AITuberでも使える!リップシンクから学ぶ音声信号処理とアバター研究

はじめに
こんにちは。REALITY株式会社GREE VR Studio Laboratory(ラボ)Directorの白井です。ラボでは近年「AI Fusion」というアバター表現力を向上させるAIアシスト技術の開発に取り組んでいます。今回の記事ではラボのインターン・中野さんが取り組んでいた、アバターの表情と音声信号処理について研究内容を紹介します。
唇の動きを音声と同期させる「リップシンク(lipsync)」とメタバースに求められそうな「音声からの表情生成技術の現在」をお伝えします。Unityでの実装についても紹介します。みなさんの研究のスタート地点になれば幸いです。
そもそもVRで顔は使えない!
VR体験でよく使われるHMDですが、実は装着時はREALITYで使うようなコンピュータビジョンを使った顔トラッキングは使えません。Metaが開発したOVR Lipsyncという音声信号処理と機械学習を用いる方法のほかには近接センサーや電極など特殊なセンサーを使った方法も提案されています。
最新の研究事例
NVIDIA Omniverse Audio2Face
NVIDIAのOmniverse Audio2Faceは音声から口だけでなく顔全体をアニメーションさせるツールです。ポール・エクマン先生のFacial Action Coding System(顔面動作符号化システム)に基づくと思われるBlendShapeの特徴点を46項目取得しています。
この原稿を執筆した2022年12月現在では日本語の音声には対応していませんが、今後に期待です。
また、Audio2Faceはフォトリアルなモデルでは有効に動きますがREALITYのアバターのようないわゆるアニメ調のモデルではファイル形式や使用する特徴点などの理由から表現が大きく制限されてしまいます。
SIGGRAPH Asia2022での発表
VOCAL: Vowel and Consonant Layering for Expressive Animator-Centric Singing Animation
「VOCAL」はトロント大学による歌唱によるアニメーション生成に特化した研究です。話すことは歌うことのサブセットと見なし、歌の音声入力から表現力豊かな顔の下側のアニメーションを自動的に生成するシステム研究です。Melodic-accentとPitch-sensitivityという2つのパラメータを定義し、複数の歌唱ジャンルに対応したリップシンクを実現しています。
国内の研究でも素晴らしい事例があります。
CEDEC 2022 機械学習によるリップシンクアニメーション自動生成技術とFINAL FANTASY Ⅶ REMAKE のアセットを訓練データとした実装事例
セリフ音声と書き下し文からキャラクターに対してリップシンクを行う手法は広く使われていますが、この手法が優れているのは機械学習を用いることにより攻撃時の声などのアドリブ(書き下し文を得られない部分)に対応しているところです。
GREE VR Studio Laboratoryのリップシンク研究内容
「AI Fusion」:AIと人間動作の融合表現
AIによる正確な動作と人間味のあるトラッキングの融合技術については、ラボでもUXDevシリーズを通して「AI Fusion」という名前で研究しています。
AI Fusionプレスリリース
正解譜面のデータを使えばキャラクターに正しい演奏アニメーションを与えることができます。しかし、譜面に忠実なだけではロボットのような退屈なアニメーションになってしまいます。AI Fusionでは、正解譜面から生成する正確な運指のアニメーションとモーションキャプチャーにより得られる人間味のある動きを融合することにより、魅力的な演奏アニメーションを生成します。
AI Fusionにより生成したアニメーションはこちらからご覧いただけます。
uLipsyncを用いたUnityでの実装例(GREE Tech Conference2021)
uLipsyncは日本人の開発者・凹みさん(hecomi)がオープンソースで開発しているUnity上で動作するリップシンクのプラグインです。入力音から得られるMFCCからBlendShapeをトリガーし、リアルタイムにリップシンクを行うことができます。Job systemとBurstを用いることにより非常に高速に動作します。
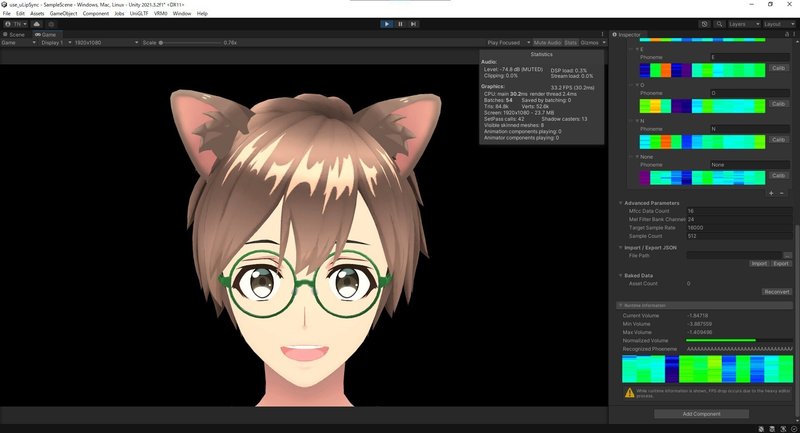
uLipSync使用環境
使用PC:Alienware M15 R3
Unityバージョン:2021.3.2f1
シェーダー:MToon
GREE Tech Conference 2021では音声スペクトラムをトリガーとしたエモート発動システムのデモを行いました。
口はuLipsyncで動かしつつ、事前に与えられたスペクトラムとリアルタイムのスペクトラムを比較してエモートをトリガーさせています。また、アニメーションのブレンドをスペクトラム全体の値の大小をパラメーターにして行うことでエモートの強弱も変化させています。
※デモ作成時はuLipSyncのv2を使用しましたが、2023年4月28日にv3へのアップデートがありました。MFCC計算方法に問題があり修正されたそうです(https://github.com/hecomi/uLipSync/releases/tag/v3.0.0 )
アニメ調のアバターで表情を生成するには(GREE Tech Conference2022)
ラボではUXDevプロジェクトを通してREALITYのようなアニメ調のアバターに対して表情アニメーションを生成するパイプラインを試作し、2022年10月に公開したショートフィルム「MetaCommunication」に使用しました。
Proof of Concept(PoC)としての実装では、SpeachToText(STT)とJuliusを使用し、音声とセリフの書き下し文から各音素の開始・終了のタイミングを取得することでUnity上で該当時刻にアニメーションのキーフレームを打つことにより表情のアニメーションを生成することが可能になりました。
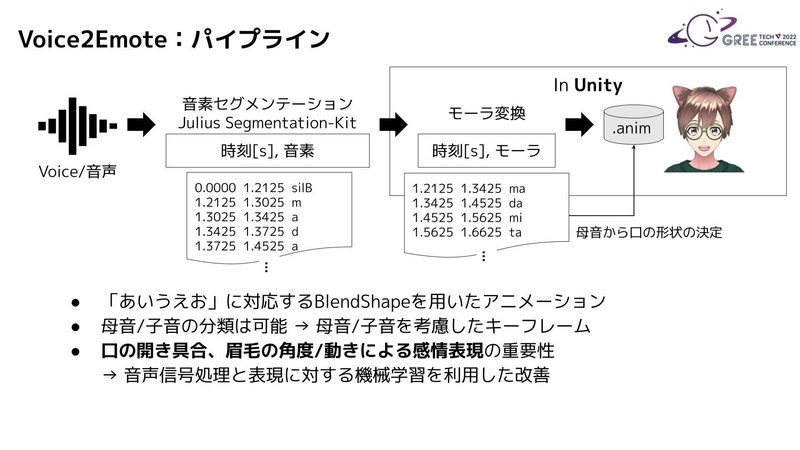
この動画では、子音(s, k, p, t, z, g, b, d など)のBlendShapeは用意せず、「あいうえお」に対応するBlendShapeのみをアニメーションさせているので、子音を考慮した口の動きにはなっていませんが、クラシックな手法で良好な結果が得られたと思います。
TTSとJuliusを使うとリアルタイム化は難しいと思いますが、昨年のGREE Tech Conference2021ではuLipSyncを使ったリアルタイムなエモート生成を発表しています。
日本では最近、AIVTuber/AITuberの存在が話題になっていますが、実はVRの研究や世界のCG研究、そしてオープンソースの世界で、さまざまな技術がつながり続けていますね。学ぶことが多くなって大変ですが!
まとめ
研究開発としてリップシンクを応用した次世代メタバースやAITuberに求められそうな音声からの表情生成技術の研究開発の一端をお伝えしました。
REALITY株式会社 GREE VR Studio Laboratoryでは以上のように、最先端のUX研究をしています。ご興味がある方はYouTube(https://j.mp/VRSYT)をご購読いただけると嬉しいです。
また、ラボが主催する研究チャレンジプログラム「VTechChallenge2023」のオンライン発表会審査が5月24日に「VRSionUp!13」にて予定されています。噂によるとAITuberに関する研究が多数発表されるようです。
https://youtube.com/live/9achiaxHc-4
インターンに興味を持ってくれた方はぜひこちら[インターン希望の方へ]から詳細をご確認ください!