機能」である。
使い方は超簡単。文字抽出したい画像をGoogle driveにアップロードし、マウスを右クリックして「Google document」を開くだけ。
早速、前回検証したstandoff2の画像で試してみた。
フル画像

こちらの画像のフルバージョンでまずは検証。

上記のように、数字と文字の羅列が表示された。
しかし、よくよく見てみると、画像を「左から右」へ「1列ずつ」表記していることがわかる。
しかも、アルファベット、数字、日本語、すべての文字において、ほぼ100%に近い正答率。
「情報抽出」という点だけにおいては、かなり精度が高いといえるだろう。
カテゴリ別にトリミング
ということで、画像をカテゴリ別にトリミングし、各画像をOCR機能にかけてみた。
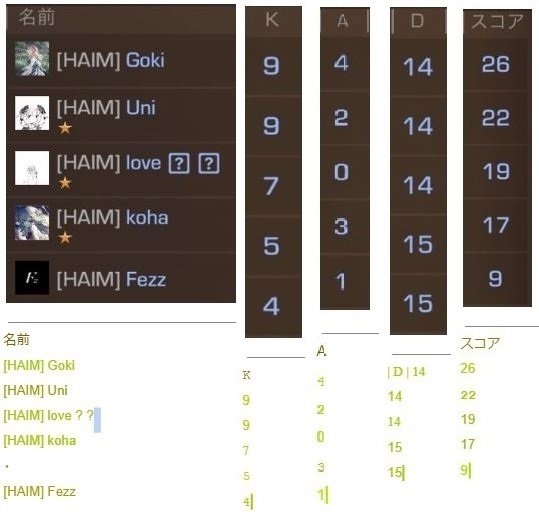
目論見通り、すべて正確に抽出できた。
ただ、いちいち画像を切り張りする手間を考えると、直接目視して手作業でスプレッドシートに入力するほうが早い。
精度の高い情報抽出機能をどのように実用化していくか、知恵の使いどころである。
eスポーツの観点からも、AIの観点からも、是非ご意見ください!
また、Google driveのユニークな機能も教えてください!
この記事が気に入ったらサポートをしてみませんか?