
ChatGPT+Replicate+VOICEVOXでAI画像とシナリオを生成して読み上げてもらう

こんにちは、ライです。
3/2にChatGPTのAPIが公開されてから、様々なアプリケーションが作られている様子をTwitterで見かけるようになってきました。
私はStable Diffusionで遊び始めたことをきっかけにPythonに初めて触れた程度でプログラミング経験はほぼないのですが、ChatGPTの助けを借りながらなら自分でも何か作れるのでは?と思い始めました。
これまで画像生成AIで遊んでいたこともあり、ChatGPTと画像生成AIを掛け合わせて、何か面白いものをを作れないかなぁと考えました。
で、作ったアプリはこのようなものです。
テーマを入力すると、AIイラストとシナリオを生成して読み上げてくれるアプリを自分用に作りました。
— ライ / rais corr. (@RaisCorr) April 10, 2023
好きな世界観に浸れる感じがすごくいい!#AIart #AIイラスト #ChatGPT pic.twitter.com/yGgdvaMYi4
全体像としては、こんな感じの仕組み。
===
テーマが入力されると、画像生成AI用のプロンプトを作成する
Replicateで画像生成が実行される
プロンプトからは、それに関連したシナリオ(物語のあらすじ的な)も生成する
生成されたシナリオはVOICEVOXで読み上げる
===
下記リポジトリでソースコードをすべて公開しています。
とにかく使えればいいんだ!という方は、リポジトリにあるREADMEの通りに進めていけば動作すると思います。
興味のある方はぜひ遊んでみてください。
以下、この記事では使っているパッケージやサービスを解説していきます。これから遊んでみたい方の参考になれば幸いです。
なお、この記事は全文を無料公開しています。
ですが、もし役に立った・参考になったと思い投げ銭してもいいよ、という方がいましたら、ご支援していただけたらとても嬉しいです!
環境構築
まず環境構築について。
私の実行環境は以下の通りです。
同様の環境を用意すれば動作すると思います。
Windows 10
Python 3.9.9
パッケージのインストール
poetryを使って、パッケージをインストールします。
# パッケージのインストール
poetry installpipを使用する場合は、以下のようにしてパッケージをインストールしてください。
# パッケージのインストール
pip install -r requirements.txt環境変数の準備
まず、ChatGPTのAPIを使う準備として、OpenAIのAPIキー(有料)を取得します。
OpenAIのAPIキーの取得~登録について、下記ページに分かりやすくまとまっていました。
APIキーを取得したあと、APIキーをWindowsの環境変数に追加する際、タスクバーの検索ボックスで”kan”と入力すると「環境変数の編集」が出てくると思います。
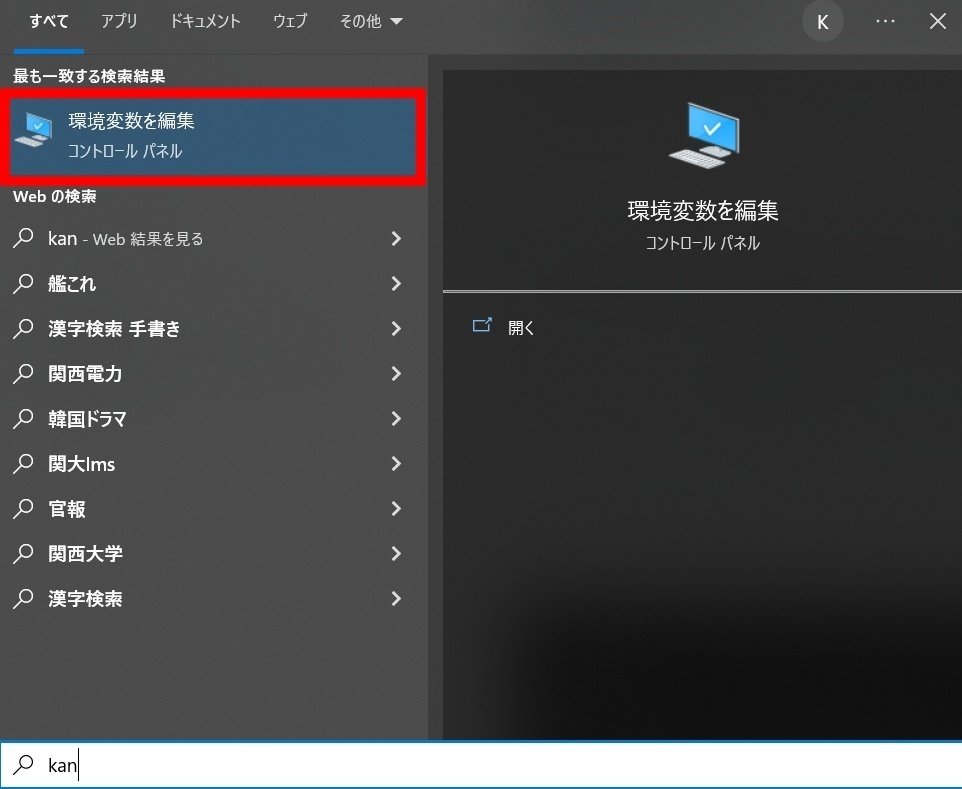
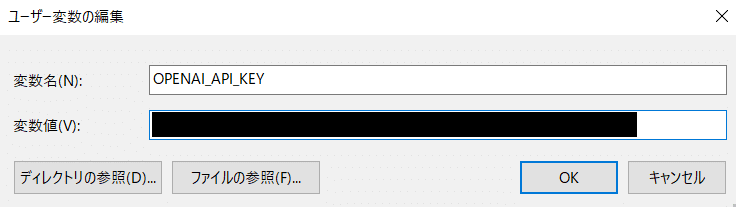
それをクリックして編集画面を開き、新規でAPIキーを登録します。
変数名:OPENAI_API_KEY
変数値:コピーしたOpenAIのAPIキー
ソースコード側では、例えばこのようにAPI keyを指定します。
import os
# OpenAI APIkey
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
もう一つ、今回は画像生成AIを使うために、ReplicateにサインインしてAPIキーを取得します。
右上の「Sign in」から、GitHubアカウントでサインインしてください。
GitHubアカウントの作り方については、ここでは省略します。
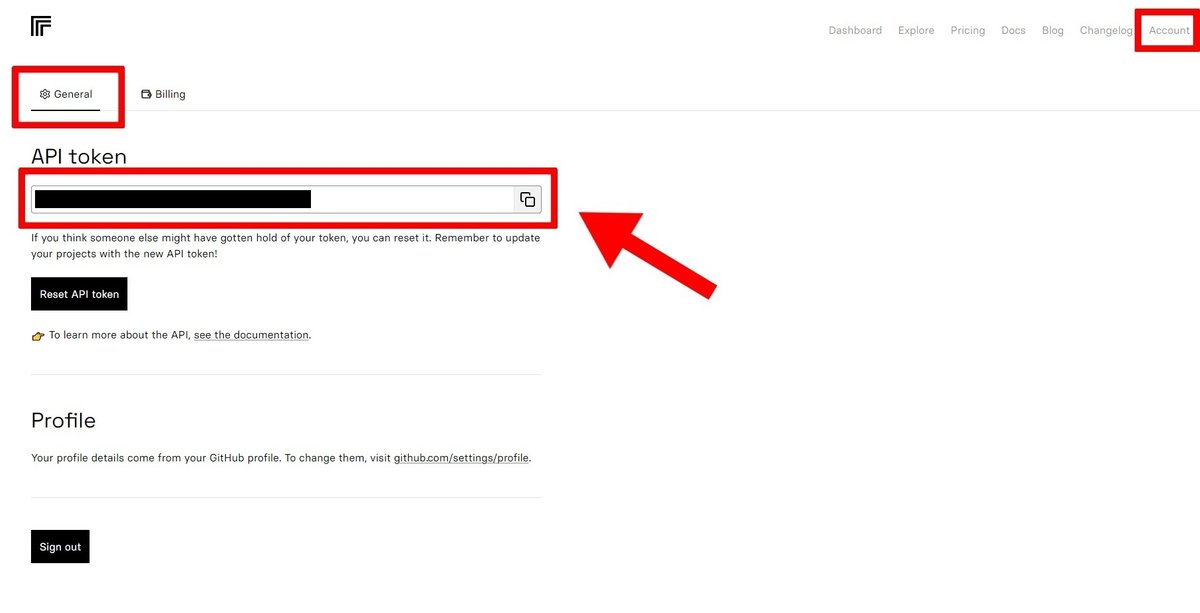
サインインしたら「Account」>「General」タブに進み、API Tokenをコピーします。
こちらもOpenAIのAPIキーと同じように、「環境変数の編集」の編集画面を開きます。
「新規」をクリックして、以下のように環境変数を入力します。
変数名:REPLICATE_API_TOKEN
変数値:先ほどコピーしたAPI Token
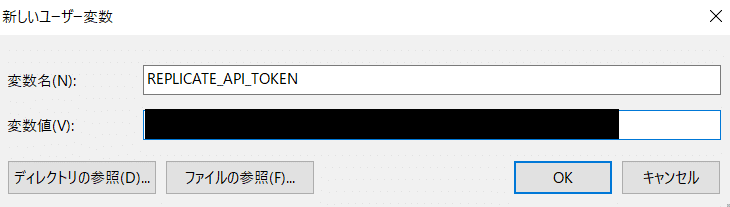
「OK」をクリックして、環境変数が登録されていればOKです。
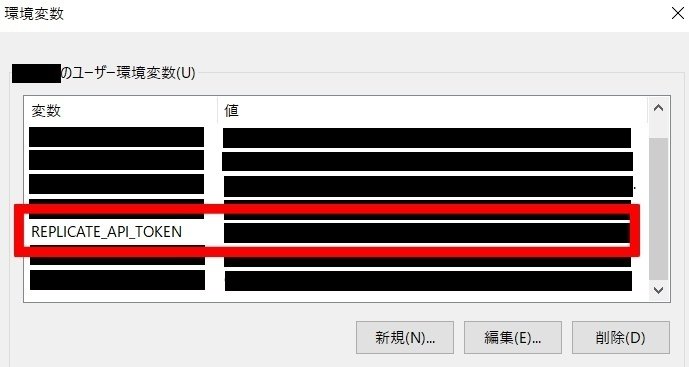
ソースコード側では、例えばこのようにAPI Tokenを指定します。
# Replicate APIkey
REPLICATE_API_TOKEN = os.environ["REPLICATE_API_TOKEN"]
これで、環境変数の準備は完了です。
画像生成AI用プロンプトとシナリオの生成
今回のアプリを作るにあたって、ChatGPTにテーマを投げて、画像生成AI用プロンプトとシナリオを作成する仕組みにしました。
実際にChatGPTのAPIをたたいて実装しても良かったんですが、ChatGPTのAPIは1回ごとに記憶が消える仕様となっています。
つまり、文脈を理解したうえで回答させるには、それまでの文脈をもう一度情報として与えないといけないんですね。
そこで、スマートに実装するためにLangChainが活躍します。
”LangChainって何?”については、以下の記事が分かりやすくて参考になりました。
いくつかあるモジュールのうち、今回は複数の入出力をつなげられる「Chains」を使います。
と、その前に
LangChainで使用するLLMのモデルについて注意すべき点の話をしておきます。
公式ドキュメントのサンプルコードでは”OpenAI”で書かれている部分が多いのですが、これは「GPT-3」(text-davinci-003) が指定されている状態となります。
これを”ChatOpenAI”に書き換えることで、「ChatGPT API」 (gpt-3.5-turbo)を使えるようになります。
# Instantiate a ChatOpenAI model for generating language
llm = ChatOpenAI(temperature=0.9)以下の記事を読んだときに初めて気づくことができ、分かりにくい部分かと思ったので共有しておきます。
話を戻します。
複数の入出力をつなげるため、LangChainの「Chains」モジュールを使用します。
具体的には「Sequential Chains」を使って、ChatGPTによる処理を連続して実行させました。
つまり以下の 1. と 2. の処理をつなげた、連続したチェーンを作ることにしました。
入力されたテーマから、画像生成AI用のプロンプト(の一部)を作成する
画像生成AI用のプロンプトから、関連する文章(シナリオ)を作成する
では、各チェーンの詳細を見ていきましょう。
一つ目のチェーン
一つ目のチェーンでは、画像生成AI用のプロンプトを作成することが目的です。
Stable Diffusionなどの画像生成AIを触ったことがある方はイメージできると思いますが、プロンプトって、画像内に描きたい内容でタグ付けしていく感じで英単語を羅列していくんですよね。
だから一つ目のチェーンでChatGPTに投げるテキスト(template)には、「テーマに関連する英単語をコンマ区切りで50個出力してね」という内容を指示しています。
# Create an LLMChain for generating a prompt based on the given theme
template = """
As a professional scenario writer, please list 50 English words separated by commas that vividly and precisely describe a cute girl's illustration based on the given theme and the following criteria with an imaginative and extravagant idea.
Criteria: Imagine and express an illustration that includes the following information with an imaginative and extravagant idea.
Infomation: Action, clothing, eye color, gaze, hair color, hairstyle, hair length, expression, clothing, top, bottom, accessory, posture, worldview, composition, location, three things in the surroundings, time, three fantasy-cute worldviews.
Theme: {theme}
English words:
"""
prompt_template = PromptTemplate(input_variables=["theme"], template=template)
sd_prompt_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="sd_prompt")二つ目のチェーン
二つ目のチェーンでは、画像に付随するシナリオを生成することが目的です。
一つ目のチェーンで生成された英単語をもとにした文章を作成してもらいたいので、一つ目のチェーンの出力結果をそのまま入力として用いて、文脈を理解させたうえでシナリオを作成してもらいます。
このtemplateには、「文脈に沿って100ワードのあらすじを書いて」という感じで指定しました。
# Create an LLMChain for generating a story synopsis based on the prompt
template = """
As a professional scenario writer, please write a 100 WORD synopsis of the first story that is both metaphorical and poetic without using the English words given as sd_prompt.
sd_prompt: {sd_prompt}
synopsis:
lang:ja
"""
prompt_template = PromptTemplate(input_variables=["sd_prompt"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="synopsis")次に、SequentialChainを使って、これら2つのチェーンをつなげて処理するためのチェーンを作成します。
二つのチェーンをつなげたチェーン
input変数にテーマ、output変数に画像生成AI用のプロンプトとシナリオをそれぞれ指定しています。
# Create a SequentialChain
overall_chain = SequentialChain(
chains=[sd_prompt_chain, synopsis_chain],
input_variables=["theme"],
output_variables=["sd_prompt", "synopsis"],
verbose=True,
)ちなみに、ChatGPTに投げるテキストは英語で書いておくことをおすすめします。
学習量の違いから、日本語よりも回答精度が上がることが知られています。
また、日本語よりもトークン消費が少ないのでお財布にも優しい(!)ことがメリットです。
ただ、英語で入力したら、もちろん通常は出力も英語で返ってきます。
でも今回の場合、シナリオ出力は日本語にしたい。
じゃあどうするの、という話なんですが、
私がよく使う手法は、ChatGPTに投げるテキストの最後に「lang:ja」をつけることです。
この方法、簡単に安定して出力言語を切り替えられるので結構おすすめです。
「Please be sure to answer in Japanese.」みたいな文章を追加してもいいんですが、なるべく短く楽に指定したいので。。
AI画像生成
先ほど、LangChainを使って以下の2つの処理を繋げました。
入力されたテーマから、画像生成AI用のプロンプト(の一部)を作成する
画像生成AI用のプロンプトから、関連する文章(シナリオ)を作成する
ここでは、作成したプロンプトを使って画像生成AIにイラストを作ってもらう部分を解説します。
環境構築のところでAPI Tokenを取得した、Replicateを使います。
このサービスは、クラウド上にアップされた機械学習モデルを実行することができるものです。
ある程度は無料で使えるようですが、API使用量が一定以上になると(あるいは一定期間?)、有料になるそうです。
数十回APIを叩いていますが、私は今のところ無料の範囲内で使えています。
「Explore」タブから機械学習モデルを確認することができます。
今回はtext-to-imageで二次元イラストの生成を行うので、「Diffusion models」の中から「anything-v3-better-vae」を使わせてもらいました。
(リークモデルが含まれているかどうか、という議論はあるかと思いますが、ここでは言及しないでおきます)
私は試していませんが、自分でモデルをアップロードすることもできるみたいですね。
「API」タブ > 「Python」をクリックすると、どのように実行すればいいかが書いてあります。
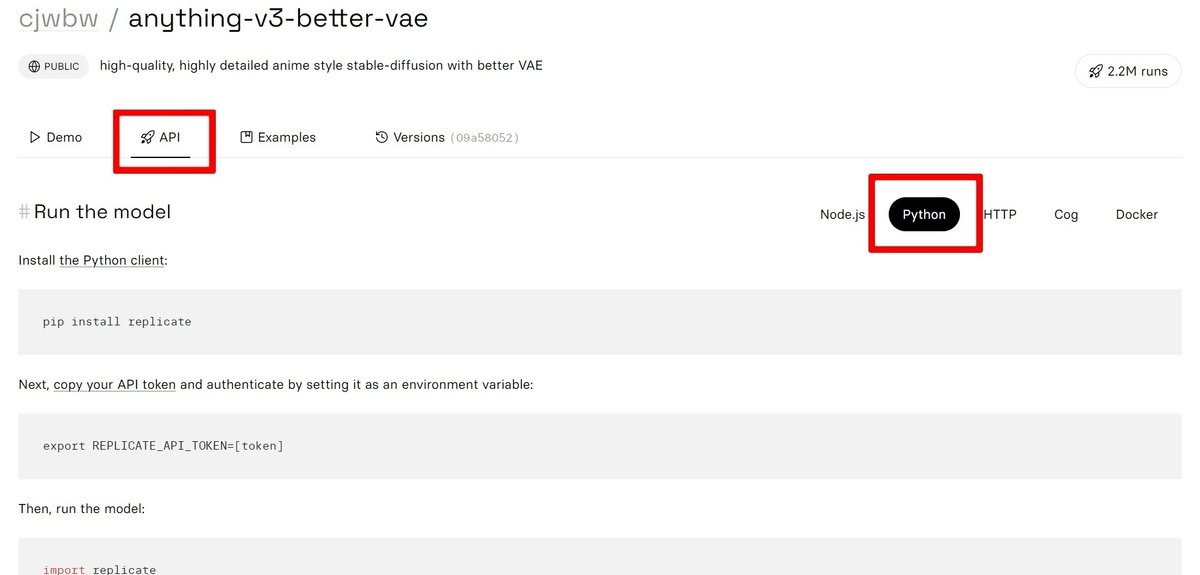
promptの値は、私がよく使っているpromptをベースにしたものに書き換えてあります。
途中で出てくる「prompt」という変数に、一つ目のチェーンで生成した50個の英単語が入るようにしています。
output = replicate.run(
"cjwbw/anything-v3-better-vae:09a5805203f4c12da649ec1923bb7729517ca25fcac790e640eaa9ed66573b65",
input={
"prompt": """(masterpiece), (best quality), [watercolor], a picturesque scenery, (1girl:1.3),"""
+ prompt
+ """(loli:1.2), field of depth, light particles, backlighting, pale color, gradient, petals,""",
"negative_prompt": "sketch, lowres, outline, nsfw, worst quality, low quality, vivid, breasts, animal, fat, jewel, jpeg artifacts, signature, watermark, username, blurry, neon, horror, brack, dark,",
"scheduler": "DDIM",
"width": 768,
"height": 512,
"guidance_scale": 8,
},
)他にもinputの値を変更したい場合は、 https://replicate.com/cjwbw/anything-v3-better-vae/api#inputs の情報をもとに好きな値を指定します。
指定するプロンプトや選択するschedulerによる違いなどは、好みによって違うのでここでは割愛させていただきます。
すでにいろんな方が情報を出していると思うので、詳しく知りたい方は調べてみてください!
テキストから音声への変換
テキストから音声への変換には、VOICEVOXのAPIを利用しました。
VOICEVOXをインストールして起動しておくだけでローカルHTTPサーバーが立ち上がり、音声合成エンジンが使えるようになります。
GUIが不要な場合はDockerイメージを利用することもできるそうですが、とりあえず私はシンプルに、インストール→起動の方法で行いました。
VOICEVOXの部分の実装は、以下の参考文献を参照して、ほとんどそのまま使わせてもらいました。
参考文献:
変えた部分はspeaker IDくらいです。
speaker IDを変えると、キャラクター・声のニュアンスを変えることができます。
speaker IDの確認方法
VOICEVOXを起動して、ブラウザから以下のURLにアクセスすると閲覧できます。
http://localhost:50021/speakers
VOICEVOXについてもっと詳しく知りたい方は、音声合成エンジンの公式リポジトリ(日本語)を見てみるのが参考になると思います。
アプリの実行
ここまでつらつらとソースコードについて解説してきましたが、最後にアプリの実行手順を説明しておきます。
Pythonで書いたコードを簡単にWebアプリとして実行するために、streamlitというパッケージを使っています。
Webアプリ内に配置できるオブジェクトがあらかじめ作られているため、HTMLをほとんど書かずにフロントエンドを作ることができます。
デザイン性を求めず、簡易的にWebアプリを実装する分には非常に重宝するパッケージです。
このパッケージを使うにはstreamlitのアカウントを作成する必要がありますが、その方法は調べれば詳しい記事がたくさん見つかると思うので参考文献の紹介に留めておきます。
で、実際に実行するときは、ローカルにコピーしたリポジトリに移動し、ターミナルで以下の通りに入力してください。
streamlit run main.pyローカルのHTTPサーバーが起動し、ブラウザにstreamlitの画面が表示されれば起動完了です。
あとは、ChatGPTに投げるテキストを変えるなり、画像生成AI用のプロンプトを変えるなり、いろいろ遊んでみてください!
その他にも、面白い使い方があったらぜひ教えてください!
以上、長文となりましたが、最後までお読みいただきありがとうございました。
面白そう!という気持ちだけで色々触っていたら、非エンジニアでもここまでやりたいことができるようになったよ、という布教のための記事でもありました。
ただ、私は趣味でAIと遊んでいるだけなので、技術面を正しく理解できていない可能性があります。
もしうまく動かなかったり、ここの説明が間違ってるよ、という部分があれば教えてください!
Twitter(https://twitter.com/RaisCorr)のDMでも構いません。
激動の生成AI時代の中、皆さんも楽しんでAIと戯れることができますように。
以降は、ご支援していただける方に向けた部分と、ただのポエムです。
特に内容はありませんが、もし投げ銭してもいいよ、と思う方がいましたらご支援いただけたら嬉しい限りです。
ここから先は
¥ 500
この記事が気に入ったらチップで応援してみませんか?