Red Hat OpenShift で生成AI活用(RAG)の開発サイクル向上

生成系AIの出現によりAIで出来ることがとてつもなく広がりました。
生成系AIではLLM(大規模言語モデル)を利用し、テキスト分類や情報整理、文章要約、テキスト生成、質問応答など便利に使えますが、ハルシネーション(正確ではない回答)や欲しい回答が貰えないなど課題も存在します。
そういった課題を解決するアプローチ方法としてRAG(Retrieval Augmented Generation)やFine-tuningの2つの解決策が一般的かと思われます。

RAGでは公開されているLLM(OpneAIなど)を利用し自社データをベクトルストアなどに配置します。
問い合わせに対して自社データ内をベクトル検索し自社データとLLMの回答を組み合わせて回答を出すことで自分たちが欲しい情報を引っ張り出すという手法です。

Fine-tuningは、LLMをさらに自社データなど任意のデータを追加学習させることでより自分達が欲しい回答に近づけるという手法です。
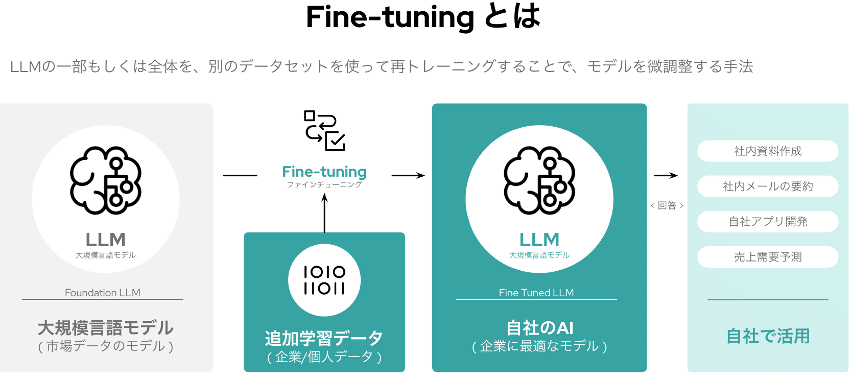
補足となりますが、Red HatではRAGとFine-tuningに加えてLAB ( Large-scale Alignment for chatBots )という手法を提唱しています。

既存LLMに対して新たにデータを加えて階層的に学習して自社向けにチューニングするという手法となります。

Red HatとIBMの両社ではIBM Researchにて研究開発されたGranite(LLM)をオープン化しLAB実装を推し進めAIの民主化をさらに加速させようとしています。

前提の説明はこの辺で終えて本題に入ろうと思います。
Fine-tuningおよびLABについては導入が大掛かりになりコストが大きくなる傾向があります。
自社のメインビジネスに活用する場合は良さそうですがどうしてもコストが見合わないという判断からRAGを導入している会社さんも多いのではないかと思います。
OpenAIなどのLLMと組み合わせて実装しようとすると、目的に応じてWEBシステムを準備してベクトルストアやLLMとAPIなどで接続するという実装方法になるのではないかと思います。
ただ、実装されている方はLLMのライフサイクルが短いという課題に悩まれているのではないかと思います。
LLMのライフサイクルに合わせて開発サイクルを早く回す必要があるのですが体制や開発スタイルが追いつかないということが起こっている組織もあるのではないかと思います。
そこで、OpenShiftを活用して開発サイクルを上げることをお勧めしたいと思います。
コンテナ化するだけでは開発サイクルは上がりませんがOpenShiftにはCI/CDも含まれていて開発サイクル向上のためのツール群が具備されています。


パッケージとして用意されているものを利用するという方法でモダナイズされた開発手法を取り入れていただければと思います。
Red Hatではモダナイズするための伴走も提供していますので自分達だけでは不安という場合にはお声かけいただければと思います。
*…*…*…*…*…*…*…*…*…*…*…*…*…*…*…*…*…*
レッドハット株式会社
谷 喜博
ytani@redhat.com
*…*…*…*…*…*…*…*…*…*…*…*…*…*…*…*…*…*
この記事が気に入ったらサポートをしてみませんか?