
パソコンが3時間掛けてノイズを作った

「総製作費xx億円のゲーム」「xx時間煮込んだカレー」とか、でかい数字で謳ってるものって、なんかすごく感じますよね。
実際、100%その数字が大きいほど良いものになるというわけではないと思うんですが、ものによっては「ワンチャンそうなるかも」と考えたりもします。
なので、本来ならシンセのキーボードを押そうものなら一瞬で作れる、「ホワイトノイズ」を約3時間掛けて作ってみました。
本当に良いものが出来るんでしょうか。楽しみです。
やってみる
参考にする音源を選択
リファレンス音源としてXfer Records Serumのノイズオシレータプリセットから「ARP white」を選ぶことにしました。
パラメータは初期の状態です
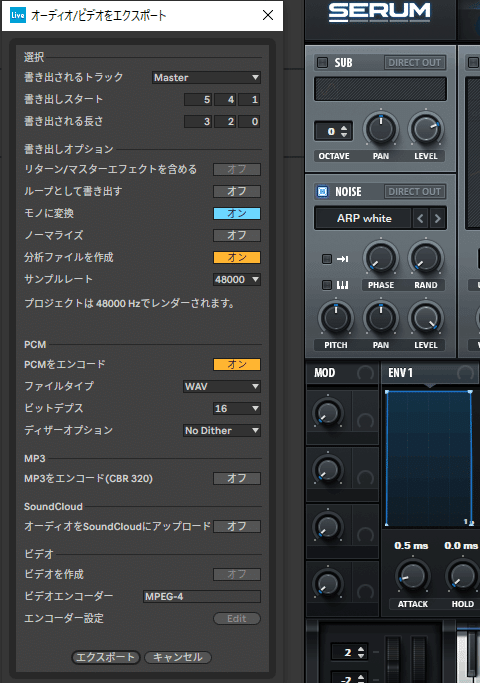
モノラル・ディザー無し・サンプリングレート48000Hz・ビット深度16ビットで書き出します
音源の内容確認
Pythonのwaveを使用してwavファイルを読み込み、データを見てみます。
import wave
import numpy as np
audio = wave.open('arp_white.wav','r')
buf = audio.readframes(audio.getnframes())
audio_data = np.frombuffer(buf, dtype='int16')
# オーディオデータ内容を見る
def audio_info_out(audio):
print(f'サンプリングレートは{audio.getframerate()}Hz')
print(f'ビット深度は{audio.getsampwidth() * 8}ビット')
print(f'チャンネル数は{audio.getnchannels()}ch')
print(f'サンプリング数は{audio.getnframes()}')
print(f'{audio.getnframes() / audio.getframerate()}秒分のデータ')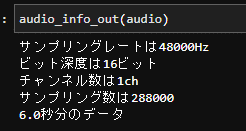
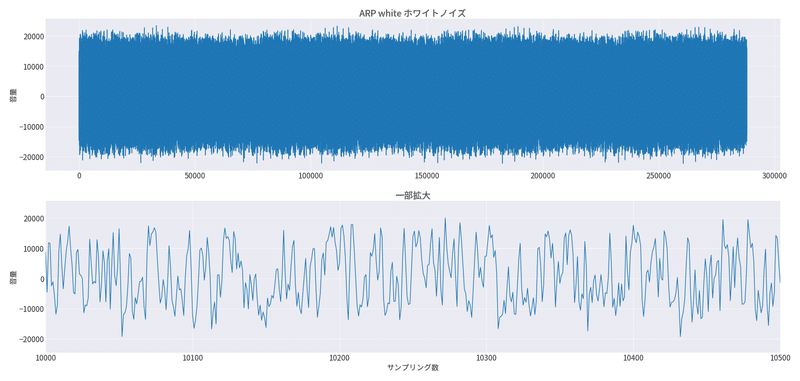
音声波形はこんな感じです。
16ビットなので - 32768 ~ 32767 までの整数値を取ります。
ですが、音量は控え目にしているのでおおまか±24000までの整数値を取っている形ですね。
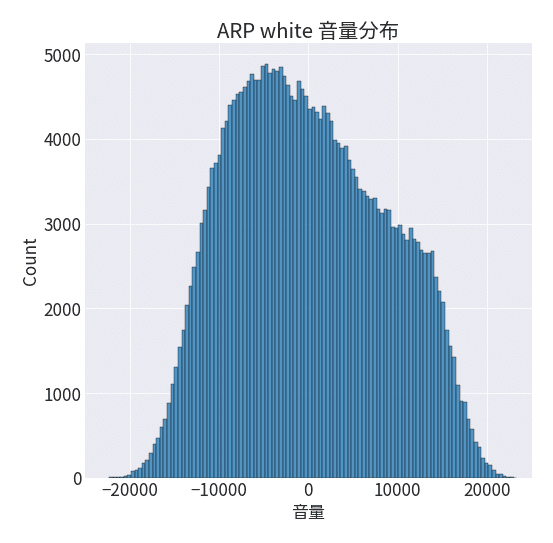
音声データの値の分布はこんな感じです。
ホワイトノイズなので、0を中心にした山ができると思っていましたが、ちょっと偏っているみたいですね。
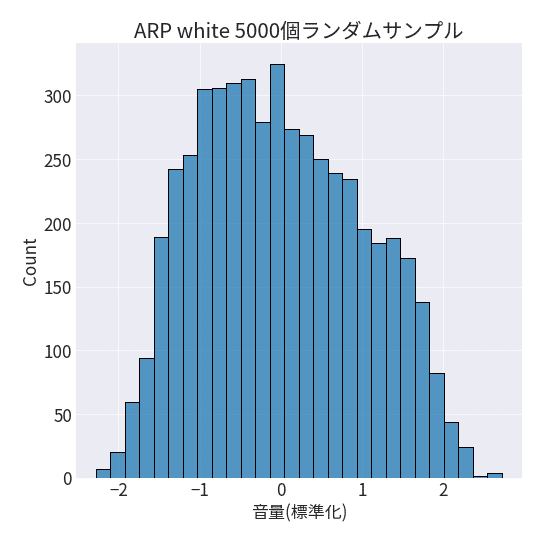
分布の形を形成するパラメータを探索する
ARP whiteの値の分布ですが、以下画像のように3つの正規分布から形成された分布っぽく見えます。

そこで、値を標準化してから上記3つの分布の初期パラメータを与えた上でARP whiteの分布になるように、パラメータを探索してあげます。
全てのサンプルを使用するのは多いので、ランダムに5,000個の要素を取得してからそれらを標準化します。
from sklearn.preprocessing import StandardScaler
import pymc3 as pm
import arviz as az
import pickle
# ランダムに5000個のデータを取り出す
rng = np.random.default_rng()
obs = rng.choice(audio_data, 5000, replace=False)
# 標準化
scaler = StandardScaler()
scaler.fit(obs.reshape(-1, 1))
obs_standard = scaler.transform(obs.reshape(-1, 1)).reshape(-1)
estimate_shape = 3 # 次元を3に設定
with pm.Model() as model:
# 仮定した3つの分布の採択率を探索
w = pm.Dirichlet('w', np.ones(estimate_shape))
# 3つ分布の期待値を探索
mu = pm.Normal('mu', mu=np.zeros(estimate_shape), sigma=1.0, shape=estimate_shape, transform=pm.transforms.ordered, initval=[-1.0, 0.0, 1.5])
# 3つの分布のばらつきを探索
tau = pm.Gamma('tau', alpha=1.0, beta=1.0, shape=estimate_shape)
# 標準化したARP whiteの音源を観測値として設定
x_obs = pm.NormalMixture('x_obs', w, mu, tau=tau, observed=obs_standard)
# 探索開始
with model:
trace = pm.sample(5000, n_init=10000, tune=2000, return_inferencedata=True, cores=16)
まずはIntel i7-7820Xの16スレッドすべてを使い6分弱フルパワーでパラメータを探索させます!
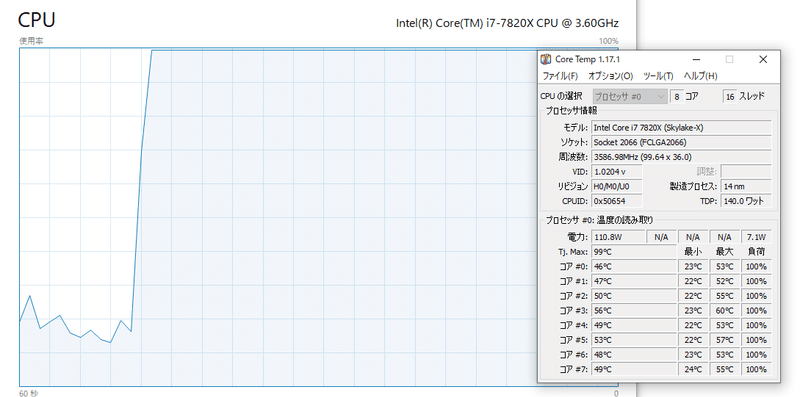
結果は以下のような形になりました
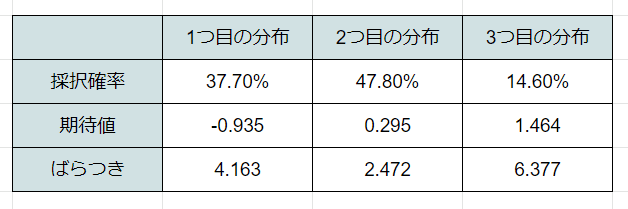
採択確率は3つの分布からどれか1つを選ぶ確率
期待値は山のてっぺん
ばらつきは山の裾の広さ(値が大きいほどばらつかなくなる τを使用 τ=1/σ^2 )
を表しています。
分布を予測
というここでここから約3時間処理を走らせます。
with model:
ppc_trace = pm.sample_posterior_predictive(trace, model=model, var_names=['x_obs'], keep_size=True, progressbar=True)
trace.add_groups(posterior_predictive=ppc_trace)
予測して得られたサンプルを取り出して、元々のARP whiteのデータと同じ数(288000個)ランダムに取り出します。
その後、標準化した値をもとに戻します。
x = trace.posterior_predictive.to_array()
x = x.to_numpy()
x_all = x.reshape(-1)
# ランダムに288000個のデータを取り出す
rng = np.random.default_rng()
x_pred_obs = rng.choice(x_all, 288000, replace=True)
# 標準化された値をもとに戻す
scaler = pickle.load(open('data_folder/obs_standard_data.pkl', 'rb'))
x_pred_restore = scaler.inverse_transform(x_pred_obs.reshape(-1, 1)).reshape(-1).astype(np.int16)こんな感じになりました。
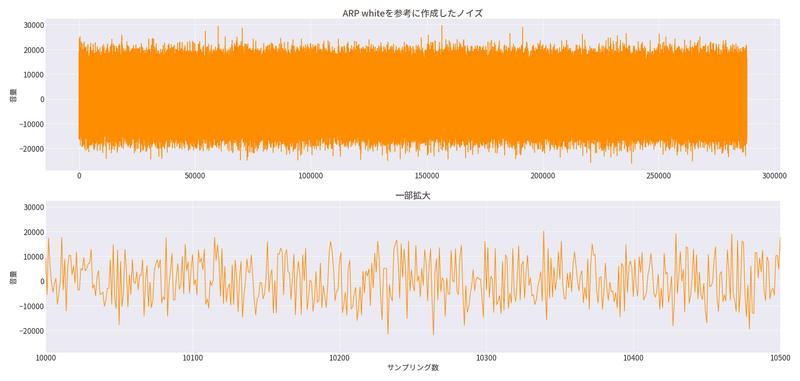
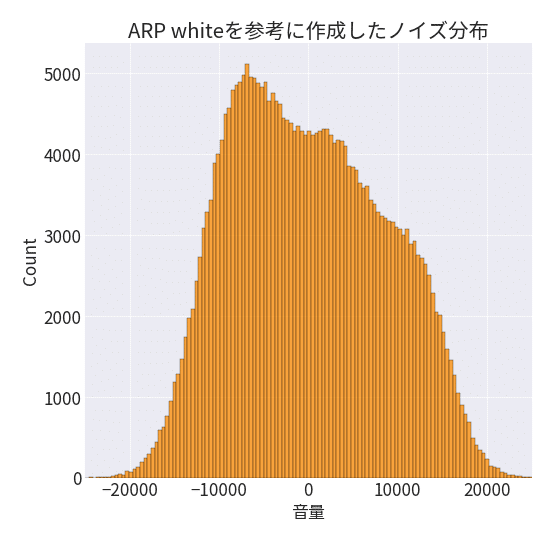
比較してみる
3時間掛けてノイズを作ってみたわけですが、ARP whiteより良いものになってるんでしょうか。
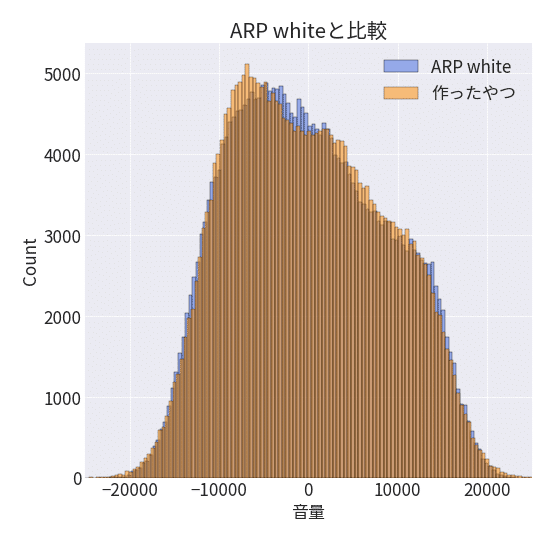
音が重要なので、書き出して比べてみます。
# オーディオデータを書き出す
def write_wave_audio(channel, bytedepth, framerate, framedata, file_name):
w = wave.Wave_write(file_name)
w.setnchannels(channel)
w.setsampwidth(bytedepth)
w.setframerate(framerate)
w.setnframes(len(framedata))
w.writeframes(framedata)
w.close()
write_wave_audio(1, 2, 48000, x_pred_restore, 'data_folder/生成ノイズ.wav')ARP whiteと生成したノイズをアップロードしていますので、もしよければ聴き比べてみてください。Aが「ARP white」Bが「生成したノイズ」です。
個人的には「似せたのに全然違うな」という感想です。
なんでこんなに違うくなるのか・・・
とりあえず結果としては生成したノイズのほうが優しい音のような気がする。(パソコンが)頑張って作った補正掛かってるかな
この辺りは私だけだと判断できないので、Twitterのアンケート機能で聞いてみました。協力いただいた方本当にありがとうございます🙇♂️
結果
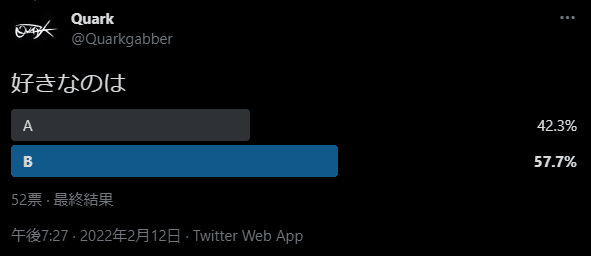
52票のうち、3時間掛けて作ったノイズが良いという回答は30票で57.7%でした。
過半数は超えましたが、差があるとは言えないですね。
うーんこれは・・・・
結論、「ノイズは1秒でシンセから出して、残りの2時間59分59秒で、曲を作る」が一番良いということですね🤯
そんなことは分かっていたんですがやめられなかった・・・くだらないネタにここまで付き合っていただき、ありがとうございました。
今後はこの時間はちゃんと作曲します。
その他
今回実行したコードはGithubにて公開しています。
また、動作環境はDocker Hubにて公開しています。
更に、何を行っているかの詳しい内容はQiitaにて公開しています。
※今回はわざと大きな時間が掛かるように設定しているので、効率の良い使い方ではないです。
この記事が気に入ったらサポートをしてみませんか?