
【競馬】種牡馬を機械的にグループ分けする方法 ~K-means法クラスタりんぐ~
種牡馬のグループ分け
種牡馬を競馬予想のファクターとして重要視している方も多いでしょう。
私自身、血統を軸に競馬を見ているので、やはり予想の際には種牡馬をまず見ます。
当然、まずは1頭ずつの種牡馬の理解が重要にはなりますが、今年の2才世代だけを見ても、種牡馬は321頭ものバラエティがあり個別の理解では追い付かないのも事実。
そこでTargetを普段利用されている方には馴染みがあると思いますが、種牡馬をグループ分けする作戦です。
一般的には、サンデー系、ミスプロ系、ノーザンダンサー系などと系統別に分けます。有名な亀谷敬正氏は国別の分類やサンデー系の中でも適性ごとに細分化するなどして工夫されています。
しかし系統も細分化しており、血統系統ごとにキレイに適性が分かれてくれません。
ならばストレートに種牡馬成績を基準にグループ分けしてやるのが実用的ではないでしょうか。
機械的にグループ分けしよう
馴染みのない方には難しいテクニックですが、機械学習の手法としてK-means法なるものがあります。(こちらが理解不能でもTargetに取り込めるデータを添付しているのでご安心ください。)
簡単にいえば、類似のデータを「クラスタ」というグループに分割してくれるのです。
これを種牡馬のケースに当てはめれば、成績の特徴ごとに種牡馬をグループ分けしてくれるわけです。これを手動でやるのは面倒くさいですし、基準が主観的になります。
今回は視覚的に解釈しやすいように、シンプルに2つのファクターで種牡馬を分類しようと思います。
まずはTargetから以下のようにデータを取得
(データ範囲:2015/06/01~2020/05/31)

1着がゼロの種牡馬を削除すると456の種牡馬に絞られますが、あまりにサンプル数が少ない種牡馬を入れるとうまく分類が機能しないので、当該期間に50勝以上している種牡馬に絞りましょう。

すると74頭と少なくはなりますが、まぁ大半はこの辺の産駒なので実用上問題はないでしょう。
グループ分けの2つのファクターを、「平均勝利距離」と「芝勝利シェア率」を使います。
これにより、種牡馬を 距離適性・芝ダート適性 でグループ分けできます。
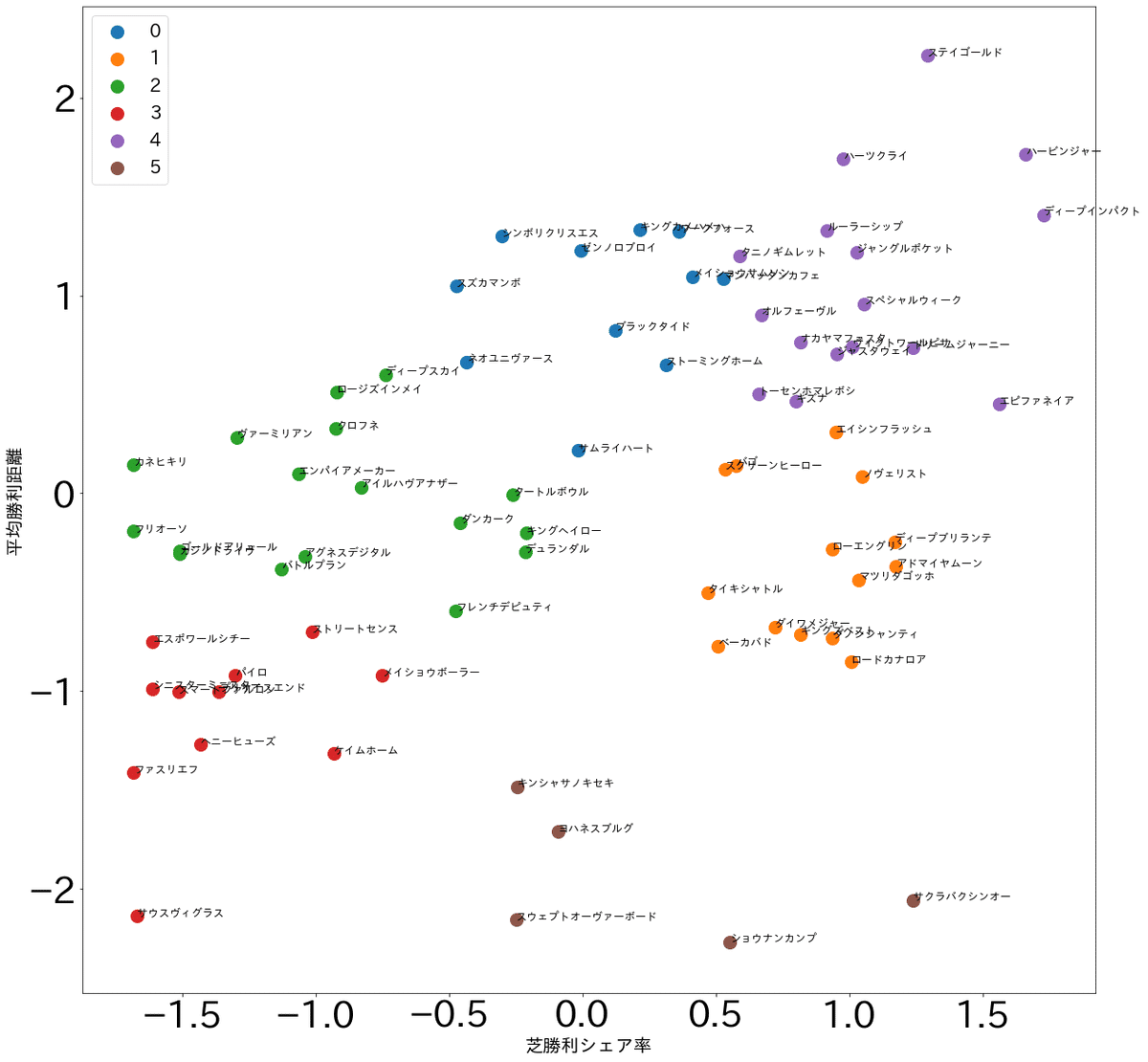
このように視覚的に解釈しやすい形で、色と番号別に種牡馬を分類できます。
ポイント
・自分でグループの数を設定する点です。おそらくこのデータの場合は6つが妥当だと思います。(真ん中あたりの緑が別グループ=芝ダート距離万能としてカウントされていいかも)
・データの値を標準化する点。芝勝利シェア率に対して、平均勝利距離の値が大きいため、そのまま使うとうまく分類できません。なのでStandardScalerで平均0、分散1のデータに変化します。
この場合、平均勝利距離の平均が1628m / 芝勝利シェア率の平均が0.448です。
それでは色別に特徴を整理してみましょう。
紫:芝中長距離特化(いわゆる日本競馬の主役たち)
オレンジ:芝のマイル前後型
青:芝ダート兼用の中長距離型
緑:ダート中距離型
赤:ダート短距離型
茶:芝or芝ダート兼用短距離型

これだけでも楽しいワケなんですが、Targetに取り込むなどして活用したいですよね。
Targetへの取り込み方法
Targetの「馬名ファイルリスト」から取り込めます。以下のCSVファイルに74頭の種牡馬名と分類番号のセットがあります。
こちらから同じ番号の種牡馬を選択し「Ctrl+C」でクリップボードにコピーします。「血統検索」▶︎「ファイル」▶︎「馬名リスト(クリップボード)から読み込む」をクリック

すると以下のように該当の種牡馬が読み込まれます。

そして「編集」▶︎「全種牡馬を同一タイプのチェック種牡馬に一括登録する」でご自身で新たなラベルがつけられます。

あとはグループごとに同様の手順を繰り返せば分類完了です。
種牡馬分類のポテンシャル
そもそもこの記事のネタ自体、ドンピシャにささる読者というのは非常に少ないだろうと思われます。
種牡馬×Python×競馬Target の合わせ技なので、現実味がない方も多いかもしれません。
例えば、亀谷氏のサンデー系の分類なども具体的な分類基準って示されてないですよね?そこら辺の主観を廃して、数学的に分類していこうという趣旨でした。
今回利用したK-means法の本来の強みは、人力では見つけられないようなクラス分類を発見できる点にあります。
・未知なる種牡馬の分類パターン
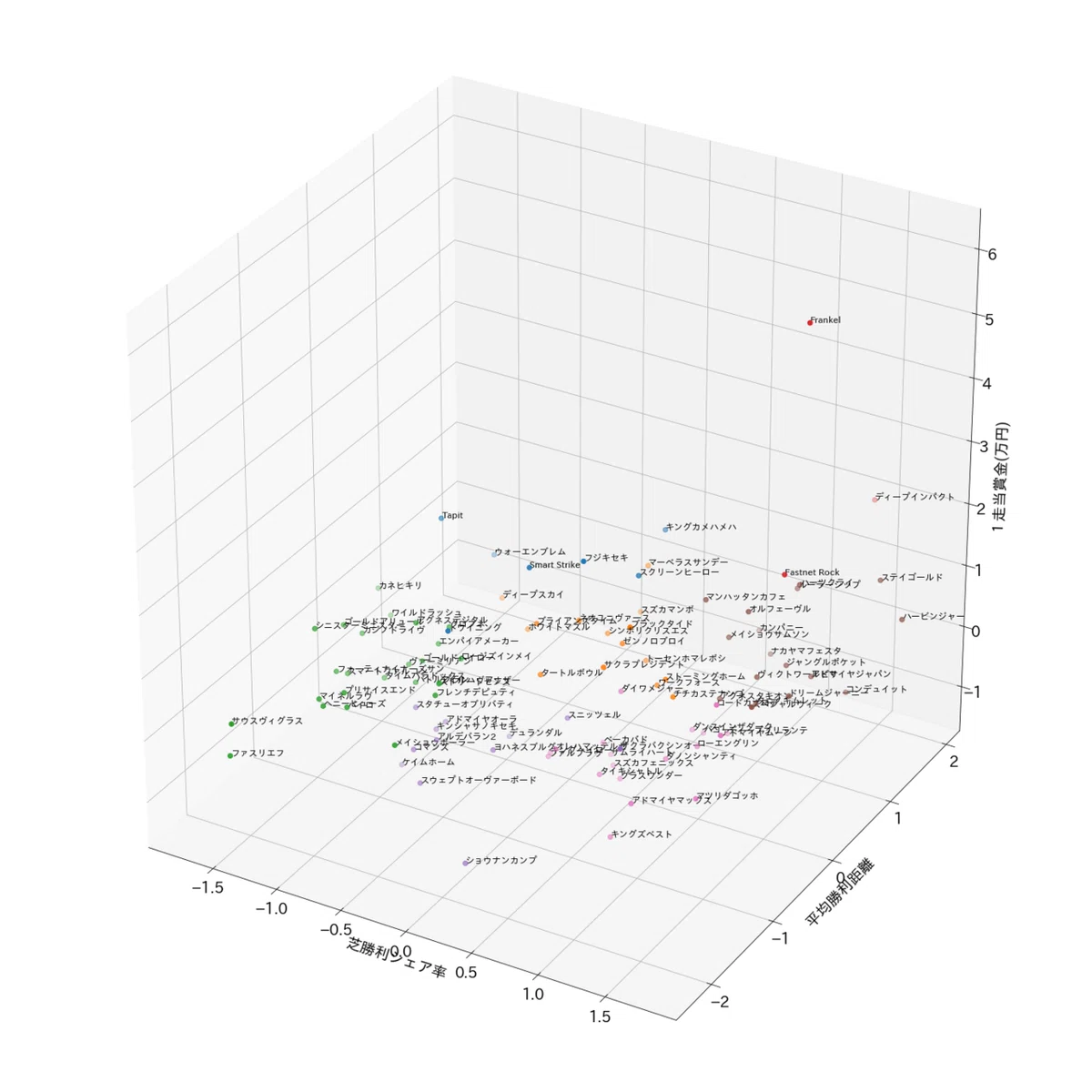
ですから、より発展的に活用するならば、今回のように2つのファクターの利用に限定するのではなく、他にも「芝での平均勝利距離」、「1走当り平均賞金」、「性別別賞金」などなど、より複雑な情報を加えればオリジナルな種牡馬分類パターンがGETできます。
例えば、「1走当り平均賞金」を加えれば、横の適性だけでなく、種牡馬のレベルの高さも表現できます。
・競馬予想での活用
予想においては、例えば極端に重い馬場や極端に速いor遅いペースにおいて異なるレンジの種牡馬が台頭しやすいパターンの発見などが期待できます。
芝中長距離なのに、重馬場では芝ダ兼用の中長距離型が来やすい、といった種牡馬グループのズレを発見する具合です。
また機械学習で競馬予想やPOG予想の際にクラスタ番号を1つの特徴量として加えるのも有効かもしれません。
関連記事:【競馬】機械学習の素人がPOG攻略法を求めて悪戦苦闘した1ヶ月の記録
この記事が気に入ったらサポートをしてみませんか?