
競馬:回収率100%の壁

この記事は壁アドベントカレンダー2021の12/21分の記事です。
こんにちはq_tarouです。今年の壁アドベントカレンダーでは競馬で回収率100%の壁に挑んだことについて書こうと思います。
1. 私と競馬
私は小学生のころに友人の影響でダビスタやギャロップレーサーにドハマリし、2000年ころから競馬を見始めました。テイエムオペラオー、メイショウドトウ、アグネスタキオン、ジャングルポケット、マンハッタンカフェ、ステイゴールド、シンボリクリスエス、ディープインパクト、etc …。ここでは挙げきれないほど非常に魅力的な馬が沢山走っていました。
個人的に最も印象深い馬はクロフネで、2001年の武蔵野Sおよびジャパンカップダートはあまりにも衝撃的でした。きっとドバイワールドカップやBCクラシックを始め、世界で活躍するに違いないと夢を見ましたが、残念なことに屈腱炎を発症してこのレースを最後に引退してしまいました。
その後社会人になって少し競馬から遠ざかっていたのですが、今年になってそのクロフネの娘・ソダシが活躍したり、某ウマコンテンツ娘が凄まじい流行を見せて私のtwitterタイムラインを埋め尽くす影響などもあって、少しずつ競馬に関心が戻ってきました。(ちなみにアニメ1 & 2期をN週しました。アプリは怖くて手を出していない。)
ただ、昔から賭け事はまるで駄目で、競馬も累計4000~5000円くらい賭けてみたものの回収率は数%くらいだったので最初はお金を賭けるつもりはありませんでした。しかし、ちょうど仕事でもデータを触る機会が増えてきたので「競馬で当てて手っ取り早くお金を増やしたい」「データをサポートに使ったらどれくらい回収できるのかな」「データを扱う勉強になるかも」という個人的な興味もあり、今年の初夏頃からデータを見ながら毎週競馬に勤しんできました。今回はその取り組みについて書きます。
2. データを利用した予測
2.1. データの収集
データを利用するためには、まずはデータを収集する必要があります。競馬は公開されているデータセットが無かったので、自分でウェブスクレイピングしてデータセットを作りました。
過去のデータは静的なデータが大半なので、pythonの requests でソースを取得し、 BeautifulSoup を使ってパースして正規表現ゴリゴリ書いて必要な要素を抽出しました。動的データはseleniumを使って取得しました。
データは過去10年+分の中央競馬のa)レース情報と b) そのレースに出場した馬の情報を以下のようにJSON形式で保存しました。
# a) レース情報
"race_date": "20210612",
"race_hour": 9,
"race_minute": 50,
"race_surface": "芝",
"race_distance": 1200,
"race_direction": "右",
"race_weather": "雨",
...
# b) 馬の情報
"horse_id" : xxxx,
"horse_sex": "牝",
"horse_age": 3,
"horse_weight": 474,
"horse_weight_diff": -2,
"time" : 68.7,
"time_3f" : 34.6,
...2.2. モデルの作成
問題の定義
何気に問題の定義が難しく、パッと思いつくだけでも
1:分類(クラスを予測:例、複勝圏内に入る/入らないを予測)
2:回帰(値を予測:例、馬のタイムやスコアを予測)
3:ランキング(順位を予測:例、そのまま順位を予測)
などが考えられます。直感的にはランキングの問題として捉えるのが良いかなと思ったのですが、色々と調べてみるとランキング学習は扱いが難しそうだったので、初手として今回は分類問題で解くことにしました。具体的には、
・入力:出走する馬のデータ+レースの情報
・出力:その馬が複勝圏内に入る/入らない
として解きました。
利用した特徴と手法
これは書き出すとキリが無いので割愛しますが、基本的にはスクレイピングしたデータの中から経験的に有効そうな特徴を作成し、sklearnに実装されている分類手法でエイヤとやっつけました。とりあえず一通り動くことを優先したので、ここはまだまだ要改善という感じです。
分類では複勝圏内に入る/入らないの2値だけでは情報として少なかったので、今回は predict_probaで得られた値をスコアとして出力しました。

評価
実際どれくらいパフォーマンスが出るのかを雑に確認しました。
学習データ:2010/1/1 ~ 2019/12/31の中央競馬のデータ
評価データ:2020/1/1 ~ 2020/12/31の中央競馬のデータ
比較手法:人気通りに賭ける(単勝なら1番人気、複勝なら1〜3番人気に賭ける)
評価指標:i) 1着の正答率 ii) 1着予想の単勝に賭けた時の回収率 iii) 複勝圏内の正答率
【比較手法】 (i) 0.3, (ii) 0.77, (iii) 0.48
【今回のモデル】 (i) 0.23, (ii) 0.79, (iii) 0.42という感じでした。1着や複勝圏内の正答率は比較手法(人気通り)に及ばないですが、回収率に関してはほぼ同等(少し良い?)くらいの結果が出ました。まだまだ全然使える感じではないですが、深く考えずに適当に試した最初のトライアルとしてはまぁ悪くないかなという感じです。
2.3. 予想において参考にしたその他のデータ
2.2.で作成したモデルの出力ももちろん参考にしましたが、流石に上記の性能だとそのままモデルの出力に従うのは厳しいということもあり、他にも枠番や位置取りなど様々なデータを参考にしながら予想をしていました。
顕著にデータが役に立ったケースとして、新潟・芝・1000mのレースを紹介します。以下に枠番と勝利数/複勝圏内数の関係、および脚質(位置取り)と勝利数/複勝圏内数の関係を示します。


圧倒的に外枠・逃げ馬が勝ちやすいというのがわかります。よく上記の条件では外枠が勝ちやすいという話を耳にしますが、実際にグラフにしてみるとこんなに偏りがあるんですね。もちろんデータ通りに決まらないこともありますし、こんなに偏ることは非常に稀ですが、このようなデータは予想をする上で大きなサポートになりました。
以上のように、適宜気になったデータを出力して参考にしながら予想して馬券を買う、という方針で運用してみました。
3. 今年の運用成績
今年は5/23のオークスからだいたい毎週1000~2000円くらい賭けていまし
た。回収率、収支などは以下の通りです。
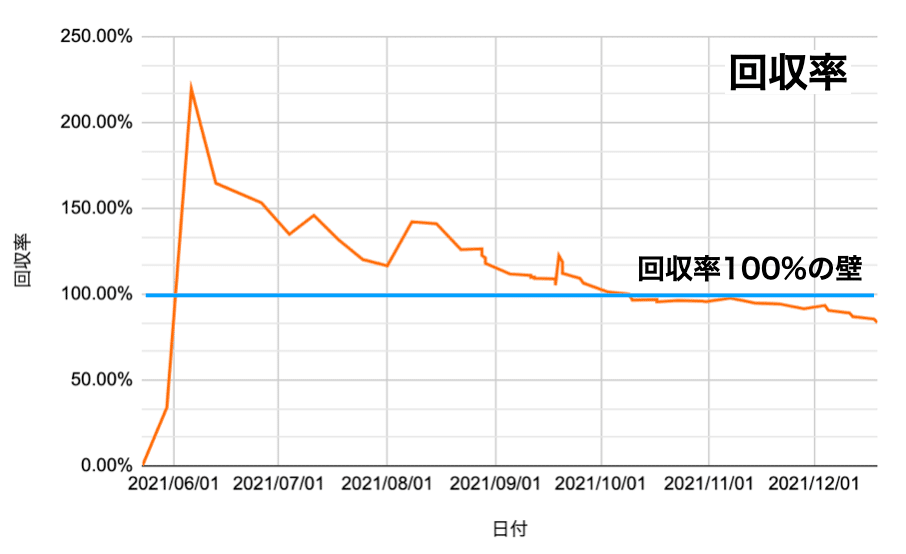

だいたい2~3ヶ月に1回程度大きめの馬券を当て、10月初旬までは回収率100%を超えていたのですが、秋のG1戦線が始まったあたりからじわじわとマイナスになり、最近はてんで駄目って感じです。そこまで戦略を変えたつもりは無いのですが、今回のやり方だと夏競馬の方が相性が良かったのかも知れません。
今年は残念ながら現時点で回収率100%の壁を超えることは出来ませんでしたが(まだ有馬記念とホープフルステークスがあるので一発逆転多少改善する可能性はあるかもしれません)、データをサポートにすることで従来(回収率:数%)に比べてかなり安定して回収できるようになったのかなと思います。来年は予測モデルの改善はもちろん、ある予算の中で最適な買い方とは何かをもう少し真面目に研究してみようかなと思います。
おわりに
本記事では競馬で回収率100%の壁に挑んだ詳細について書きました。
今年は久しぶりにガッツリ競馬を楽しみましたが、昔応援していた馬の子どもたちが走っているのを観ると、そのストーリー性もスパイスとなって楽しさが増しているように感じます。
今回の取り組みはデータを扱う上で勉強にもなったし、何よりエンターテインメントとして楽しかったので、我ながら味の良い取り組みだったなぁと思います。またどこかのタイミングで現地にも行ってみたいですね。
皆様も良い競馬ライフを。

この記事が気に入ったらサポートをしてみませんか?