RAIDとデータ化け|どうして起こる?どうやって防ぐ?→ZFS RAID ファイルのチェックサムを活用

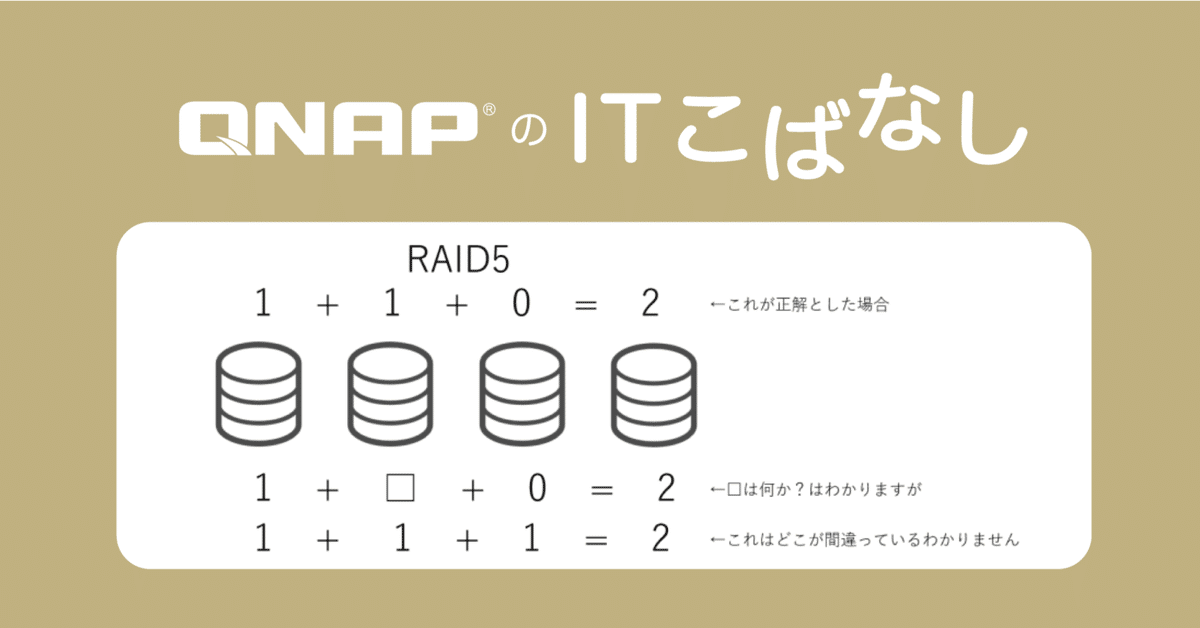
冒頭画像でRAID5のデータリカバリの仕組みについてご紹介しました。シンプルに記載しますと、RAID5の仕組みはこちらで表現できていると思います。
つまり、RAID5とは
n台でRAIDを構成した場合に、(n-1)台にデータを保存
1台に(n-1)台に保存したデータから生成されるパリティを保存し
構成するn台のうち1台の情報が丸々失われてしまった場合でも
残った(n-1)台から失われた1台のデータを再生成できる方法
となります。
冒頭部分の絵に戻りまして、添えてある計算式の意味を考えてみましょう。
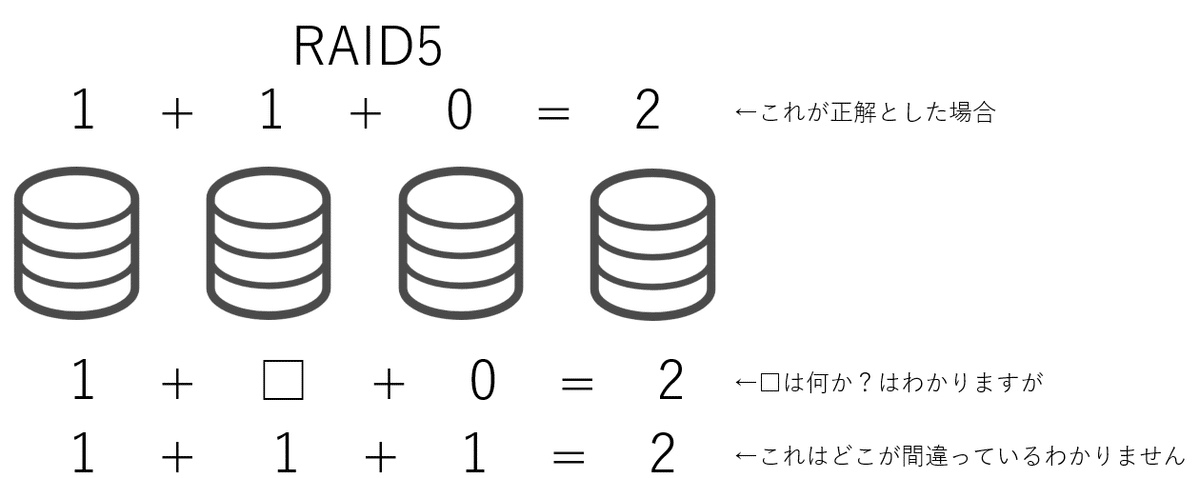
"="の左側がいわゆるデータとなり、"="の右側が"データから生成されるパリティ"となります。
一番上では、"1 + 1 + 0 = 2"となっており、RAID5に保存されるべきデータとパリティの状態を表しています。
下から2番目の式は、"1 + □ + 0 = 2"となっており、左から2番目のディスクが故障、データの読み取りができなくなった状態を表しています。当然ですが、□は計算して答えを出すことができ、"1"という形で一意に答えが定まります。
一番下の式では"1 + 1 + 1 = 2"となっており、左から3番目のディスクのデータが化けてしまった状態を表しています。この場合、2番目の1が間違っていると考えると"1 + 0 + 1 = 2"となりますし、1番目の1が間違っていると考えると、"0 + 1 + 1 = 2"となりますし、もしかしたら"="の右側が間違っていると考えると、"1 + 1 + 1 = 3"が正しいかもしれないと考えることができます。
これはすなわち何を表しているかというと、"RAID5ではディスクなどが丸々1個故障した場合はデータの復元が可能であるものの、データ化けが発生した場合は、どのデータが化けたのか特定できず、元のデータを復元することができない"ということを示しています。
こういった事情もあって、例えばLinuxのmdドライバ(RAID用のドライバ)では"データ読み取り時に整合性に問題があるかどうか?のチェックは行わず、データディスクからのみデータを読み出す"という動きになっています。
これが例えばRAID1で片方のディスク上のデータが化けてしまっているのであれば"RAIDからデータを読み出す度に異なるデータが読みだされる"となってしまいます。RAID5やRAID6であれば "データ部分がデータ化けしたのであれば、読み出す度に常に間違ったデータが読みだされる。という動きになりますし、パリティ部分のデータが化けたのであれば、リビルドした後(パリティのデータを使ってデータを再生成した後)間違ったデータが読みだされる(データ化けし、間違ったパリティデータから間違ったデータが復元されてしまう)" ようになります。
RAIDは確かにデータ故障といったリスクに備えることができますが、こういったデータ化けには備えることができません。
一方で、ZFS RAIDの場合はファイルシステムレベルでファイルのチェックサムを持っているので、データ化けが発生した場合でも自動的にデータを修復し、正しいデータをアプリケーションに返すことができます。
RAIDとZFS RAIDのデータ化けに対する挙動を確認してみる
ということで、RAIDを構成するディスクでデータ化けが発生した場合の実際の挙動を見てみたいと思います。QTSとQuTS heroでそれぞれ次のような操作をしてみて、どういった結果になるか?というところを確認していきたいと思います。

RAID1を構築
比較的大きめのデータ(WindowsのインストールディスクISOファイルなどを複数)を保存。Windowsクライアント or QTS/QuTS heroのコンソール上からチェックサムを確認
(実際にファイルが書かれているディスク上のLBAなどを知る方法を私が知らないので)RAIDを構成する特定のディスクを0書き(疑似的なデータ化けを発生させる)
Windowsクライアント or QTS/QuTS heroのコンソール上からチェックサムを確認。データ化け操作前に得られたチェックサムと比較する。
QuTS hero : ZFS RAIDの場合
ここでは、TS-h987XU-RP上でRAID1デバイスを作成しました。

ここで作成した"ZFS-RAID1"共有フォルダにWindows 11のインストールメディアである"Win11_22H2_Japanese_x64v1.iso"を書込みました。

ここで、データ化けを発生させる前のファイルのチェックサムを確認しておきます。c3e...561です。

チェックサムを確認したところで、sshでアクセスし、疑似的にデータ化けを発生させるべきデバイスを確認していきます。こちらより、zpool2に共有フォルダが作成されており、qzfs/enc_0フォルダ以下のデバイスがzpool2に組み込まれていることがわかります。

/dev/qzfs/enc_0にて該当デバイスを確認してみます。

zpool2に組み込まれているデバイスは、NVMeデバイス(今回はU.2 SSDを使っているので)へのシンボリックリンクであることがわかります。
ACT CorpさんのZFS解説書によると、パーティションの先頭1024セクターとおしり1024セクターにVDEVラベルという管理用のスペースがあるようなので、ここは触らず0書きをしていきます。(先頭512B x 1024セクター(256KB)をseekしたうえで100GBほど書込みする)


0書きが完了した直後のzpool2のステータスを確認してみます。

まだエラーに遭遇していないので(0書きで疑似的に化けさせたデータを読んでいないので)ステータスとしては健全といっています。
ここで再度Windowsクライアントからチェックサムを確認すると、疑似的なデータ化け発生前と同じチェックサム(c3e...561)が得られることが確認できます。

一方でもう一度sshコンソールの方からzpool2のステータスを確認してみると、チェックサムエラーが発生していたことが記録されています。

status部分には、"One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected. = 1つまたは複数のデバイスに回復不能なエラーが発生しました。エラーを修正するための試みが行われました。アプリケーションは影響を受けていません。"とあり "エラーを検出したもののデータが問題なく修復され、アプリケーションには影響がなかった"ことが記録されています。
また、この後何回かチェックサムを確認しなおすと、リカバリが完全に完了したのか、チェックサムの数字は上がらなくなりました(クライアントからのチェックサム確認時にNAS上でオンメモリになっていた分が何度か確認するうちにメディアから読まれるようになり、エラー訂正されたと推測します)
こちらの実験の通り、ZFSではディスク上でデータ化けが発生してしまった場合でも訂正し、正しいデータをアプリケーションに提供することが可能なことがわかりました。
QTS : Linux RAID(md)の場合
ここではQTSモデルである、TS-473Aを使って確認していきます。まずは同様にRAID1ボリュームを作成します。

md-raidという共有フォルダを作成し、isoファイルを保存します。

チェックサムを確認してみます。c3e...561です。

ということで準備ができましたので、ディスクに0書きをしてみたいと思います。まずは、md-raidフォルダがどこに作成されているか?という点からmdあたりまでを確認したいと思います。

という感じでmd2であることがわかります。あとは、md2を構成するディスクを確認すると、

と、sde3とsdd3を使ってmd2は構成されており、super blockバージョン1.0が使用されていることがわかります。dmが多層になっていて、正確なデータアドレスの場所がわかりませんので、mdのsuperblock+αくらいを考慮してデータ化けを発生させてみます。(ファイルシステムも破損させてしまう可能性がありますが・・・)
kernel.orgのRAIDのsuper blockのページでは、1.0はsuper blockはデバイスの最後にあるとのことです。

念のためディスク先頭にlvmのsuper block情報がないか?を確認してみますと、


0x18b00あたりまではlvmが使ってそうで、0x40b4aあたりはファイルシステムのsuper blockがありそうですので、0040c000以降を0書き(疑似データ化け)させてみたいと思います。
ZFS RAIDの時と同じように、sde3に対して、次のコマンドで0書きを行います。
dd if=/dev/zero of=/dev/sde3 bs=256KB seek=16 count=409600
Windowsクライアントからファイルのハッシュを確認してみます。

エクスプローラー上では一見正しくファイルがあるように見えますが・・・

md5の計算を行うとすると、エラーが発生して読み込むことができませんでした。

QTSのコンソールで確認すると、device-mapperがエラーをはいていました。単純にデータ部分のみを0書きでデータ化けさせることができなかったためと推測しますが、データ化けにより同様なdevice-mapperレイヤーでのエラーが発生し、データの読み取りができなくなってしまう可能性があることがわかります。
まとめ
今回はQuTS heroのZFS RAIDとQTSのLinux RAIDについてHDD/SSDのメディアのデータ化けに対する耐性を、メディアに対して直接0書き(疑似データ化け)をすることで比較してみました。
ZFS RAIDではHDD/SSDのメディアにデータ化けが発生した場合であっても、チェックサムを検出し、自動的に修復し、読出しをリクエストしたアプリケーションに対して正しくあるべきデータを返すことができました。
Linux RAIDではHDD/SSDのメディアにデータ化けが発生した場合、エクスプローラ上は一見データがあるように見えても、データ化けが発生した場所によってはデータが読みだせなくなることがわかりました。
これらの点からも、大切なデータ、企業の基幹データ、長期保管が必要な電子取引データなどは、万が一メディア上でデータ化けが発生した場合でも正しくデータを読むことができるQuTS heroをお使いいただくと、より安心してデータを保存していただくことができます。
また、今回は意図的に大規模なデータ化けを発生させましたが(データが格納されているアドレスがわかりませんでしたので、打てば当たる豆鉄砲的な意味合いが強いですが・・・)、普通の使い方をしている限りは、簡単にHDDやSSDでデータ化けは発生しません(※高温化で使用していたリ、振動が伝わってくる場所などではweak writeや、off trackが発生しやすくなりますのでご注意ください。) QTSでもHBS 3でのバックアップなどと組み合わせて、十分に安全にデータ保管していただくことが可能です。
世界有数のNASメーカー、QNAP株式会社の公式noteです。