
クラスタ分析(K-means法)を実行する!

こんにちは!
ぷもんです。
以前、教師なし学習 クラスタ分析をやる!! データセットを読み込む編
というnoteでクラスタ分析をするデータの処理をしました。
今回は機械学習のクラスタ分析(K-means法)を実行するところまでやります。
以前、教師なし学習に必要のないカラムを排除するところまでやりました。
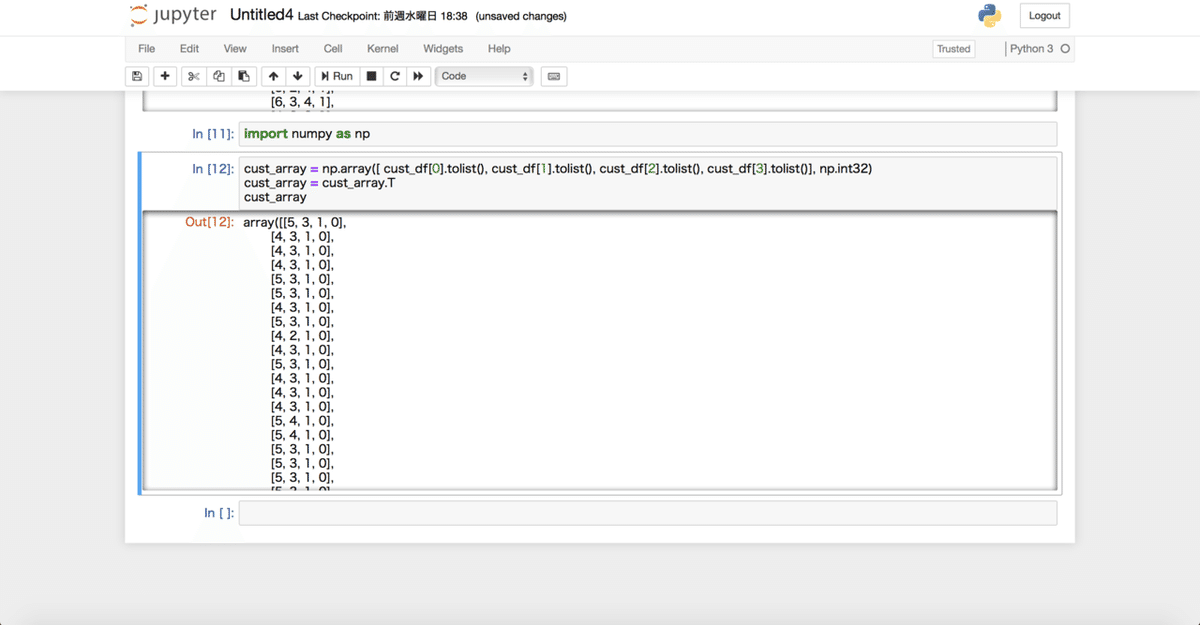
ここまでPandasのデータフレームでやっていたのですが
ここでNumpyに変換します。
そのためにNumpyをインポートします。
import numpy as np次のコードを実行することでNumpyに変換できます。
cust_array = np.array([ cust_df[0].tolist(), cust_df[1].tolist(), cust_df[2].tolist(), cust_df[3].tolist()], np.int32)
cust_array = cust_array.T
cust_arrayこんな感じになりました!
Numpyをインポートしていないと
次のようなエラーが出るので注意が必要です。

なんでPandasをNumpyに変えないといけないのか
正確なことはわからなかったのですが
Numpyは計算が早い
Pandasは扱えるデータが幅広い
という特徴があって、そこが関係しているのかなと思います。
もう少し勉強します...。
続いて、K-means法の機械学習を実行します。
そのために、scikit-learnのsklearn.cluster.KMeansクラスをインポートします。
from sklearn.cluster import KMeans実行します。
pred = KMeans(n_clusters=3).fit_predict(cust_array)
predこんなに短くていいのは
scikit-learnのsklearn.cluster.KMeansクラスを使っているためです。
短過ぎて「いけてる?』と不安になります。
他の方法もありそうだったので
どう違うのかどういうメリットがあるのか?
も今後、調べてみます。
結果はこんな感じになりました!

アヤメがどの種類に当たるのかクラスタリングした結果を示しています。
0がsetosa、1がversicolor、2がvirginicです。
ちなみに、scikit-learnのsklearn.cluster.KMeansクラスをインポートしていないとこうなります。

次のコードでどれがどのくらいあったかが出力されます。
cust_df[ 'cluster_id']=pred
cust_df[ 'cluster_id'].value_counts()結果はこんな感じになりました。

これでクラスタ分析(K-means法)をすることができました。
scikit-learnのsklearn.cluster.KMeansクラスのおかげで簡単でしたが
もう少し知識を深掘りする必要がありそうです。
参考にした記事はこちらです!
最後まで読んでいただきありがとうございました。
ぷもんでした!
noteを日々投稿してます! もしいいなと思ってもらえたら サポートしてもらえるとありがたいです。 VRやパソコンの設備投資に使わせていただきます。 ご意見、質問等ありましたらコメントください。 #ぷもん でつぶやいてもらえると励みになります。 一緒に頑張りましょう!