
Stable Diffusion WebUI 初心者教本

ごあいさつ
初めましての方は初めまして、すでに知っている方はこんにちは。
かたらぎと申します。
私が画像生成AIを始めたのはNovelAIが2022年10月にリリースされてから約一か月後の11月7日ごろでした。当時は時々twitterに画像を投稿するくらいでしたが、NovelAIでの研究の成果を発表した際に多くの人の目に留まりたくさんの方との交流が始まりました。そして、当時から人気だったあいおえおえかきの先生、らけしで先生、シトラス先生、Morito先生の5人でNovelAI初心者教本を発表します。
【特報】
— かたらぎ@NovelAI初心者教本 (@redraw_0) December 23, 2022
NovelAI初心者教本(プレリリース版:92ページ)をここに発表させていただきます!
AI術師の大先輩方による魅力的な巻頭作品集!
初心者向けの解説と、実践的な画風の紹介を画像とプロンプトで解説しています!
イラストAI、はじめの一歩に是非どうぞ!https://t.co/BO9UG986j1
しかし、NovelAIも最近では人気が下火になり、最近ではStable Diffusion WebUIを用いた自分のパソコンで画像を生成する方式が流行っています。導入の難易度も下がってきており、以前よりは簡単に環境を用意できるようになりましたが一つ避けては通れない問題があります。
NovelAIコミュニティの皆さま
— NovelAI (@novelaiofficial) October 8, 2022
いつもNovelAIをご利用いただき誠にありがとうございます。
ご迷惑をおかけし申し訳ごぜいません。
2022年10月6日に弊社のGitHubとセカンダリリポジトリに権限のない第三者による不正なアクセスを許してしまいました。 https://t.co/FuIzzZSUQh
それがNovelAIのモデルデータがハッキングによって流出してしまったことによるモデルのリーク派生問題です。現在この流出したモデルが非常に多くのモデルの基礎になってしまっている、あるいはその可能性が疑われるため初心者がその危険を避けることは困難です。
実際、多くのWebUIの導入方法を解説するサイトが盗用の疑われているAnythingV3やリークされたモデルをそのまま使っていると発表しているOrangeMixシリーズなどを使って使い方を説明したりしています。もちろん国内でこれらのモデルを使用したことにより罰せられた判例は存在しませんが、画像生成AIをローカルで始める方に最初にお勧めしていいモデルではないと思っています。
そこでリーク派生モデルを実用的に組み込むことがほぼ不可能なSD2.1系のモデルで比較的扱いやすいReplicant-V1.0というモデルを用いてSD WebUIを解説していきたいと思います。
Stable Diffusion WebUI 初心者教本
ローカルの導入

NovelAIやHolaraAI・niji・journey等はインターネットを経由してサーバー上にあるGPU(グラフィックボード)で画像を生成していますが、WebUIは自分が持っているパソコンのGPU(グラフィックボード)を使って画像を生成するアプリです。
上記のフローチャートからご自身の環境に最適なものを選んでください。この記事ではStable Diffusion WebUI Flat版とAUTOMATIC1111版の導入方法を解説していきます。残念ながらgoogle colab版などのインターネット経由やNMKD版に関しては後日解説していきたいと思います。ご了承ください。
自分のパソコンにGPUが搭載されているかは下記の手順で確認してください。
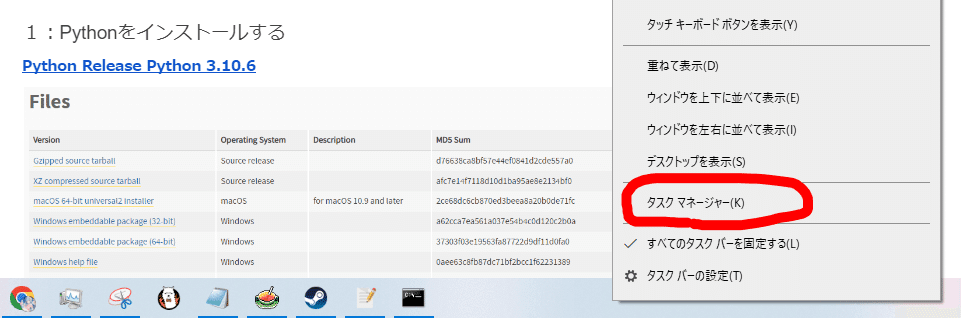
まず、タスクバーを右クリックしタスクマネージャーを開きます。

自分のパソコンにGPUが搭載されている場合、GPUの欄が出てきます。一部のパソコンでは搭載されていないためこの表示が出ないことがあります。
どのグラボを選べばいいのか?
どのGPUがいいのかわからないという方は、私が生成に最適なグラボはどれかツイートしたときのリプ欄が参考になると思います。
5万円台で買えるRTX3060(12GB)や、私が使っている中古で7万円台だったRTX A4000(16GB)、23万ではあるもののRTX4090と同じVRAM量のRTX3090(24GB)、価格は30万円なものの長期的な目で見ればもっともよい投資といえるRTX4090(24GB)などがお勧めという声が多かったです。
画像生成はGPUのVRAM量が命ともいえるので同じシリーズでもVRAMの多い方を選んだ方がいいでしょう。
ローカルで画像生成AIを使いたい時のおすすめグラボってどれがいんだろうな…?
— かたらぎ@NovelAI初心者教本 (@redraw_0) December 19, 2022
RTX4090とかは高すぎるし…
PCケース的にカード長は373mmまで行けるのでその範囲で良いのないかなぁ…
価格ドットコムあたりで探してみるか…
はじめまして、検証の悪魔です。
— ₿ え̤̮み̤̮ゅ̤̮ふ̤̮ぇ̤̮ず̤̮ ₿ 🌎 (@EmilyPhase) December 19, 2022
他の方もおっしゃってますが、RTX3060 VRAM12 GBが一番コスパ良くておすすめです。
RTX A4000も検討されているようでなかなかお目が高いですね!
良いローカルライフを👍
こんばんは。参考になるか分かりませんが、 RTX3070(RAM 8GB)を使用しています。SDのwebui(AUTOMATIC1111)で主に768×1028くらいの画像を生成しているのですが、RAM不足で生成出来ない時がときどきあります。学習をすることも考えるとRAMは12GBのものがいいのかなと思っています。
— ぱるちさん🔞 (@prtprt419) December 19, 2022
わたしは悩んだ結果中古の3090を入手しました。
— むじな (@mujina) December 19, 2022
キーになるのはVRAM容量(生成解像度に比例してメモリ使用量が上がる。1024*1920で20.3GB)なので、可能なら中古の3090もしくはA5000が狙い目かと思います
ただしケースに納まるか、長さだけじゃなく高さも要チェックですが(; ・`д・´)
なんだかんだで本格的にやるならRTX4090が性能を考えると実はコスパ良かったりするから難しいですね……
— ステスロス@創作/画像生成AI/雑学RT (@StelsRay) December 19, 2022
Stable Diffusion WebUI Flat版
WebUIのインストールは今Flat版が一番簡単です。上記のリンクから「download」を押してください。(現状ではWindowsにしか対応していません)

ダウンロードが完了したらインストーラーを起動してください。
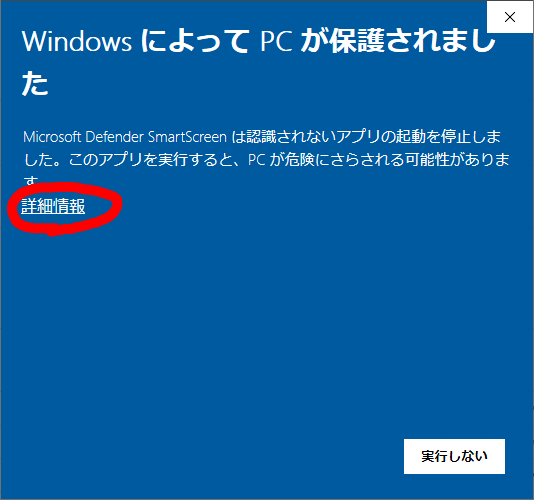

このような警告が出ることがあるので詳細情報→実行を選択してください。
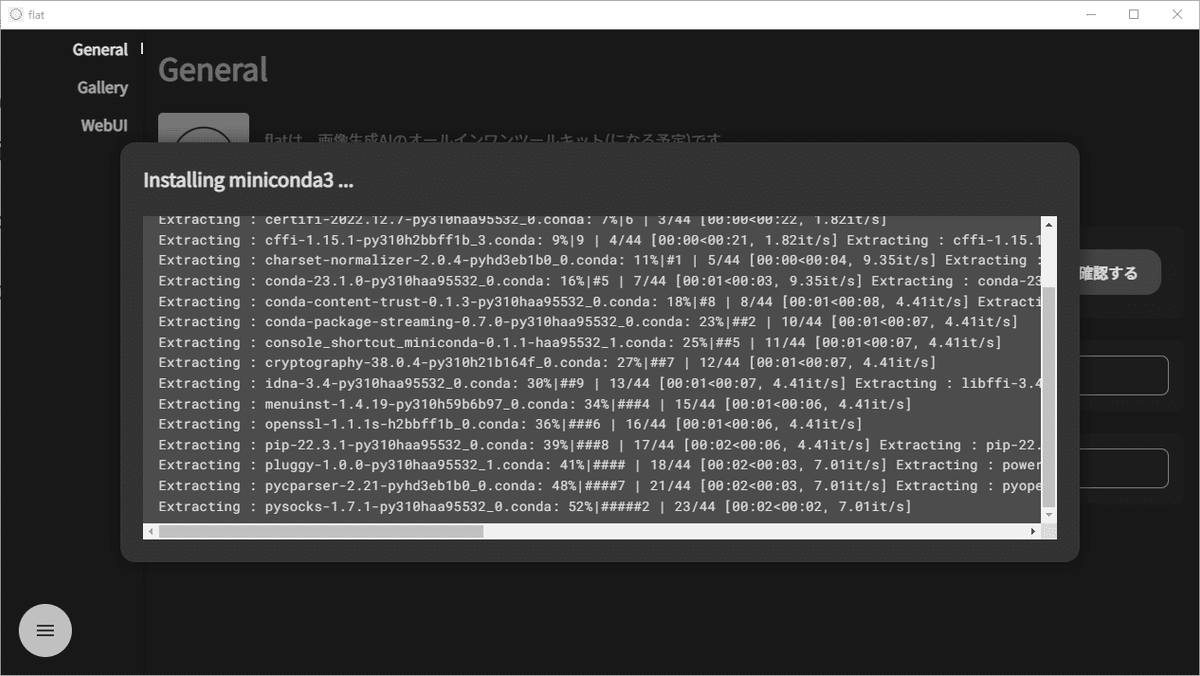
インストールが始まります。そのままお待ちください。
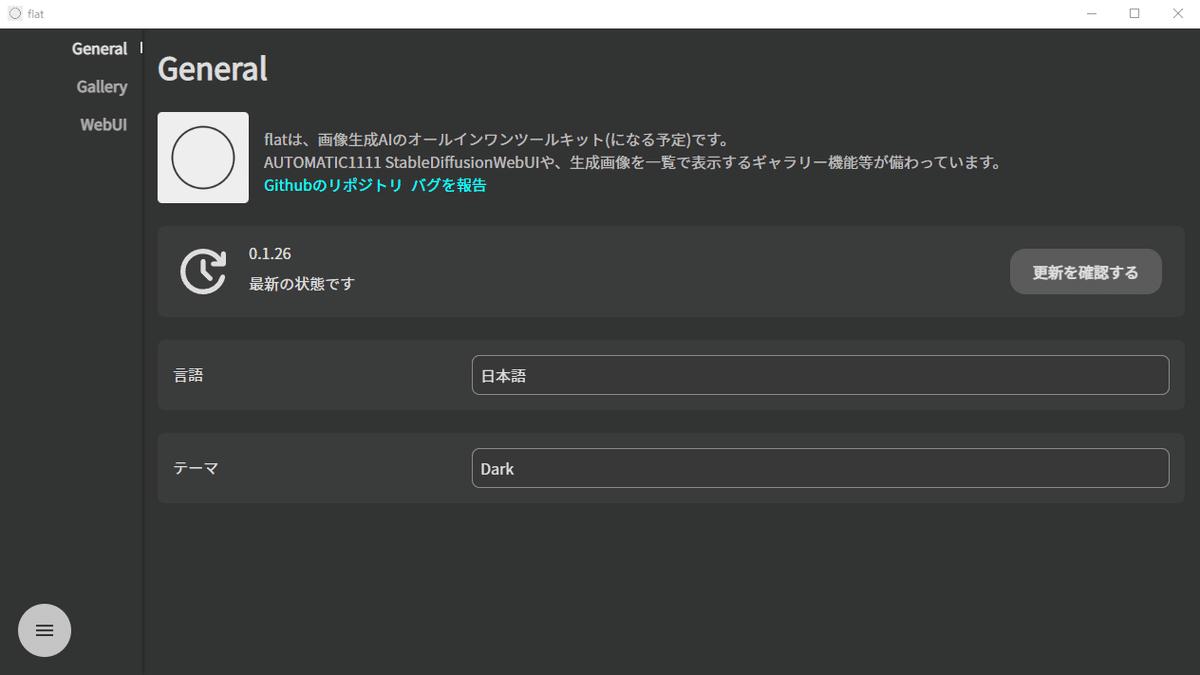
インストールが完了するとこのような画面になります。

赤丸で囲まれた「WebUI」タブに移動するとこのような画面が出るので「インストールする」を選択します。
こちらもインストールが終わるまで待っていてください。
インストールが終了したら「WebUIのフォルダを開く」を選択してください。

「models」フォルダを開きます。
フォルダ内の「Stable-diffusion」を開きます

ここにダウンロードしてきたモデルを入れてください。

モデルを配置したらこの画面に戻り、赤丸の起動ボタンを押します。

起動するときにこのような警告が出てくることがあります。特に理由がない場合、プライベートネットワークにチェックを入れて「アクセスを許可する」を選択してください。お使いの環境にもよりますが、起動には数分かかる場合があるので気長に待ちましょう。

WebUIの起動に成功数するとこのような画面が出てきます。(ナイトモードのように回りが黒いですが動作に支障はありません)
これでWebUI Flat版の導入は完了です。
SD WebUI AUTOMATIC1111版
1:Pythonをインストールする
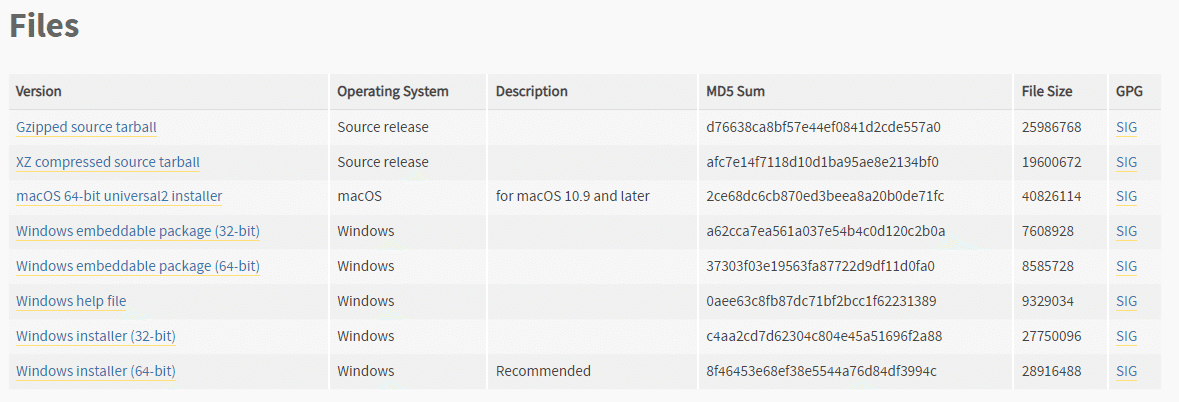
上記のサイトにアクセスして下にスクロールしていくと上記のような表があります。Windowsの場合はWindows installer版をダウンロードしてください。バージョンが3.10.6以外(2023年3月25日現在)だと正常に動かないことがあるので気を付けて下さい。
ダウンロードしたファイルを実行すると「このアプリがデバイスに変更を加えることを許可しますか?」と聞かれるので「はい」を押してください。
インストールするときには「Add Python 3.10 to PATH」という項目にチェックを入れましょう。デフォルトではチェックがついていないので気を付けて下さい。もし、チェックをつけずにインストールしてしまった場合、WebUIが起動できない場合があります。
再度インストーラーを立ち上げ、以下の操作をしてください。

「Modify」を選択してください。

2個目のインストール設定項目に「Add python to environment variables」あるので、これにチェックが入っていない場合はチェックを入れて「install」を選択します。
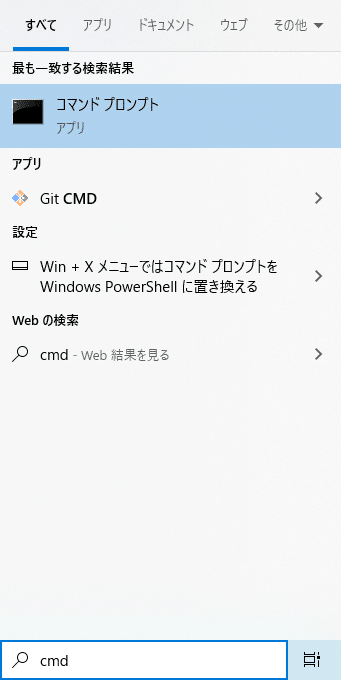
windowsの検索欄に「cmd」と入力してコマンドプロンプトを開き、pythonがちゃんとインストールされているか確認しましょう。コマンドは「python -V」と入力してください。
次のように表示されれば成功です。

※pythonのインストールに成功した時の表示
2:gitのインストール

上記のサイトにアクセスすると画像のようなサイトが表示されるので、downloadを選択してください。任意の場所にファイルをダウンロードします。完了したらインストールを開始してください。
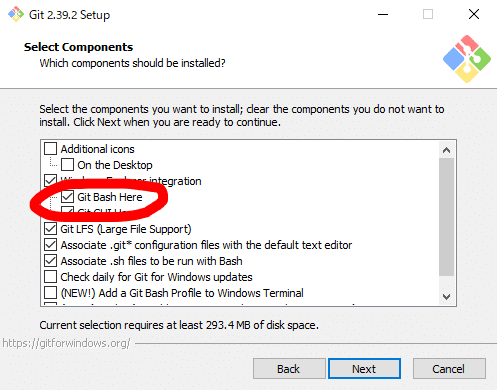
セットアップの項目に「git Bash Here」があるのでこちらにチェックを付けます。あとはnextを押していくだけです。特に設定することはないのでインストールが完了するのを待ちましょう。
3:WebUIのインストール
WebUIをインストールする方法は二種類あります。先ほどインストールしたgitを使ってインストールする方法とZIPでdownloadし、任意の場所で解凍する方法です。
gitを使ってインストール
インストールしたいフォルダを開きます。任意の場所で大丈夫ですがあまりフォルダアドレスが長くならない場所にしましょう。また、できるならフォルダアドレスに日本語を含まない方が好ましいです。
また、作業で頻繁に開くのでフォルダのショートカットを作っていつでも開けるようにしておくことをお勧めします。
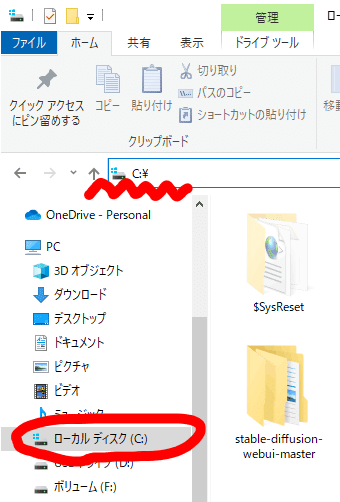
例)「C:\」などのCドライブ直下なら短く、必ず日本語を含まない場所
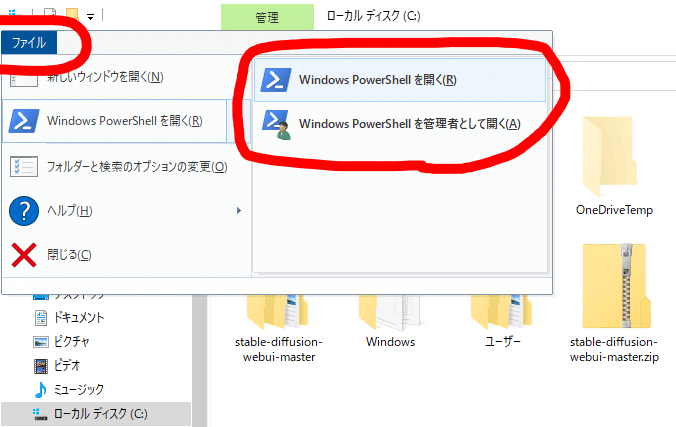
インストールしたいフォルダで「ファイル」タブを選択すると「Windows Power Shell」を開きます。

git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
と入力してください。後は勝手にダウンロードが始まります。割とすぐ終わります。
ZIPでダウンロードして解凍
上記のリンクからSDWebUIをダウンロードしてください。
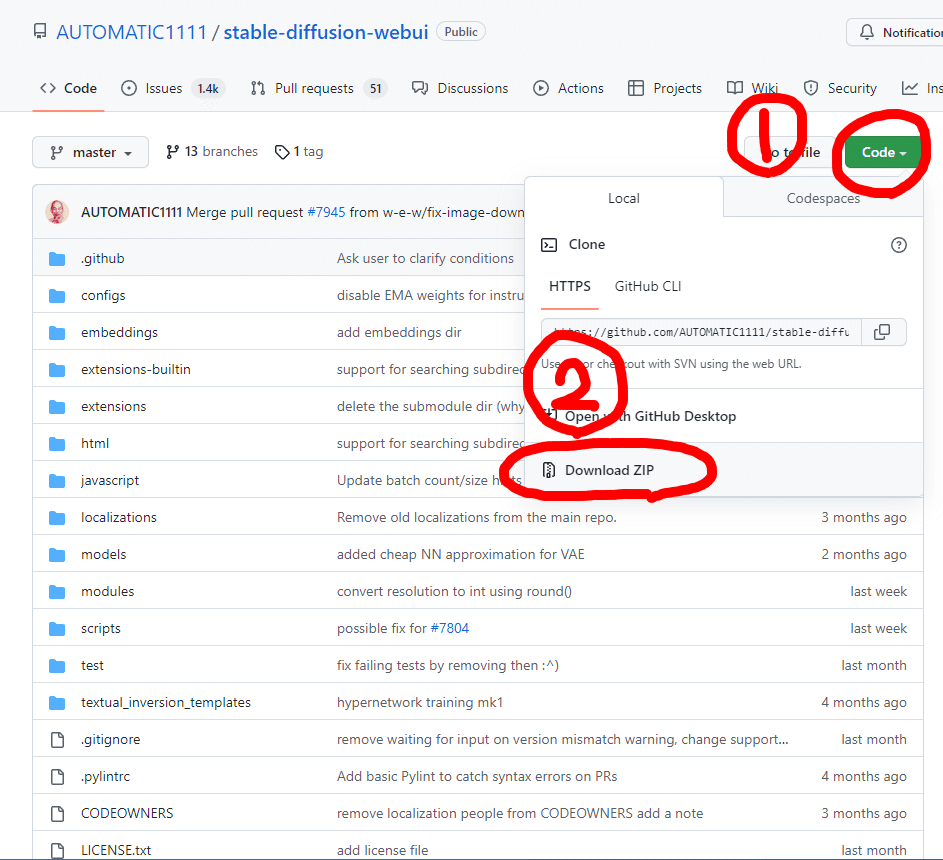
ダウンロードしたファイルを任意の場所に置いて解凍してください。
次の工程からはgitからインストールした場合も、ZIPでインストールした場合も同じです。
次に拡張子を表示する設定をしましょう。拡張子とはパソコンがこのファイルはどのアプリで開けばいいのか識別するための符号です。画像ファイルには「.jpg」や「.png」がついていますし、実行するファイルには「.exe」がついています。見えていないという人は見えるように設定します。
もし表示されていない場合は、今後の設定のためにも表示する設定にすることをお勧めします。

まずエクスプローラーを開いて画面上部の表示タブを開きます。次にファイル名拡張子のチェックボックスにチェックを入れます。これで、すべてのファイルに拡張子が表示されるようになりました。
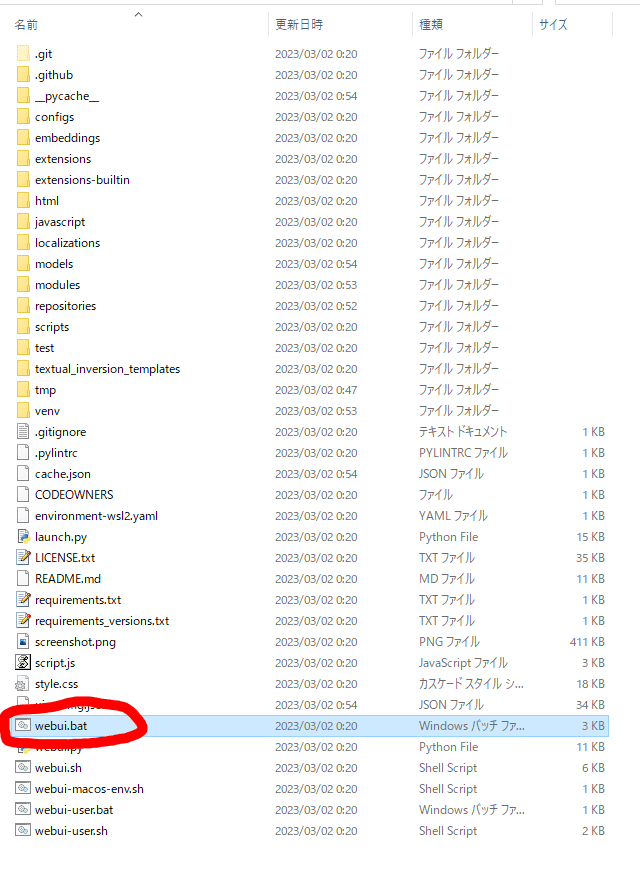
インストールしたフォルダを見てみると「webui.bat」というファイルがあります。こちらで追加のインストールをしていきます。初回の起動には時間がかかるので気長に待ちましょう。
正常に終了すると「To create a public link, set `share=True` in `launch()`.」と表示されます。

例)正常起動した際のコマンドプロンプトの例
下から3行目のURL: http://127.0.0.1:7861
google chromeやfirefoxなどのウェブブラウザから上記のアドレスにアクセスしてみましょう。コピーをして検索窓に入れるだけです。毎回入れるのは面倒なのでブックマークをしておくといいでしょう。もし接続がうまくいかない場合は「webui.bat」をいったん閉じてから再度開くか、
「Webui-user.bat」を開いてみましょう。正常起動時のメッセージは同じです。このコマンドプロンプトを閉じてしまうと画像生成はできないのでそのままにしておきましょう。
毎回この場所を開いて「Webui-user.bat」を起動するのは面倒くさいのでショートカットを作ってデスクトップに置いたり、タスクバーなどにピン止めしておきましょう。
日本語化とプルダウンメニューの表示

例)正常起動した際の画面
SDWebUIが起動に成功すると上記のような画面が表示されます。画面上の要素が英語で表示されていて分かりづらい上にこのままでは不十分なので日本語化とメニューの増設を行います。

まず画面上部の「Extensions」タブ →「Install from URL」を選択します。「URL for extensions’s git repository」に以下のURLをコピー&貼り付けしてください。
https://github.com/Katsuyuki-Karasawa/stable-diffusion-webui-localization-ja_JP.git
貼り付けたら「Install」をクリックします。

「Installed」タブに戻って「Apply and restart UI」をクリックします。画面が白くなり拡張機能が更新され次のようなメッセージが下に表示されます。
Installed into F:\SDwebUI\stable-diffusion-webui\extensions\stable-diffusion-webui-localization-ja_JP. Use Installed tab to restart.
ですが、まだ日本語にはなりません。

次に「settings」を選択し、右側の一覧から「User interface」を探します。

①と書かれたところに次の設定をコピー&貼り付けしてください。元からある文字列を消す必要はありません。
追加する文字列
,sd_vae,sd_hypernetwork,sd_hypernetwork_strength,CLIP_stop_at_last_layers
もし、もとからあるものを消してしまった場合はこちらをコピーしてください。
sd_model_checkpoint,sd_vae,sd_hypernetwork,sd_hypernetwork_strength,CLIP_stop_at_last_layers
また②が初期状態では「none」になっているので「ja_JP」に直してください。表示されない場合はインストールが失敗している可能性があるので、この項目の最初に戻って「Extensions」タブから手順を繰り返してください。
日本語化に成功するとこのようになります。また、上部に切り替えメニューや設定項目がいくつか追加されます。
高速化設定
画像生成を高速化する簡単な設定があるのでご紹介します。
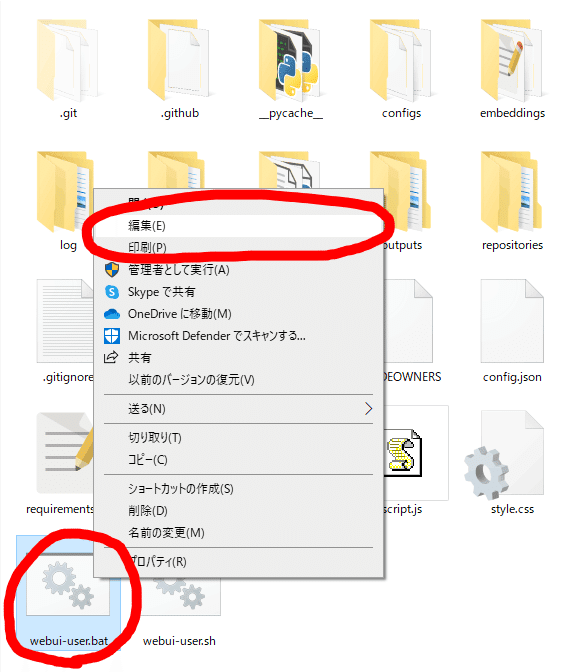
まずは、起動に使う「webui-user.bat」を右クリックして編集を開きます。プログラムを指定して起動する場合はメモ帳などを指定してください。

開いたら画像のように「set COMMANDLINE_ARGS=」の後に「--xformers」とコピー&貼り付けしてしてください。
環境:RTX A400
ステップ数:20

私のパソコン環境で比較してみましたが後述する設定の違いによって2~3倍近くの生成速度の差があることがわかりました。生成速度は非常に重要なのでぜひ設定しておいてください。
次の章では各種ボタンの意味と機能について軽く解説します。
SD WebUIのtxt2imgの解説

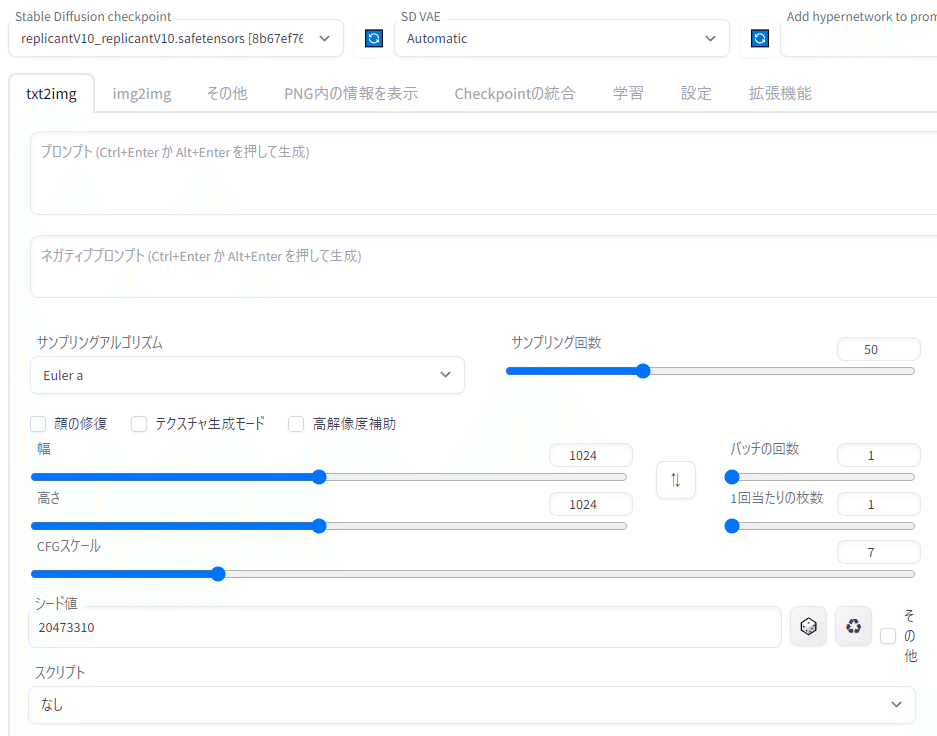
①:Stable Diffusion checkpoint
ここにモデル名が表示されます。モデルを切り替えることにより作風をアニメ塗り風、リアル塗り風、実写風などに変えることができます。
②:SD VAE
VAEとは生成された画像の品質を向上させるファイルのことです。大抵のモデルには付属のVAEがありますが、名前を変えて流用しているものがほとんどなので、特に推奨されているものがない限り、いくつか有名なものをダウンロードしておくだけで大抵は十分です。このメニューがない場合、ダウンロードしてきたVAEをモデルのファイルと同じ名前にする必要があります。
モデルとVAEとは
SDWebUIにおいてモデル(checkpointとも呼ばれる)とは画像を生成するのに必要なファイルを指します。例えるなら絵を作るための設計図のようなものです。これを変えることにより様々な画風や作風を変えることが可能です。VAEは画像生成の仕組みの中で使われるものですが詳しく知る必要は特にありません。絵の色味に関係していて、多くの場合絵のくすみや色が薄いといった問題を解決するという認識で大丈夫です。
また配布サイトはhuggingfaceやCivitai等があります。
では、実際にモデルをダウンロードしてみましょう。例では最新のSD2.1系を利用した高精細のモデルReplicant-V1.0を使ってみます。
Hugging FaceとCivitaiどちらからダウンロードしてもモデルは同じですが、VAEをダウンロードできるのはHugging Faceのみです。
Hugging Face
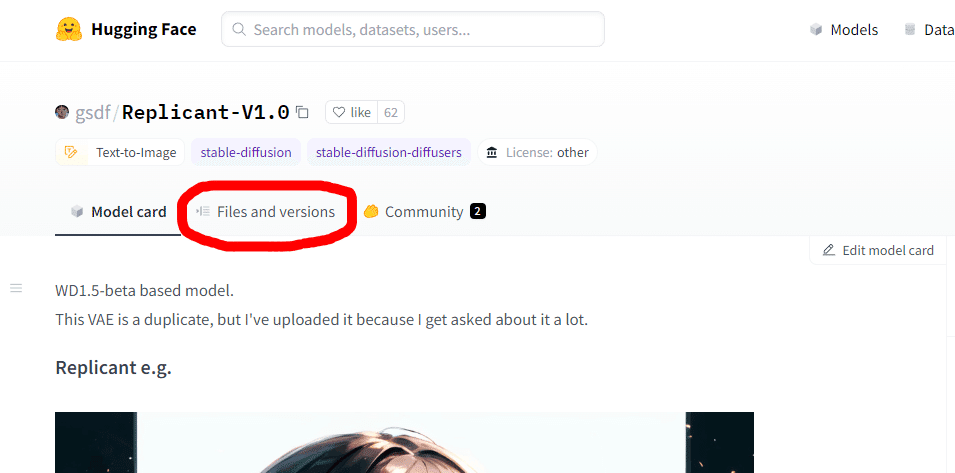
Civita


Hugging Faceで公開されているファイルから各ファイルの概要を説明していきます。
まず、ReplicantV1.0には2つのバージョンがあります。無印(表記はないですがおそらくfp32)とfp16版です。fp32版とfp16版の違いは大きく2つあります。モデルの容量と画像の生成速度・最大解像度、完成度です。fp16版の方がモデルの容量が少なく消費するGPUのVRAMが少ないため画像の生成速度・最大解像度がfp32版より向上します。画像の完成度が少し下がるなどのデメリットはありますが、生成速度を犠牲にするほどの差はないのでfp16版の方が良いでしょう。
モデルは「models」フォルダを選択して出てきた…
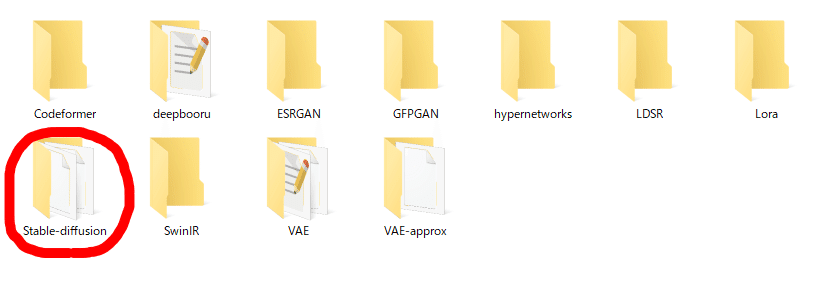
「Stable-diffusion」のフォルダに入れます。

VAEは先ほど述べた通り絵の色味を改善するのに使われます。こちらも特に理由がない限りダウンロードしておきましょう。配置する場所はモデルを配置する「Stable-diffusion」フォルダと同じ場所にある「VAE」フォルダーに入れましょう。

一番下に「re-badprompt.safetensors」というファイルがあります。これは「エンベディング」と呼ばれています。「re-badprompt」とネガティブプロンプト(④)に入れることによって、長いネガティブを入れることなく簡単に絵のクオリティーを上げられます。このエンベディングは「Webui-user.bat」があるフォルダの「embeddings」フォルダーに入れます。「ReplicantV1.0」の場合これをネガティブプロンプトに入れないと絵の品質に影響が出てきます。
ここまでで、画像を生成する準備はいったん整いました。では、プロンプトと呼ばれるAIにどのような絵を描いてほしいのか指示する命令(呪文とも呼ばれる)を書いたり設定したりして実際に画像を生成してみましょう。
とはいえ、初心者の方であればどのようなプロンプトを入力し、どのような設定で画像を作成するか分からないと思うのでひとまずは手順を解説していきたいと思います。
試しに先ほどダウンロードしたReplicant-V1.0のcivitaiのページを見てみましょう。トップに表示されている画像を拡大表示するとプロンプトや設定などが出てきます。
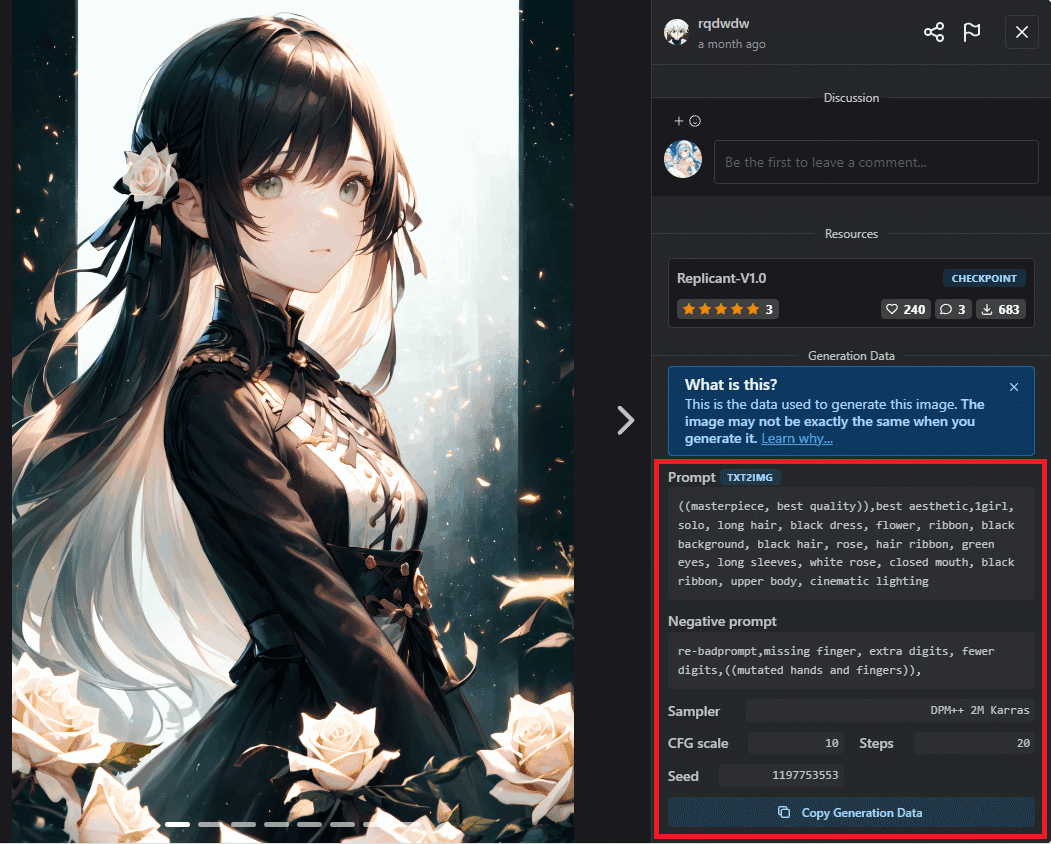

まず、①でモデルとVAEが正しく選択されているか確認しましょう。プルダウンメニューを見てもモデルやVAEがない場合、横の青いボタンを押すことで表示を更新させることができます。WebUIの起動中にモデルを追加したりするとこの動作が必要になります。もし、モデルやVAEの表示が出てこない場合は入れるフォルダを間違えていないかどうかなどを確かめてください。
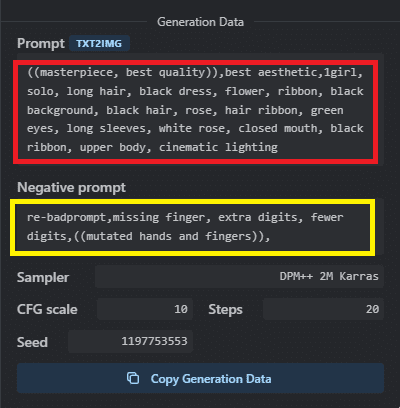
次に②に赤枠で囲まれた部分のプロンプト、③に黄色の枠で囲まれた部分のネガティブプロンプトをコピー&貼り付けします。
④のサンプリングアルゴリズムはプルダウンメニューの中から「DPM++ 2M Karras」と書かれたものを選んでください。⑤のCFGスケールではスライドバーを動かして10に設定しましょう。
画像サイズは使っているパソコンの性能に合わせて適宜変更してください。今回は768×1024で生成しますが、512×768などのサイズもおすすめです。
準備が整いましたので画面右側の「生成」ボタンを押して画像生成を開始してみましょう。進行状況が青色のバーで表示され大体の残り時間が表示されます。

少し待つと画像が完成します。画像をクリックすると拡大表示することができ、もう一度クリックするとアップで表示されます。画像生成のおおまかな手順はこの通りです。
生成ボタンを右クリックすると「Generate forever」というメニューが出てきます。これは次に「cancel generate forever」を押すまで同じ設定で連続で生成し続ける機能です。
これにより寝ている間や外出中に、たくさんの画像を生成できるようになりますが、連続生成中はGPUがかなり熱くなることが予想されるので一度家にいるときに試してみて大丈夫そうであれば使用してください。

生成した画像は画像赤丸のフォルダボタンを押して開いたフォルダ(画面には直接現れないのでタスクバーなどより表示してください)に保存されています。初期設定では日付ごとに生成結果が保存されています。
次にプロンプトや各種設定について詳しく解説していきます。

③:プロンプト(prompt)
プロンプトとは画像生成AIにどんな画像を作ってほしいのか散文あるいはタグ(短い単語)の羅列で命令する部分です。英語で入力しますが難しく考えることなく、google翻訳やDeepL翻訳を使っても大丈夫です。モデルによっては命令の形式が違いますし、命令を聞いてくれる度合いが違いますが、プロンプトに入力するときは「 , 」(コンマ)を使って単語や文節を区切ります。
先ほどのプロンプトの意味をここで解説していきますが、ここですべてを覚える必要はありません。少しずつ感覚をつかんでください。
クオリティータグ
((masterpiece, best quality)),best aesthetic,
訳:傑作、最高品質、最高の美的感覚
プロンプトの先頭にはクオリティータグと呼ばれる絵の品質を高める単語が並んでいます。これはReplicantのもとになった「waifu-diffusion1.5」というモデルに由来します。ここにはありませんがおすすめのクオリティータグを2つご紹介します。

人物の特徴
1girl, solo, long hair, black dress, flower, ribbon, black background, black hair, rose, hair ribbon, green eyes, long sleeves,
訳:一人の女の子、ソロ、ロングヘア、黒いドレス、花、リボン、黒背景、黒髪、バラ、ヘアリボン、緑の目、長袖
次に人物の特徴が列挙されています。「1girl, solo」は複数人を描画させたくないときに使うので二人以上出したいときは「2girls」などに書き換えます。また、髪を短くしたい場合は「short hair」、制服を着てもらいたい場合は「school uniform」、髪の色を金髪に変えたい場合は「blonde hair」、半袖にしたい場合は「short sleeves」などにしてください。
背景にあるもの・構図など
white rose, closed mouth, black ribbon, upper body, cinematic lighting
訳:白いバラ、閉じた口、黒いリボン、上半身、シネマティックライティング
最後には背景にあるものや小物、構図、光の指定などが列挙されています。表情を変えてみたり身に着けるものを追加してみることができます。
プロンプトを用いて指示をしていくと、服や髪、目の色を間違えたり、指定した構図にならないなど、うまく命令を聞いてくれないことがあります。その場合は()を使って単語や文を強調することができます。クオリティータグの部分では((masterpiece, best quality))と二重に使われていますがこれは約1.2倍を意味しています。
しかし、()を多くすると見づらくなってしまうので表記は(prompt:1.2)と単語と強調したい倍数を「:」(半角コロン)で分けて書く場合が一般的です。また、単語を弱体化したいときは[prompt]を[]で囲みます。これで約0.9倍になります。もっと下げたい場合は(prompt:0.25)と記述できます。これは単語の重要度を1/4(25%)程度まで減らすことができます。
キーボード入力する際にpromptを範囲選択してから「Ctrl+↑または↓」を押すと自動でこの表記を入力してくれます。
ただ、この値は普段特に意識する必要はなく、大抵強調したい単語に:1.3や:1.5といった強調を施すだけで大抵は十分です。
人物の特徴
1girl, solo, long hair, black dress, flower, ribbon, black background, black hair, rose, hair ribbon, green eyes, long sleeves,
訳:一人の女の子、ソロ、ロングヘア、黒いドレス、花、リボン、黒背景、黒髪、バラ、ヘアリボン、緑の目、長袖
次に人物の特徴が列挙されています。「1girl, solo」は複数人を描画させたくないときに使うので二人以上出したいときは「2girls」などに書き換えます。また、髪を短くしたい場合は「short hair」、制服を着てもらいたい場合は「school uniform」、髪の色を金髪に変えたい場合は「blonde hair」、半袖にしたい場合は「short sleeves」などにしてください。
背景にあるもの・構図など
white rose, closed mouth, black ribbon, upper body, cinematic lighting
訳:白いバラ、閉じた口、黒いリボン、上半身、シネマティックライティング
最後には背景にあるものや小物、構図、光の指定などが列挙されています。表情を変えてみたり身に着けるものを追加してみることができます。
プロンプトを用いて指示をしていくと、服や髪、目の色を間違えたり、指定した構図にならないなど、うまく命令を聞いてくれないことがあります。その場合は()を使って単語や文を強調することができます。クオリティータグの部分では((masterpiece, best quality))と二重に使われていますがこれは約1.2倍を意味しています。
しかし、()を多くすると見づらくなってしまうので表記は(prompt:1.2)と単語と強調したい倍数を「:」(半角コロン)で分けて書く場合が一般的です。また、単語を弱体化したいときは[prompt]を[]で囲みます。これで約0.9倍になります。もっと下げたい場合は(prompt:0.25)と記述できます。これは単語の重要度を1/4(25%)程度まで減らすことができます。
キーボード入力する際にpromptを範囲選択してから「Ctrl+↑または↓」を押すと自動でこの表記を入力してくれます。
ただ、この値は普段特に意識する必要はなく、大抵強調したい単語に:1.3や:1.5といった強調を施すだけで大抵は十分です。

④:ネガティブプロンプト(negative prompt)
ネガティブプロンプトではAIに描写してほしくない要素を羅列します。古いモデル等では長いネガティブプロンプトが好まれる傾向にありましたが、最近のモデルでは短くなっていることが多いです。
プロンプトに入力するときと同じように「,」(コンマ)を使って単語や文節を区切ります。先ほど入力したネガティブプロンプトの意味について解説します。
エンベディングの呼び出し
re-badprompt,
先ほど入れたエンベディングを呼び出します。特に理由がなければ常に入れておきましょう。ただ、モデルを切り替えたりする場合はその限りではありません。
指の崩壊を防ぐ
missing finger, extra digits, fewer digits,((mutated hands and fingers)),
訳:指がない、指が余っている、指が少ない、手や指が変異している
手や指はAIが特に苦手とする部分です。ネガティブプロンプトに指の崩壊を防ぐ指示を入れるとある程度効果がありますが完璧には防げません。しかし、入れておくに越したことはありません。

⑤:サンプリングアルゴリズム
一般的にはサンプラーと呼ばれています。簡単に説明するのは難しいのですが、AIに描かせる方法の違いを指定する場所です。サンプラーを変えることで背景の描写力を上げたり、描きこみを増やしたり、画像生成速度を早めることができます。
いくつかおすすめのサンプラーをご紹介します。
DPM++ 2M Karras
おそらく一番人気のあるサンプラーです。構図が確定するまでのステップ数は他のサンプラーより遅いですが1ステップにかかる時間が半分ほどになっています。描きこみも申し分なく、20〜30ステップ程度で運用している人が多いようです。

DPM++ SDE Karras
こちらは最近人気が出てきたサンプラーです。生成速度が比較的遅めですが、その分早めのステップ数で構図が確定します。DPM++ 2M Karrasと比較してこちらのサンプラーの方が良いという人もいます。15ステップ以上で構図や塗りが安定してくるのでその辺で運用している人が多い印象です。

Eular A
デフォルトのサンプラーです。生成速度が比較的早めでシンプルな絵柄を出しやすいです。10ステップ程度でノイズが残ることはなくなります。ステップを増やしていくと少しずつ構図が変化していき、ステップを極端に増やしても一定に定まることはありません。通常、20ステップ前後が一般的だと思います。

DDIM
DDIMは人物が少し苦手な代わりに、背景描画力が向上することで知られています。生成のスピードも速めです。構図は10ステップ程度で確定しますが、きれいに出力するには20ステップ以上がよいでしょう。

⑥:サンプリング回数
一般的にステップと呼ばれています。AIが画像を吟味する回数という意味なのでステップ数が多いほど良いかと思いがちですが、絵の品質には限界がある上に生成にかかる時間が比例して増加していくため、実際には20〜30ステップ前後でも問題はありません。
⑦幅と高さ
ここで画像の幅と高さを設定します。画像が大きくなるほど生成に時間がかかるようになります。また、あまり大きすぎると人物などを描画させたときに破綻(腕や足が増えたり人体構造が乱れる)が増える恐れがあります。
⑧CFGスケール
CFGスケールとはAIがプロンプトにどの程度従うかを決めるものです。数値を低くしていくと従順度が下がり自由に描きこみを増やしていくので絵画的で抽象的な表現に向いています。また、数値を上げていくとシンプルな絵になっていき絵の明るさが向上していくので建物や室内の家具小物を比較的正確に描写していくことができます。CFGスケールの相性はモデルや絵によって異なりますのでお好みで調整してください。よくわからなければ、初期値の7でもかまいません。

⑨:高解像度補助
3つの補助設定がありますが、高解像度補助以外はあまり使われていません。高解像度補助にチェックを入れると、画像を生成した後に画像を拡大することで品質を向上させることができます。
高解像度補助を画像を生成するときから使用する人もいれば、i2i(イメージ to イメージの略)といって後から画像の品質を上げる作業をする人もいます。高解像度補助は品質を上げるのに有用なので個人的には使うことをお勧めします。例えば768×512と768×512を高解像度補助で1.5倍の大きさにした時の違いは次の通りです。


比べてみるとわかるのですが細部のぼやけた感じがなくなり輪郭がはっきりして描きこみも細部まで増えているのがわかります。
画像生成時に高解像度補助を使う方法は次の通りです。

まずは①で高解像度補助にチェックを入れます。すると各種設定が表示されます。
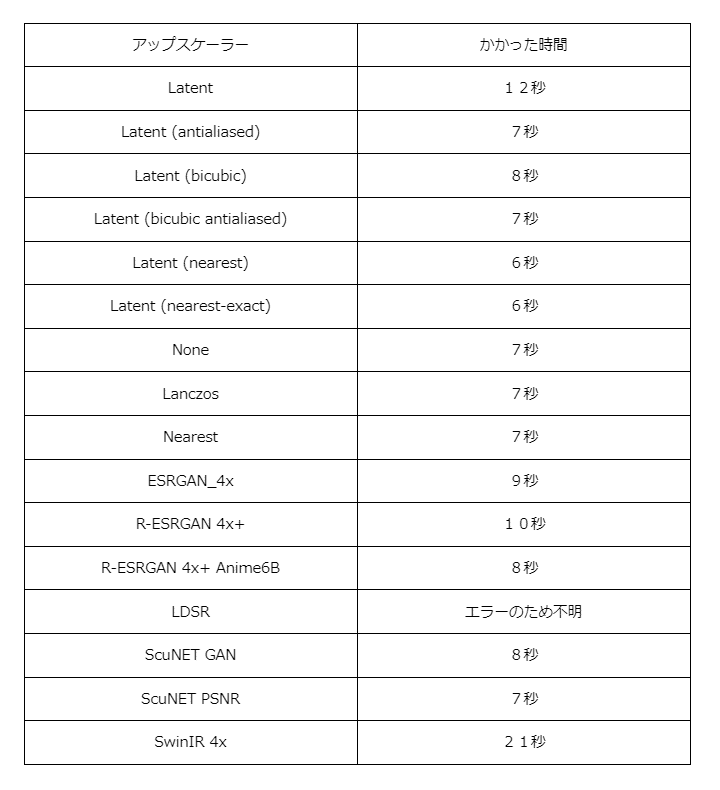
②のアップスケーラーは画面を高解像度化する手法を選ぶものです。様々な種類がありますが性能が大きく違うわけではありません。どれがいいか分からなければ下の表を参考に、生成速度が速いLatent (ニアレスト補間)、Latent (ニアレストエグザクト補間)などを使うと良いでしょう。
③では高解像度化でのステップ数を設定します。0に指定すると生成した際の元のステップ数を参照します。例えば、元が24ステップで作られた画像の場合、高解像度化を0ステップに指定すると24ステップとして扱われます。通常、生成ステップ数の3分の1程度の高解像度化ステップ数があれば、ノイズが入ることなく高解像度化できるでしょう。時間がかかっても品質を上げたい方は生成ステップ数の2分の一以上や0を指定することができます。
④のノイズ除去強度は絵にどのくらいの変化を加えるか決定します。アップスケーラーの種類にもよりますが、0.5より小さかったり、0.85より大きかったりするとノイズが混じって生成がうまくいかないことがあります。
⑤では画像を何倍の大きさにするかを決めます。画像サイズにもよりますが2倍以上の大きさにすると時間がかかる上に破綻が増えてきます。ですので、普段は2倍までにとどめるようにしましょう。
下記は私の環境でアップスケールが完了するまでの時間を表にまとめたものになります。
もとになった絵の生成時間:3秒
⑩バッチの回数
バッチの回数とは一度に何枚一気に生成するか設定するところです。複数枚生成した場合、全部の画像が一覧で生成終了時に最初に表示されます。一枚一枚確認することも出来ます。例えば同じプロンプトで9枚に設定したとするとこのように一覧で表示された後、一枚ずつ確認することができます。



⑪SEED値
SEED値とはプロンプトとネガティブプロンプト、サンプラーとステップ数、画像の大きさなどの設定が同じとき、ほぼ同じ画像を出力することができます。(厳密には一緒ではありません)
また、SEED値が同じでもプロンプト等が異なれば似た構図になることはあっても違う絵になります。これは画像の中にメタデータ(Exifとも呼ばれる)という形で記録されていて、WebUIの機能の中で確認したり外部サイトなどで見ることができます。
シード値右側のダイスマークはシード値をランダムに戻すボタンです。これにより毎回違う構図の絵を出力をすることができます。また、リサイクルマークのような形のボタンは今プレビューされている絵のシード値を取得して表示します。次から生成される絵はほぼ同じ画像になります。
⑫スクリプト
スクリプトとはプロンプトがどのように作用しているか調べたりする補助機能のことです。特にX/Y/Z plotが大変便利ですのでぜひ使っていただきたいです。

①でX/Y/Z plotを選択します。
すると、各種メニューが出てくるので今回はCFGスケールの値の変化がどのように絵に反映されるのか検証してみましょう。X軸のプルダウンメニューからCFGスケールを選択します。
③でX軸の値を「3,7,11」と入力してみましょう。数字や文字列を区切るときはプロンプトのように「,」をつけて分けます。ステップ数や画像の大きさなど、その他の設定は通常生成時のパラメータと同じになります。設定が終わったら生成ボタンを押します。使わない軸を「無し」に設定していないと予期しない表が出来上がったり、空欄のため生成できないといわれることがあるので生成に失敗する場合は他の軸も確認してください。
④の凡例を描画からチェックを外すことで一覧が生成されなくなります。一覧は別ファイルで保存されており画像サイズによっては容量を食うファイルになるので気になる方はオフにしてください。

このようにスケールごとの絵柄の変化の違いが表で確認できます。

縦軸と横軸を入れ替えたい場合は「swap X/Y axes」を選択します。この場合X軸とY軸が入れ替わります。

これで縦軸と横軸が入れ替わり縦に表が作成されるようになりました。

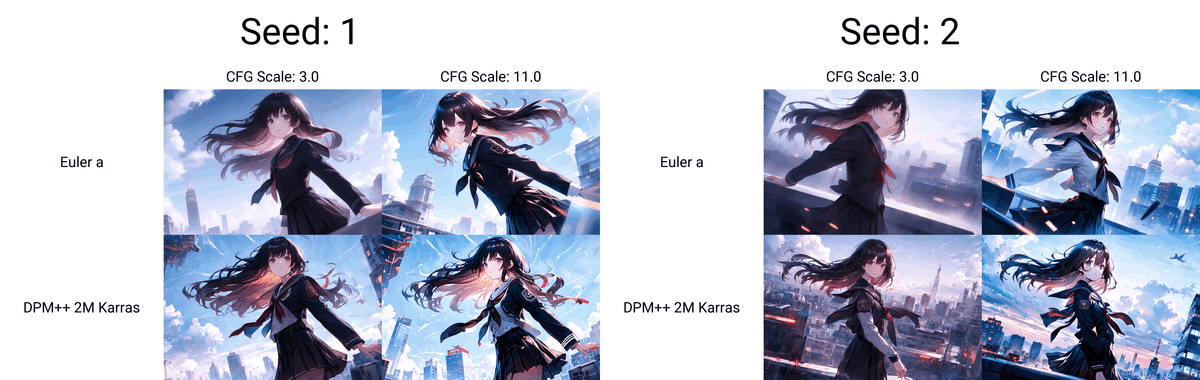
また、z軸を設定すると作成される画像の数も2倍、3倍と増えていきます。

プロンプトがどのように作用するか調べるには「prompt S/R」を選択してください。今回はY軸に設定しています。
Y軸の値には比較したいプロンプトを入れていきます。最初に入れるプロンプトはプロンプト内に存在していないとエラーになるので注意してください。
((masterpiece, best quality)),best aesthetic,1girl, from below, solo, school uniform, serafuku, sky, cloud, black hair, looking at viewer, building, neckerchief, long sleeves, cloudy sky, shirt, pleated skirt, city, black sailor collar, closed mouth, black skirt, medium hair, buildings
先ほどのプロンプトの太字の部分「black hair」の部分を変えてみましょう。Y軸の値に「black hair,blue hair,blonde hair」と入力してみましょう。



同じプロンプトのまま、髪の色を連続で変えることができました。次は複数のプロンプトを一緒に変えてみましょう。
((masterpiece, best quality)),best aesthetic,1girl, from below, solo, school uniform, serafuku, sky, cloud, black hair, looking at viewer, building, neckerchief, long sleeves, cloudy sky, shirt, pleated skirt, city, black sailor collar, closed mouth, black skirt, medium hair, buildings
Y軸プロンプトを"sky, cloud, black hair","night sky,pink hair”に変更してみましょう。2つ以上のプロンプトを一緒に変えるときは、プロンプトが隣接していることと、変更する箇所のプロンプトを「” ”」で囲んでください。実際にはこのようになります。


実際に生成した結果がこのようになります。
⑬設定の保存と呼び出し
生成ボタンの下には設定を呼び出すいくつかのボタンがあります。ひとつづつ解説していきます。
↙ボタンは主に最初に起動したとき前回終了時の設定を呼び出すのに使います。初期設定のままだと復元するのにやや手間なので重宝すると思います。
ゴミ箱のボタンは現在入力されているプロンプトとネガティブプロンプトを削除するボタンです。設定は初期値にリセットされません。
花札マークのボタンは、「LoRA」という拡張機能をプロンプトに追加します。これは絵柄や構図をモデルの得手不得手を超えて補正してくれる便利なのものです。難しい服装や背景などもこのLoRAがあればかなり簡単に出すことができます。

先に一番右の保存ボタンについて解説します。このボタンは現在表示されているプロンプトとネガティブプロンプトを名前を付けて保存しておくことができます。保存したプロンプトはスタイルから呼び出すことができます。
スタイルで呼び出したいタイトルのプロンプトを指定し右から二番目のボードのボタンを押すと内容が反映されます。
あとがき
長丁場でしたが、ここまで読んでいただきありがとうございました。
現在はtxt2imgの項目しかありませんが、いずれは「img2img」タブや「extra」タブその他便利な機能やお役立ち情報、NAIリーク派生でないモデルで作るLoRAの作り方などを解説していきたいと思っています。
この記事が気に入ったらサポートをしてみませんか?