
今からでもRAG入門 ~ Hello, RAG ~

はじめに
どうも、山口です。
みなさん、LLMを使ったアプリを作ったことはありますか?
今回はLLMアプリの登竜門であるRAGへ入門することを目指して書いていき
たいと思います。
話す内容はざっくり以下の通りです。
RAGの仕組み
RAGの実装
「RAGあり」と「RAGなし」の回答を弊社のリサーチャーの方々にどちらが回答として正しそうか判断してもらいました!
RAGのユースケース
RAGの評価(分量少なめ)
RAGのセキュリティ(分量少なめ)
RAGについて知っているだけで、LLMを使ったアプリのアイデアの幅が上がるので、ぜひここで押さえておきましょう!
弊社のリサーチャーの方々に「RAGあり」と「RAGなし」でどちらが回答として正しそうか判断してもらいましたのでぜひ読んでみてください!
RAGの仕組み
RAGとは?
RAGはRetrieval-Augmented Generation の略で、簡単にいうと
「質問に対して与えられたドキュメントやDBから関連しそうなものを検索(Retreive)して、その内容から回答を生成(Generate)する」仕組みのことを言います。
もっと簡単にすると
「持ってるデータから検索(Retreive)して、検索結果を使って生成(Generate)する。」です
なので、RAGは検索と生成の二つのフェーズから成り立ちます。
下の図が全体像になっています。

ユーザーが質問をシステムに投げると、その質問を使ってデータストアに検索(Retrieve)をしにいきます。
関連したデータが見つかれば、それを取得してユーザーの質問と合体させてLLMに投げます。
最後に投げられたプロンプトからLLMは回答を生成します。
仕組みとしては難しくないですね。
検索方法の種類

さらに検索の方法はデータストアの種類によって様々です。
ここでは例としていくつか例を上げておきます。
ベクトル検索

検索したいドキュメントとクエリをEmbeddingしてベクトル化し、ベクトル間で比較(cos類似度などで比較)することで意味的に近いかどうかを判別して、近いものを取得します。
全文検索(キーワード検索)

文書内に含まれるキーワードをインデックス化し、ユーザーのクエリに含まれるキーワードが文書内にどのように現れるかを基に検索を行います。
ナレッジグラフで検索

ユーザーのクエリに基づいて関連するエンティティとその接続を分析し、クエリに関連するノード(実体)を特定し、それらのノードが持つ関係性や属性を通じて、意味的に関連する情報を絞り込んで提供します。
RDBのデータベースから検索

データストアの作り方
もう少し踏み込んで、最初に実施するであろうベクトル検索するためのデータストアの作成方法について解説します。
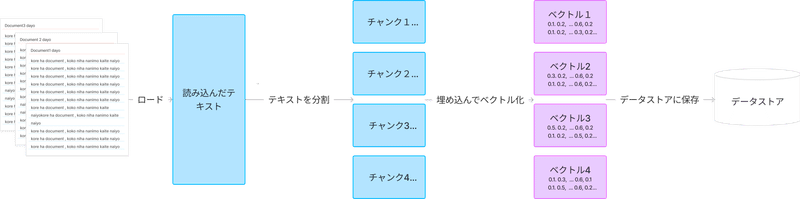
実際にコード上でも上記のステップでデータストア(Retriever)を作成します。解説すると
ドキュメントを読み込んで、テキストにパース(解釈)する
パースされたテキストを分割してチャンクを作成する。
→ LLMが入力を受け付けるコンテキストのサイズに変更しないといけないので分割する。
チャンクをベクトル検索かけれるように、ベクトル化する。
ベクトル化したチャンクをデータストアに入れ検索できるようにしておく。
これでいつでも使えるベクトルデータを格納するためのデータストアであるベクトルインデックスの完成です!
このデータストアから、クエリを使って検索して出てきた結果をContextとしてプロンプトに渡します。
何のためのRAG?
仕組みは理解していただけたと思うので、LLM単体ではなくてRAGを使うメリットもおさえておきましょう。
まだ学習に入っていないドキュメント情報や、社内ドキュメントなどもLLMが使えるようになる。
だからハルシネーションを防ぐことができるよ。
ファインチューニングなどの基盤寄りの話とは違って、基盤になるLLMの上で使える手法なのでより安価にできる。
言語モデル系の特定のタスクにおいてはファインチューニングよりいいとの噂もある。
RAGを実装しよう
Google Colab + Python + LangChainでRAGを実装します
実装内容:PDFに質問して、正しい回答が返却されるかを検証します。
前準備
まずは必要なライブラリをinstallしましょう
%pip install --upgrade --quiet langchain langchain-openai faiss-cpu tiktoken pypdf rapidocr-onnxruntime次にモデルなどの設定をします。今回はAzureOpenAIを使用します。
import os
import openai
import getpass
from langchain_openai.chat_models import AzureChatOpenAI
from langchain_openai.embeddings import AzureOpenAIEmbeddings
# 環境変数の設定
os.environ["OPENAI_API_KEY"] = getpass.getpass()
openai.api_key = os.environ["OPENAI_API_KEY"]
azure_configs = {
"base_url": your-azure-base-url,
"model_deployment": your-model-deployment,
"model_name": "gpt-35-turbo-16k",
"embedding_deployment": your-model-deployment-embedding,
"embedding_name": "text-embedding-3-large",
}
azure_model = AzureChatOpenAI(
openai_api_version="2023-05-15",
azure_endpoint=azure_configs["base_url"],
azure_deployment=azure_configs["model_deployment"],
model=azure_configs["model_name"],
validate_base_url=False,
)
# init the embeddings for answer_relevancy, answer_correctness and answer_similarity
azure_embeddings = AzureOpenAIEmbeddings(
openai_api_version="2023-05-15",
azure_endpoint=azure_configs["base_url"],
azure_deployment=azure_configs["embedding_deployment"],
model=azure_configs["embedding_name"],
)Retriverの構築
まずはデータストアの作成から行います。上記でも記載しましたが以下の流れで実装します。
1. ドキュメントを読み込んで、テキストにパース(解釈)する
2. パースされたテキストを分割してチャンクを作成する。
3. チャンクをベクトル検索かけれるように、ベクトル化する。
4. ベクトル化したチャンクをデータストアに入れ検索できるようにしておく。
1. ドキュメントを読み込んで、テキストにパース(解釈)する。ここでは、QunaSysのADAPT-QSCIの論文を読み込ませましょう

from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("https://arxiv.org/pdf/2311.01105.pdf", extract_images=True)
pages = loader.load()2. パースされたテキストを分割してチャンクを作成する。

from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
print('creating documents ... ')
texts = text_splitter.split_documents(pages)3. チャンクをベクトル検索かけれるように、ベクトル化する。

from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
embeddings = azure_embeddings
db = FAISS.from_documents(texts, embeddings)4. ベクトル化したチャンクをデータストアに入れ検索できるようにしておく。

retriever = db.as_retriever()
//こんな感じで関連文書を検索できるよ
question="what is ADAPT-QSCI"
docs = retriever.get_relevant_documents(question)プロンプトを用意する

ではプロンプトを準備してください。一つ前でもquestionは定義しましたが、分かりやすいようにここでも定義しておきます。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
question="what is ADAPT-QSCI"
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| azure_model
| StrOutputParser()
)回答を生成する

最後にLLMを実行し回答を生成します。
chain.invoke(question)これで実装自体はおしまいです。最後に「RAGあり」の時と「RAGなし」の時の比較をしましょう。
RAGありとRAGなしの比較(弊社リサーチャーにアンケートをとりました)
以下の質問で「RAGあり」と「RAGなし」の比較しました。
質問:what is ADAPT-QSCI
RAGありの回答
ADAPT-QSCI is a quantum-classical hybrid algorithm for calculating the ground state and its energy of a quantum many-body Hamiltonian. It is a method that proposes an adaptive construction of a quantum state for the quantum-selected configuration interaction (QSCI) method. ADAPT-QSCI iteratively grows the input state for QSCI by running QSCI repeatedly. It aims to yield accurate ground-state energies for small molecules, including in noisy situations, and takes advantage of current noisy quantum devices.
(日本語訳)
ADAPT-QSCIは、量子多体ハミルトニアンの基底状態とそのエネルギーを計算するための量子-古典ハイブリッドアルゴリズムです。ADAPT-QSCIは、量子選択配置相互作用(QSCI)法に適応的な量子状態の構築を提案する手法です。ADAPT-QSCIは、QSCIを繰り返し実行することで、QSCIの入力状態を繰り返し成長させます。ADAPT-QSCIは、QSCIを繰り返し実行することで、QSCI用の入力状態を成長させます。ADAPT-QSCIは、ノイズの多い状況を含む低分子の正確な基底状態エネルギーを得ることを目的とし、現在のノイズの多い量子デバイスを利用します。
RAGなしの回答
ADAPT-QSCI stands for ADAPT-Qualitative Systems Comparative Analysis. It is a method used in the field of systems analysis and modeling to compare and analyze different qualitative models of complex systems. The approach involves translating different qualitative models into a common formalism and then using various techniques to compare and analyze these models. ADAPT-QSCI helps in understanding the similarities and differences between different models and identifying the strengths and weaknesses of each model in representing the system being studied.
(日本語訳)
ADAPT-QSCIはADAPT-Qualitative Systems Comparative Analysisの略。システム分析およびモデリングの分野で、複雑システムのさまざまな質的モデルを比較・分析するために使用される手法である。この手法では、さまざまな質的モデルを共通の形式論に変換し、さまざまな手法を用いてこれらのモデルを比較・分析する。ADAPT-QSCIは、異なるモデル間の類似点と相違点を理解し、研究対象のシステムを表現する上での各モデルの長所と短所を特定するのに役立ちます。
この回答をリサーチャーの方に見てもらいました!
私自身から見ても、「RAGあり」の方が正しそうなのですが、しっかりと正しさを担保するために弊社のリサーチャー陣にも判断してもらいました!
まず以下の感じでSlackで質問してみました。「RAGあり」がAで、「RAGなし」がBです。どちらが「RAGあり」か「RAGなし」かはわからないようにして質問しています。

回答してくれた人全員がAと答えていますね!「RAGあり」の方がまず正し位ことが分かりますね!

「RAGあり」の生成に関してもリサーチャーからいくつかコメントもらいましたが、「RAGあり」の生成は大体正しいみたいです!
ですが、若干「RAGあり」の生成にも気になるところがあるみたいです!

身近に正しさを確認できる専門家がいるの、最高!!!
総評ですが、RAGなしではめちゃくちゃハルシネーションが起きていますね。2023年11月の論文でおそらくChatGPTの学習に入っていないので、ハルシネーションがおきた可能性がありそうです。
現状学習に入っていない内容はRAGありがかなり有利そうですね。
RAGのユースケース
まだ学習されていない最新のドキュメントを読み込みたい時
LLMが強くないドメイン知識を使用したい時
社内ドキュメントなどの学習に使用できないドキュメントを読み込ませたい時
などです。今これ以外思いつかないのですが、他にも色々使い道はあるかもしれません。
RAGの実際の使用事例
Sonia Health
メンタルヘルス用のAIで、RAGで心理学の知識を取得するようにしているみたいです。
ただRAGやプロンプトチューニングするだけだとあんまりやりたいことができないから、エージェントなどでレイヤーを構成して、レイヤーごとにドメイン知識を持たせることでドメインに寄った柔軟な回答ができているとのこと。
レゾナック
今までに蓄積してきたデータや文書を、生成AIで対話形式で活用できる社内システム「Chat Resonac」を作成しているようです。
大成建設
建設業でもドメイン知識を活用するために使用しているみたいですね。
HPに持っていた課題などが書かれていて興味深いですね。
当社はこれまで各種技術の知識や知見を蓄積した膨大な社内書類の技術データ・資料を有効活用してきました。しかし、これらの保有資料から利用者が必要とする情報を的確に検索し信頼性の高い情報を抽出して活用するのは容易な作業ではなく、多大な時間と労力を要してきました。一方、各種の質問に対しても様々な情報を統合し即座に柔軟な回答が得られるツールとして「生成AI」の利用が急速に進んでいます。しかしながら、一般公開されている既存の生成AIには、質問・回答に関する情報も学習データに取り込まれることによる情報漏洩リスクや、誤った情報に基づく不正確な回答が提供される懸念があることなどが有効活用に当たっての課題となっています。
トクヤマ
社内向けに文章作成や社内データに関することを聞けるようにしているみたいですね。
他にも色々と見つけることができるのでみなさん探してみてください。
面白かったのは、やはりLLMに対してセキュリティの懸念していることからChatGPTをそのまま使うのではなくて、Azure OpenAI Serviceを使用しているところが多いですね。
RAGのGがいらないケースも?
何もRAGといえど、Generateしなくてもよかったりします。
例えば、社内のDBがあったとしても基本はキーワード検索になると思います。キーワード検索だけでは文意を汲み取りきれない可能性があり、ほしい結果が出てこなかったりします。
しかしRAGで使っているベクトル検索などを使うと意味的な検索までできるので、欲しかった情報を取得することもできるようになるかもしれません。
ChatGPTで生成するだけでお金かかっちゃうし、RAGで完全にハルシネーションが防げるわけではありません。
なので生成が必要ないなと思うのであれば、ベクトル検索だけでも使ってみるのはいかがでしょうか?
この辺りは以下の記事に書かれていますのでご参考に
RAGの評価について
最近ではRAGASなどのRAGの精度評価指標ができてきています。
継続的にRAGを改善していくためには必ず必要になってきます。
詳しくは、以下のnoteに書いているので興味のある方は覗いてみてください。
RAGのセキュリティに関して
社内ドキュメントなどをRAGで使うときにセキュリティ的な懸念が出てくると思います。
例えば以下が懸念されるのではないでしょうか?
アクセス制限:特定の社員しか閲覧権限を持たないドキュメントを閲覧権限の持たない社員が閲覧できてしまう可能性がある。
毎回RAGに全てのドキュメントを入れてしまうのではなくて、社員の一人一人の閲覧権限を見て状況に合わせてドキュメント範囲を決めて渡すようにRAGを作ることが大事になってきますね。
LLMへのデータ投入への不安に関してはRAGというよりLLMへのセキュリティ懸念なので言及は控えようと思います。以下にOpenAIのセキュリティに関して記載があるので、こちらを読むこと推奨します。
https://trust.openai.com/
最後に
CRSチームでは、化学の研究活動のサポートに向けて調査・開発を進めて行きます。もしお困りのことがありましたらお気軽に下記までお問い合わせください!