
Amazon SageMaker Autopilot を使ってみた

前回、こちらの記事でAmazon SageMaker Canvas を使ってみましたが、今回はAmazon SageMaker Autopilot を使って機械学習モデルの作成を行ったので、ご紹介したいと思います。
Amazon SageMaker Autopilot とは
Amazon SageMaker Autopilot は、自動化された機械学習機能で、データに基づいて最適な機械学習モデルを自動で構築してくれるサービスです。
AutoML (Automated Machine Learning) 機能を用いて、データ処理からモデルの実験、評価、デプロイまでを完全に自動で行ってくれるサービスとなっており、
複数モデルのトレーニングを自動で行い、パフォーマンスに基づいたモデルのランク付けから、最適なモデルの提案を行ってくれます。
Autopilot を使用すると、通常のモデルトレーニングに要するのに比べてわずかな時間で、最適なモデルの構築が可能となります。
Autopilot の特徴
Autopilot は、機械学習モデルを構築するために必要な、以下の工程を全て自動で行ってくれます。
Pre-processing:データの前処理
Candidate Definitions Generated:候補モデルの生成
Feature Engineering:特徴量エンジニアリング
Model Tuning:モデル調整
Explain ability Report Generated:説明可能性レポートの生成
Insights Report Generated:モデル性能レポートの生成
Deploying Model:モデルのデプロイ
これらの機能はトレーニングに使用するデータを選択し、実験に関する設定を行うだけで、あとは Autopilot が完全に自動で行ってくれます。
また、内部でどのような処理が行われたのか確認できる「候補生成ノートブック」や、データセットに関する分析情報が確認できる「データ探索ノートブック」の生成も可能となっており、
ノートブックを基に自身の専門知識を駆使して手動でモデル候補の最適化やデータ品質を向上させることができます。
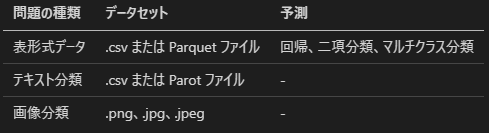
問題の種類
Autopilot では、「表形式データ」「画像分類」「テキスト分類」といった問題の種類に対応したモデルを作成できます。
それぞれ対応しているデータセットの形式は以下になります。
モデルの評価
Autopilot では、自動計算された指標に基づいてモデルの評価が行われます。
モデルの評価に使われる指標は以下になります。

「表形式データ」では、予測に応じて自動計算される指標が異なります。
回帰:InferenceLatency、MAE、MSE、R2、RMSE
二項分類:Accuracy、AUC、BalancedAccuracy、F1、InferenceLatency、LogLoss、Precision Recall
マルチクラス分類:Accuracy、BalancedAccuracy、F1macro、InferenceLatency、LogLoss、PrecisionMacro RecallMacro
実験を行う際には、それぞれの項目から objective metric(目的指標)を設定し、モデル評価の主要となる指標を指定することができます。
Amazon SageMaker Canvas との違い
Amazon SageMaker には、ノーコードで機械学習モデルの構築が行える Amazon SageMaker Canvas があります。
Canvas を使用して、カスタムモデルの作成を行うと、データ選択からモデルの作成・デプロイまでをノーコードで行うことができます。
Autopilot に似たサービスとなっていますが、以下のような違いがあります。

上記は、モデル作成までの一部の工程を比較したものですが、実際に両サービスを使用してみると、全く異なったアプローチを行っているのが感じられます。
Canvas は、GUI で操作可能な独自の環境が用意されており、モデル構築に必要な工程を直感的な操作だけで容易に行うことができ、ノーコードで利用可能なため、機械学習経験やコード知識のない方であっても簡単に利用できるサービスとなっています。
一方 Autopilot は、ローコードではあるものの実験に関する設定やモデルのデプロイ、予測には、ある程度の知識やコード理解などが必要な分、より高度なカスタマイズも可能となっています。
Autopilot の特徴としては、機械学習のタスクを自動化する AutoML 機能であり、機械学習プロジェクトの効率化を目的としたサービスとなっています。
ここからは、実際に Autopilot を使用して AutoML 機能を体験していきたいと思います。
利用方法
Autopilot は、Amazon SageMaker Studio から使用可能となっています。
なお本ブログでは Autopilot の利用手順に関する詳しい説明は省略致します。
詳しい説明は、AWS 開発者ガイド「Studio を使用してオートパイロット実験を作成します。」をご確認ください。
実験の作成
[AutoML] ページから `+ Create Autopilot Experiment` をクリックして新規実験を作成します。

実験の作成で行う項目は以下になります。
実験とデータの証明
ターゲットと特徴
トレーニング方法とアルゴリズム
デプロイと詳細設定
レビューと作成
実験とデータの証明では、実験名や入力データの指定を行います。
`Auto split data?` を指定すると、データの 80%をトレーニング用、20%を検証用に分割することができます。

ターゲットと特徴では、ターゲットとなるカラムの指定と学習する特徴の選択やデータ変換などが可能です。
`Sample weight(Optional)` は、オプションでデータセットのレコードに重み付けができます。

トレーニング方法とアルゴリズムでは、トレーニングオプションを選択します。`Auto` を指定するとデータセットのサイズに基づいてトレーニング方法を自動的に選択してくれます。

デプロイと詳細設定では、最もパフォーマンスの高いモデルを自動でデプロイするか選択できます。
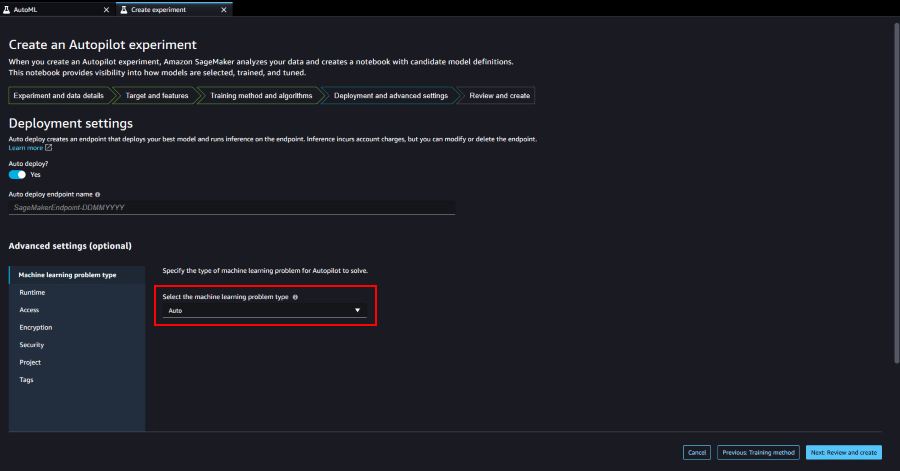
Autopilot は、問題の種類をデータセットから自動的に推測してくれるのですが、`Advanced setting(optional)` から手動で問題の種類を指定することも可能です。
レビューと作成で、ここまで行った設定を確認し実験の作成を実行します。
あとは各設定に基づいて Autopilot が完全に自動で処理を行ってくれます。
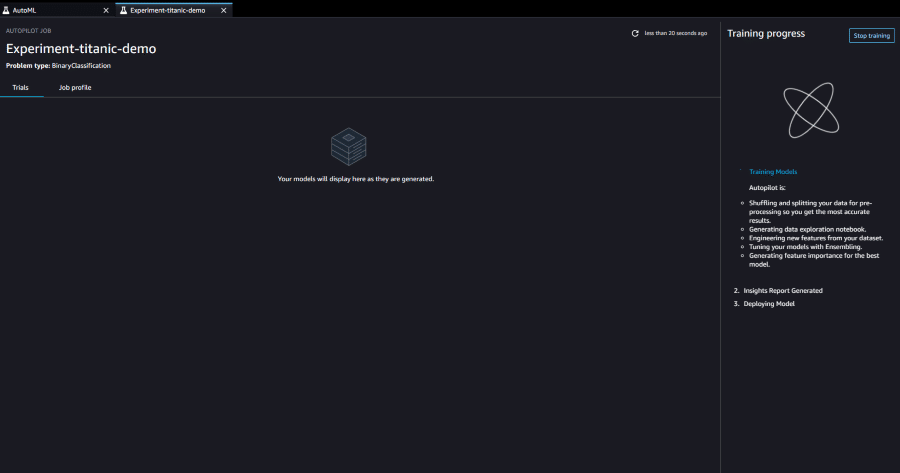
データセットの大きさによっても変わるのですが、実験には数時間かかる場合があります。
今回は「デプロイと詳細設定」にて、ランタイムを 10 分に指定して実行時間を制限しました。
こうして複数のモデル候補のトレーニングを行い、各モデルのパフォーマンスを評価してランク付けするまでを Autopilot が行ってくれます。
実験結果
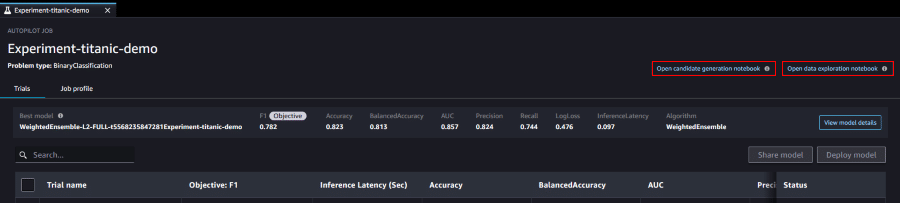
実験を開始すると、随時各モデルの評価とランク付けが行われ画面に表示されます。
`Best model` が一番上に表示され、各モデルの評価項目ごとの数値も確認することができます。

各モデルをクリックすると、モデルの詳細を確認することができます。
Autopilot が生成したレポートの確認も、こちらから行えるようになっています。
レポートには、予測に影響するデータの説明やモデルのパフォーマンスに関する情報などが含まれています。

Autopilot ジョブに、デプロイを含めることもできますが、最も評価の高かったモデルが自動的に選択されてしまいます。
モデルを選択してデプロイを行いたい場合は、実験結果画面からモデルを選択して、`Deploy model` をクリックしデプロイの設定を行います。
デプロイ設定では、リアルタイム推論かバッチ推論を選択し、エンドポイント名とインスタンスタイプ、レスポンス内容などを指定します。

デプロイ完了後は、Amazon SageMaker Studio 内の[Endpoints]から推論のテストを行うことができます。
しかし、こちらのテストでは JSON が使用されており、XGBoost で生成されたモデルはリクエストとして text/csv のコンテンツしか受け付けないため、
推論結果を確認したい場合は、新規でノートブックを作成しエンドポイントにリクエストを投げることで確認できます。
※今回使用する WeightedEnsemble は、CatBoost と XGBoost により構成されていました。
以下のコードを実行することで推論結果を取得することができました。
エンドポイントのステータス確認:
import sagemaker
import boto3
sagemaker_client = boto3.client('sagemaker', region_name='us-east-1')
endpoint_name = 'titanic-demo-endpoint'
status = sagemaker_client.describe_endpoint(EndpointName=endpoint_name)["EndpointStatus"]
print(status)リクエストとレスポンスの設定:
if status == "InService":
sm_runtime = boto3.Session().client('sagemaker-runtime')
content_type = "text/csv"
body = "1,35,135,1,0,0,0,1"
response = sm_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType=content_type,
Body=body
)
print(response['Body'].read().decode())推論結果:
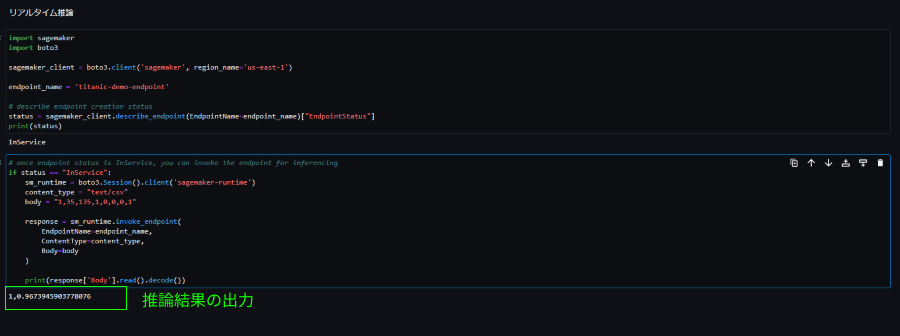
survived = 1(生存)/96.73%(確率)という結果が出力されました。
推論結果の取得で、少しつまずいたのですが、以下の開発者ガイドを参照することで無事結果を取得できました。
ノートブック
Autopilot では、データ解析後に Autopilot の内部で行われた処理が確認できる「候補生成ノートブック」や、データセットに関する分析情報が確認できる「データ探索ノートブック」が自動生成されます。
Amazon SageMaker Autopilot Candidate Definition Notebook
候補定義ノートブック:推奨される各前処理ステップ、アルゴリズムおよびハイパーパラメーターを含んだノートブック
このノートブック全体のコードを実行すると、ジョブの完了後に最適なモデル候補のみが表示されます。

Amazon SageMaker Autopilot Data Exploration Report
データ探索レポート:データに関する潜在的な問題についての洞察を含むデータ探索レポート
こちらのレポートでは、問題への対処方法も提案されています。

それぞれのノートブックを使用して、手動でモデルの検証を行ったり、データセットに関する情報から適切なデータ処理に役立てることができます。
以上が、Autopilot の利用方法となります。
まとめ
いかがでしたでしょうか?
Autopilot を利用すれば、データ処理からモデルの実験、評価、デプロイまでを、簡単な設定のみで完全に自動で行ってくれるのが確認できました。
また Autopilot は、レポートやノードブックといったデータ分析や内部処理に関するサポートが充実しているので、
自動化されたサービスでありながらも、可視性とカスタマイズ性に優れたサービスだと感じました。
気になった方は、ぜひ Amazon SageMaker Autopilot を利用してみてください。
この記事が気に入ったらサポートをしてみませんか?