
wikiHowから日本語要約データを作成してみた

※こちらの記事は、2020年7月2日にRetrieva TECH BLOGにて掲載された記事を再掲載したものとなります。
こんにちは。 カスタマーサクセス部リサーチャーの勝又です。 私はレトリバで自然言語処理、とくに要約や文法誤り訂正に関する研究の最新動向の調査・キャッチアップなどを行っております。
今回の記事ではKoupaee and Wang(※1)によって作成された英語要約データセットを参考に、日本語でも同様の要約データセットを作成した話をします。
現状の日本語要約データセット
執筆現在で私が知る限り、研究目的で使用可能な日本語要約データセットは次の2つです。
朝日新聞要約データ(JNC, JAMUL/JAMUL2020)(※2)
3行要約データセット(Livedoor News)(※3)
前者は新聞記事から対応する見出しを生成するデータセットで、後者は記事に対して3文で構成された要約が与えられています。 これらはどちらもニュース記事に対する要約のデータセットです。
このように、日本語要約データはニュース記事に関するものしか存在せず、それ以外の分野での要約性能の検証を行うことは難しい状況です。 そこで、今回新たにwikiHowのデータを利用した日本語要約データを作成しました。
wikiHowを利用したデータセット作成
Koupaee and Wangは英語のwikiHowから要約データを作成することを報告しています。 今回、私も同様に日本語wikiHowを用いて要約データ作成を試みました。
wikiHowの構造
wikiHowは構造化して記述されており、Koupaee and Wangはこの構造に注目して要約データを作成しました。 wikiHowは各ページに、いくつかの大段落(方法1,2..)を持ちます。 大段落の中には、小段落として記事と対応した段落見出しが存在します。 この組み合わせを利用し、要約データを作成します。
具体的には、次の図のように1つの大段落から記事と要約の組を抽出しています。 この図のように、記事と要約はそれぞれ各小段落内の記事と見出しを繋げたものを利用しています。 たとえば、小段落の見出しとして、手を洗う、マスクの状態を確認するとあれば、作成する要約は手を洗う。マスクの状態を確認する。となっています。

(この図はwikiHowの医療用マスクを着用する方法に対して作成した例です。)
wikiHowから作成した要約データの特徴
今回作成したデータは以下の特徴を持ちます。
要約の文数が記事によってばらつく
記事の上の方だけを利用しても、要約として良いものになりにくい
要約として、本来各小段落ごとにまとまっていたものをくっつけているので、入力記事の上の方だけを要約に使った場合、最終段落付近の要約は困難になります。
一方で、ニュース記事などは重要な文は記事の上に来ることが多いです。
wikiHowから作成したデータの統計情報
今回作成したwikiHowデータセットの大きさなどは次の通りです。
データサイズ
ここでのサイズは要約データの(記事, 要約)の対の数を指します。
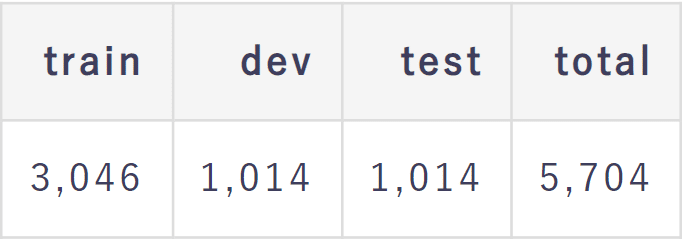
(train/dev/testは3:1:1になるようにランダムに分割しています。)
単語数など
要約データ内の1文あたりの平均単語数を文長としています。 (単語分割にはMeCab(IPADIC)を使用しています。)

簡単な実験
最後に、今回作成したデータで簡単な要約実験を行いました。
手法
学習データがそれほどないため、今回は教師なしの抽出型要約手法を試しました。 具体的には次の通りです。
Lead-3(記事の上から3文までを要約とみなす手法)
LexRank(※4)
Centroid(※5)
ハイパーパラメーターはdevデータで探索を行い、もっとも良かったものを使用しています。 教師なし手法3番のCentroidでは公開されているこちらの単語分散表現を使用しました。
実験結果
ROUGE-1, 2, Lで評価を行いました。(すべてF値)
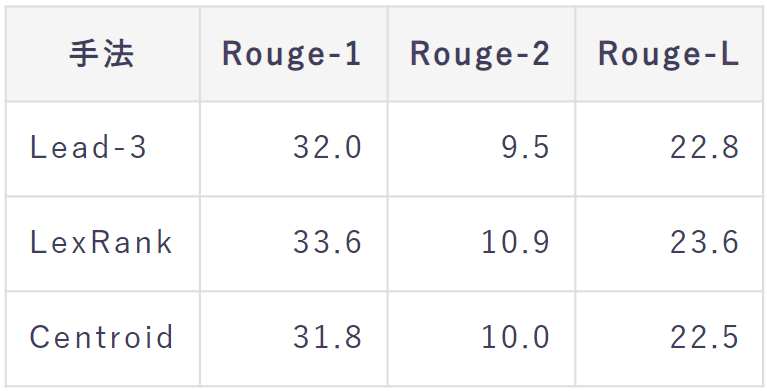
この結果から、教師なしの中ではLexRankが一番良いことがわかります。 これは、要約として重要な文が記事の上の方だけでなく、さまざまな箇所に位置しているからだと考えられます。
まとめ
今回、日本語の要約データセットとして、wikiHowから抽出したデータを作成しました。 学習データは少量になってしまいましたが、ニュース分野以外の要約データを作成する目的は達成できたと思います。 今後も要約に使えるデータや、要約手法の検討に取り組んでいく予定です。
今回作成したデータはこちらで使用可能です。(CC-BY-NC-SA): https://github.com/Katsumata420/wikihow_japanese
Koupaee and Wang. WikiHow: A Large Scale Text Summarization Dataset. [paper]↩
人見雄太, 田口雄哉, 田森秀明, 菊田洸, 西鳥羽二郎, 岡崎直観, 乾健太郎, 奥村学. 出力長制御を考慮した見出し生成モデルのための大規模コーパス. [paper]↩
Erkan and Radev. LexRank: Graph-based Lexical Centrality as Salience in Text Summarization. [paper]↩
Rossiello, Basile and Semeraro. Centroid-based Text Summarization through Compositionality of Word Embeddings. [paper]↩