
【Python】ChatGPTと外部データ連携!LlamaIndexでQ&Aアプリを作る。

Pythonの基礎を習得済みの方向けに、外部データを使うLlamaIndexの基本的な使い方を段階的に解説していきます。
Streamlitとは?
まずは、今回使用するStreamlitについて簡単に説明します。Streamlitは、WEBアプリを簡単に作れるPythonライブラリです。HTMLやCSSの知識がなくても、PythonコードだけでインタラクティブなWEBアプリを作成できます。
Streamlitの特徴
WEBアプリが簡単に作れる
HTML、CSSの知識が不要
デプロイが簡単
サーバー使用料が無料(Streamlit Community Cloud)
小さな組織やチームでのアプリ共有に最適
今回の内容
今回は、LlamaIndexを使って外部からデータを取り込み、ChatGPTと連携してQ&AができるWEBアプリを作成します。
具体的には、外部データとしてテキストファイルを読み込み、LlamaIndexを使ってインデックスを作成します。このインデックスをChatGPTと連携させることで、外部データの内容に基づいた回答を生成できるようにします。
ChatGPTのAPIキーを取得する
まず、ChatGPTのAPIキーを取得する手順を説明します。
動画の1:05から
今回使用するファイル
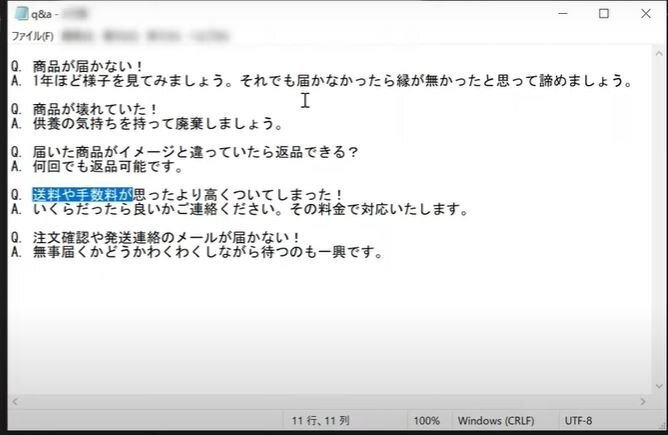
今回使用するファイルに関しては動画の4:37からご覧ください。
実装方法
必要なライブラリのインストール
まず、以下のライブラリをインストールする必要があります。
pip install streamlit llama-indexllama-indexの基本
import streamlit as st
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# pip install streamlit llama-index
st.set_page_config(page_title='llamaindex')
st.title('llamaindex')
############ 基礎
st.markdown('### llamaindex 基礎')
# ローカルのテキストファイルを読み込む
documents = SimpleDirectoryReader('data').load_data() # フォルダを指定
_='''
VectorStoreIndex
・文章をベクトル表現に変換
・各Nodeに対応する埋め込みベクトルと共に順序付けせずに保持
・埋め込みベクトルを使用してNodeを抽出し、それぞれの出力を合成
※_=で画面表示を防ぐ。streamlitのmagic対策。
'''
index = VectorStoreIndex.from_documents(documents)
# 質問に対して、indexを使用して回答を生成
query_engine = index.as_query_engine()
message_text = '商品が届きません。'
response = query_engine.query(message_text)
with st.expander('response', expanded=False):
st.write(response)
message_user = st.chat_message('user')
message_user.write(message_text)
message = st.chat_message('assistant')
message.write(response.response)上記のコードでは、まずSimpleDirectoryReaderを使って、ローカルのdataフォルダ内のテキストファイルを読み込み、documents変数に格納します。
次に、VectorStoreIndex.from_documents()を使って、documentsをベクトル表現に変換し、indexを作成します。このindexをas_query_engine()を使ってクエリエンジンに変換し、query_engine変数に格納します。
そして、st.text_input()でユーザーからの質問を受け付け、message_text変数に格納します。
ユーザーからの質問が入力されたら、query_engine.query()を使って、indexに基づいた回答を生成し、response変数に格納します。
最後に、st.chat_message()を使って、ユーザーとChatGPTのチャット画面を表示します。ユーザーからの質問は「user」として表示され、ChatGPTからの回答は「assistant」として表示されます。
index保存/読み込み
毎回、index化すると時間とコストがかかるため保存、読み込み機能を実装します。
import streamlit as st
from llama_index import VectorStoreIndex, SimpleDirectoryReader
import os.path
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
# pip install streamlit llama-index
st.set_page_config(page_title='llamaindex')
st.title('llamaindex')
st.markdown('### llamaindex index保存/読み込み')
# storageフォルダの存在の確認
if not os.path.exists("./storage"):
# ローカルのテキストファイルを読み込む
documents = SimpleDirectoryReader('data').load_data() # フォルダを指定
_='''
VectorStoreIndex
・文章をベクトル表現に変換
・各Nodeに対応する埋め込みベクトルと共に順序付けせずに保持
・埋め込みベクトルを使用してNodeを抽出し、それぞれの出力を合成
※_=で画面表示を防ぐ。streamlitのmagic対策。
'''
index = VectorStoreIndex.from_documents(documents)
# "./storage"に保存
index.storage_context.persist()
else:
# 保存したデータの読み込み
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# indexの読み込み
index = load_index_from_storage(storage_context)
# 質問に対して、indexを使用して回答を生成
query_engine = index.as_query_engine()
message_text = '商品が故障していました。'
response = query_engine.query(message_text)
with st.expander('response', expanded=False):
st.write(response)
message_user = st.chat_message('user')
message_user.write(message_text)
message = st.chat_message('assistant')
message.write(response.response)上記のコードでは、indexの保存と読み込みを行う部分も含まれています。
if not os.path.exists("./storage")という条件分岐で、storageフォルダが存在しない場合は、SimpleDirectoryReaderでテキストファイルを読み込み、VectorStoreIndexを作成し、index.storage_context.persist()を使ってstorageフォルダにindexを保存します。
storageフォルダが存在する場合は、StorageContext.from_defaults()を使ってstorageフォルダからindexを読み込みます。
OpenAIの設定
import streamlit as st
from llama_index.llms import OpenAI
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# pip install streamlit llama-index
st.set_page_config(page_title='llamaindex')
st.title('llamaindex')
st.markdown('### llamaindex LLMを使う')
response = OpenAI().complete("2018年のサッカーワールドカップのMVPは?")
st.write(response)ServiceContext, RetrieverQueryEngineの設定
詳細設定する。
import streamlit as st
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms import OpenAI
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
ServiceContext,
get_response_synthesizer
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.postprocessor import SimilarityPostprocessor
# pip install streamlit llama-index
st.set_page_config(page_title='llamaindex')
st.title('llamaindex')
st.markdown('### ServiceContext, RetrieverQueryEngineの設定')
llm = OpenAI(temperature=0.1, model="gpt-3.5-turbo")
service_context = ServiceContext.from_defaults(llm=llm) #llmやembed_modelなどの設定
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents, service_context=service_context
)
# retriever 設定 ベクトル空間モデルを使用して、類似性の高い文書を抽出
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2, # 上位何件を返すか
)
# response synthesizerのインスタンス化 検索結果を元に、自然言語で回答を生成するためのモデル
response_synthesizer = get_response_synthesizer()
# 類似性の高い文書から回答生成までの組み立て
query_engine = RetrieverQueryEngine(
retriever=retriever, # 類似性の高い文書を抽出
response_synthesizer=response_synthesizer, # 検索結果を元に、自然言語で回答を生成
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
# 抽出された文書を後処理 類似性が0.7以上の文書を抽出
)
# 質問の入力
question = st.chat_input('質問を入力してください')
if question:
response = query_engine.query(question)
with st.expander('response', expanded=False):
st.write(response)
message = st.chat_message("assistant")
message.write(response.response)
次に、VectorStoreIndex.from_documents()でindexを作成する際に、service_contextを指定することで、OpenAIを使ってindexを作成します。
また、index.as_retriever()を使って、類似性スコアの高い上位2件のノードを抽出するリトリーバーを作成し、retriever変数に格納します。
RetrieverQueryEngine()を使って、リトリーバーとレスポンスシンセサイザーを組み合わせてクエリエンジンを作成します。
まとめ
今回は、LlamaIndexを使ってChatGPTと外部データを連携させる方法を紹介しました。
LlamaIndexは、ChatGPTと外部データを連携させるための強力なツールです。ぜひ活用して、より高度なWEBアプリを作成してみてください。
よろしければサポートお願いします! いただいたサポートはクリエイターとしての活動費に使わせていただきます!