
Stable Diffusion (AUTOMATIC1111) をAPIで操作する ~WEB UI不要で任意のサービスと連携~

こんにちは、Rcatです。
前回の記事でStable Diffusion(以下SD)のAPIを用いたDiscordのBOTを作成しました。
こちらのbotを用いることで、Discordから指示を出して24時間の生成が可能になりました。また、チャットの機能を使用したスケールアップや編集なども行えるようにしました。
これらの機能は全てAPIによって実現されています。
今回は情報が少ないSDのAPIについて解説していきます。
前回の記事はこちら。APIを使用して画像生成を行うチャットボットです。配布もこちらで行っています。
この記事は下記の記事でSDを導入済みの前提です。
そもそもAPIって何
まずAPIとは何かというと、外部のプログラムからSDを操作するために使用するインターフェースの事です。
SDのAPIはWEBサーバーのURLをたたくことで呼び出せます。
SDのAPIについて
SDのAPIを用いると何ができるようになるのか、それはWebUIを使わずに画像の生成ができるようになります。
つまり、任意のプログラムと連携することが可能になるわけですね。
最初にAPIのドキュメントがどこにあるか説明しておきます。
通常WebUIを使っている状態で、さらに/docs中に実はAPIのドキュメントがあります。URLで言えば下記のようになるでしょうか。
http://localhost:7860/docs
こちらのページを開くと使用できるすべてのAPIのURLや使い方が記載されています。ただちょっと痒いのが、引数までは書いてあるんですが、その引数が何を意味するのかまで書いてないところでしょうか?

例えば以下が画像を生成するためのAPIなのですが、各項目がずらっと並んでいて、引数にはデフォルトの値まで入っていますがそれが何を意味するかまでは書いていません。WebUIを使っていればなんとなく分かる部分でもあるんですが、名前が違うやつはちょっと分からないですね。
この辺りは情報も少なかったので、自分で試行錯誤しつつ確かめた部分もあります。今回はそういった部分を解説できればと思ってます。

とりあえずAPIで画像を生成してみる
テストコード
いきなり使い方の説明や、私の作った最終形を出しても分かりづらいと思うので、まず最初にとりあえず画像の生成をしてみます。
基本的にURLを叩ければいいのでどんな言語でも構いませんが、今回はPythonを用います。
なお、SDは同じパソコンで既に立ち上がっている前提です。
import requests,base64,io
def Main():
Imgsetting = {
"prompt": "(masterpiece:1.1),(best quality:1.0),(super fine cel anime:1.2),cute girl,blouse,no background,flat background",
"negative_prompt":"(worst quality, low quality:1.2),ugly,error,lowres,blurry,multipul angle, split view, grid view,text,signature,watermark,bad anatomy",
"steps": 20,
"sampler_index":"DPM++ 2M Karras",
"width": 256,
"height": 384,
"cfg_scale": 7,
"seed": -1,
}
resp = requests.post(url=f'http://localhost:7860/sdapi/v1/txt2img', json=Imgsetting)
json = resp.json()
imgdata = json["images"][0]
with open("test1.png","wb") as f:
buf = base64.b64decode(imgdata)
f.write(buf)
return
if __name__ == '__main__':
Main()こちらを実行すると、今回は下記のような画像が生成されました。

テストコードの解説
まずは一番最初の設定の部分から解説します
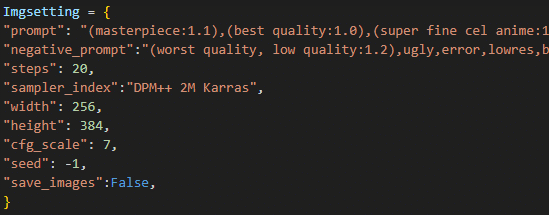
こちらはWebUIで言えば下記の画面の設定内容をAPIに載せて叩くための設定となります。

全ての設定は数が多く、とてもじゃないですが制御していられないので主要な部分だけ設定していきます。
prompt
知っての通り、プロンプトを入力します。入力内容はWebUIの時と同じです。negative_prompt
こちらも同じくネガティブプロンプトを入力します。steps
UIだとスライダーになっているサンプリングステップのことです。
使用するサンプラに応じて最適な数値を設定してください。sampler_index
どのサンプラーを使用するか名前で指定します。
"DPM++ 2M Karras"や"DDIM"など。面倒なのが一時一句間違えずに入れなきゃいけないところでしょうか?
ただし、サンプラーの名前を取得するためのAPIもあるので、そこからコテすることで何を入力すればいいかはわかると思います。width/height
画像のサイズを指定します。cfg_scale
cfgスケールを設定します。あまり変えないと思うのでデフォルトでもいいと思いますが、一応入れてあります。seed
-1でランダム。特定のシードで詰めていく場合はシード値を入力
以下ドキュメント抜粋。横に書かれている数値や文字列がデフォルトの値のようです。
少なくとも"string"になっているところは設定しないとまずい気がします。
ステップも50とかちょっと多いですね。
{
"enable_hr": false,
"denoising_strength": 0,
"firstphase_width": 0,
"firstphase_height": 0,
"hr_scale": 2,
"hr_upscaler": "string",
"hr_second_pass_steps": 0,
"hr_resize_x": 0,
"hr_resize_y": 0,
"prompt": "",
"styles": [
"string"
],
"seed": -1,
"subseed": -1,
"subseed_strength": 0,
"seed_resize_from_h": -1,
"seed_resize_from_w": -1,
"sampler_name": "string",
"batch_size": 1,
"n_iter": 1,
"steps": 50,
"cfg_scale": 7,
"width": 512,
"height": 512,
"restore_faces": false,
"tiling": false,
"negative_prompt": "string",
"eta": 0,
"s_churn": 0,
"s_tmax": 0,
"s_tmin": 0,
"s_noise": 1,
"override_settings": {},
"override_settings_restore_afterwards": true,
"script_args": [],
"sampler_index": "Euler",
"script_name": "string"
}次に設定を用意したら、APIを叩いて画像を取得します。
以下がその部分の処理になります。

今回はプロンプトから画像を生成するので叩くAPIは"/sdapi/v1/txt2img"になります。
ドキュメントでもを書いてある通り、こちらのAPIはjosnで設定をくっつけた状態でpostすることで叩くことができます。
応答はドキュメントより、下記のような形式のようです。
{
"images": [
"string"
],
"parameters": {},
"info": "string"
}イメージの部分がstringになっていますが、基本的にウェブで画像を送信する場合は、base64という文字列にエンコードしてから送受信するのでそのことです。
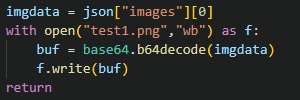
最後にこの部分で画像を保存しています。入手したjsonの中の"images"が画像のデータなのでそれを取得後、base64をデコードしてバイナリにしてからそれを保存しています。base64の辺りがわからない場合はちょっと調べてみてください。
これでAPIによる画像の生成の基本は完了です。
特に特別なライブラリは必要ないので、SDが同じパソコンで立ち上がっている状態であればコピペで動作するはずです。
別のパソコンで動かしている場合は、接続先をローカルホストではなく対象のIPアドレスにしてください。
時間がかかる場合タイムアウトするので、タイムアウトを長めにしてください。
画像のアップスケールを行う
この辺の情報が全く出てこなくて困ったので自力で検証しました。
今回行うアップスケールはWebUIで言うと以下の部分になります。
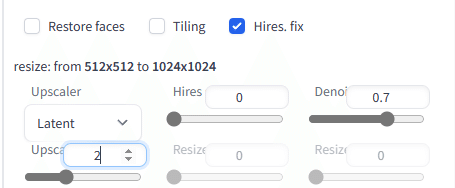
パラメーターの設定
この設定を行うためにパラメーターを追加で指定します。
最初に生成した画像を拡大したいため、シード値を最初の画像から持ってきています
Imgsetting = {
"prompt": "(masterpiece:1.1),(best quality:1.0),(super fine cel anime:1.2),cute girl,blouse,no background,flat background",
"negative_prompt":"(worst quality, low quality:1.2),ugly,error,lowres,blurry,multipul angle, split view, grid view,text,signature,watermark,bad anatomy",
"steps": 20,
"sampler_index":"DPM++ 2M Karras",
"width": 256,
"height": 384,
"cfg_scale": 7,
"seed": 412220144,
"save_images":False,
"enable_hr":True,
"hr_scale": 2,
"hr_upscaler": "R-ESRGAN 4x+ Anime6B",
"denoising_strength":0.5
}ポイントとしては"enable_hr"というパラメーターがTrueになっているところです。このパラメータを追加した上でTrueにしておくとアップスケーラーが起動するようになります。その他のパラメーターは次の通りです。
hr_scale
画像拡大の倍率を指定します
システムのスペックに応じて最適な値を選んでください。hr_upscaler
アップスケーラーの名前を指定します。
こちらもサンプラのときと同じく、名前を1字1句間違えずに入力する必要があります。denoising_strength
ノイズ除去強度です。
使ってみてわかったことですが、webuiのノイズ除去強度とはちょっと違うのかもしれません。
WebUIの場合、これが足りないとぼやけた画像になるのですが、APIから実行するとのっぺり引き伸ばした感が出るようになります。
まぁ、こだわっても仕方がないので追及はしない物としています。
実行結果
実行結果は下記の通りです。最初に生成した画像を拡大することができました。


様々なAPI
進捗状況を取得する
WebUIを使っているとプログレスバーで進捗と画像が表示されますよね?それもAPIに備わっています。
ドキュメントを確認すると、プログレスのAPIは以下のようになっています。パラメーターとしてスキップがあるようですが、こちらの動作は確認できていません

実行結果がこちら
上から順番にパーセンテージ。残り時間、その他ステータスです。
一番下にあるカレントイメージはWebUIでも出てくる生成途中の画像のことだと思います。デコードまではしてないので分かりませんが。
私の作成したbotはこちらを取得してステータスメッセージに表示します。

サンプラーを取得する
サンプラーの設定は一字一句間違えてはいけません。
となると選択肢があると助かるんですが、それを提供するのがこちらです。

実行結果がこちら
サンプラによっては複雑なパラメーターも持っているようなので、若干構造が複雑ですが、上から順番にリストを開いて行ってnameを取得すれば良さそうです。
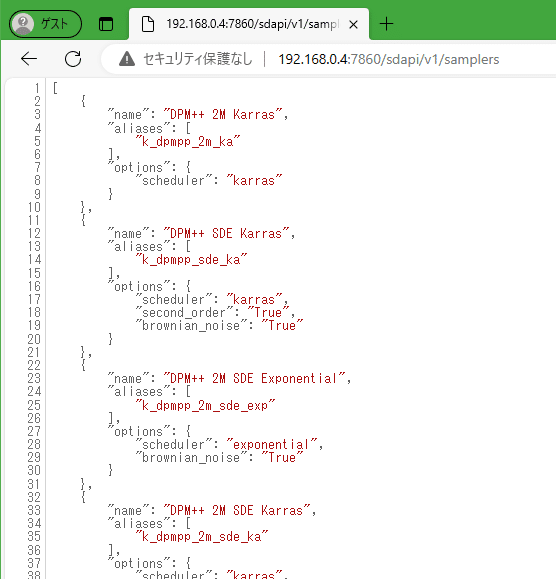
アップスケーラーを取得する
こちらもサンプラと同様です。

構造をほぼ同じなので、サンプラーと同様のプログラムで抽出が可能かと思われます。
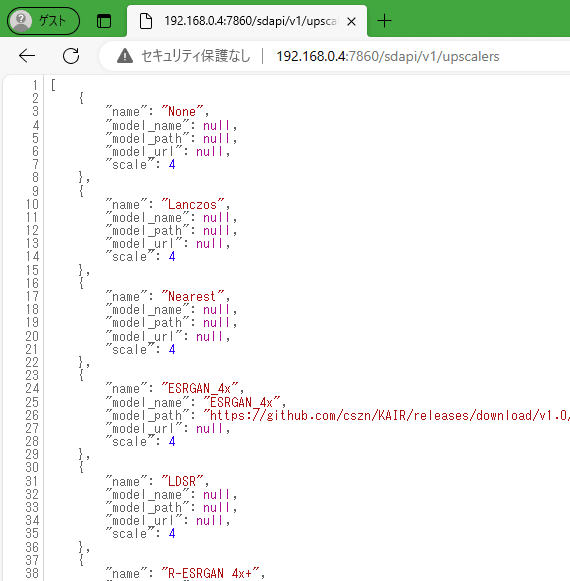
保存されているモデルを取得する
フォルダ内に格納してあるモデルの一覧を取得することができます。

実行結果がこちら
何持ってるかバレバレですね。うまく動かないのもあるんですけど

モデルを設定する
モデルの設定が一番意味のわからんところにあります。
設定はオプションになっており、バラメーター"sd_model_checkpoint"で設定されます。

ちなみにここで指定すべき名前はモデルで取得した時に出てくる"title"の部分になります。間違っても"model_name"ではありません。
モデルをチェンジしてから画像を生成するようにソースを改変しました。
import requests,base64,io
def Main():
ChangeModel()
Imgsetting = {
"prompt": "(masterpiece:1.1),(best quality:1.0),(super fine cel anime:1.2),cute girl,blouse,no background,flat background",
"negative_prompt":"(worst quality, low quality:1.2),ugly,error,lowres,blurry,multipul angle, split view, grid view,text,signature,watermark,bad anatomy",
"steps": 20,
"sampler_index":"DPM++ 2M Karras",
"width": 256,
"height": 384,
"cfg_scale": 7,
"seed": 412220144,
"save_images":False,
"enable_hr":False,
"hr_scale": 2,
"hr_upscaler": "R-ESRGAN 4x+ Anime6B",
"denoising_strength":0.5
}
resp = requests.post(url=f'http://localhost:7860/sdapi/v1/txt2img', json=Imgsetting)
json = resp.json()
imgdata = json["images"][0]
with open("test1.png","wb") as f:
buf = base64.b64decode(imgdata)
f.write(buf)
return
def ChangeModel():
option_payload = {
"sd_model_checkpoint": "HimawariMix-v8.safetensors",
}
resp = requests.post(url=f'http://localhost:7860/sdapi/v1/options', json=option_payload)
実行結果がこちら
左側が最初に生成した画像で右側がモデルを変更して書いた画像です
モデルの変更がきちんと適用されていることがわかります。

まとめ
今回はSDのAPIを使用して画像を生成していきました。
便利なWebUIがあるので、あまりAPIを使用するという人はいないのかもしれませんが、自作のサービスを連携させたいと思ったら非常に便利なものですので、是非試してみてください。
なお、APIを使用して私が作成したDiscordのbotは下記の記事から配布中ですので、ぜひぜひ使用してみてください。
例えば今回お話ししていませんが、APIを叩くためのクラスを作っていたり非同期のリクエストを使ってAPIを叩いていたりします。
記事が出てしばらくの間はRcatもはまっていると思うので、アップデートが期待できます。
それではまたお会いしましょう
情報が役に立ったと思えば、僅かでも投げ銭していただけるとありがたいです。