
OBS入門者に捧ぐ ~音声フィルターの話~

配信に乗る音は綺麗な方が良いよね、という話
とはいえ、OBS慣れしていない人に音声のフィルターをかけろと言っても「はて?」となるのが必定。
なので、素人ながらDTMerであり、またリスナーでありながら配信もやる自分がリファレンス的に初心者向けに「とりあえずこんなもん」程度の簡単な解説をしてみようかと。
また、配信に載せる音の質に関しても触れられたらと思う。
上級者からすればツッコミどころは多いと思うけど、とりあえず自分はこれでやれているので間違っては無いはずと信じて。
OBSの音声デバイスに掛けるフィルターの種類

3バンドイコライザー
イコライザー(EQと略します)は音量バランスではなく、音の高さのバランスを取るフィルターです。
低音成分が多くてこもって聞こえる、高音成分が多くてキンキンうるさい、などを解決するもので、3バンドといえば調整出来る音域全体を3つに分けて(大体は高中低)いるという訳です。
人の声成分は大体MIDレンジ(中音域)に当たりますが低音が魅力のイケボさんや高音厨も真っ青の高音ボイスの方はこの限りではないです。
音楽で使う場合はもっと細かい(例えば12バンドEQなど)調整が出来るものもあったりします。
VST 2.xプラグイン
そもそもVSTプラグインというのは楽曲制作ソフト(DAW)向けの機能拡張のソフトウエアの規格で外部の機能を導入する際にこれを選びます。
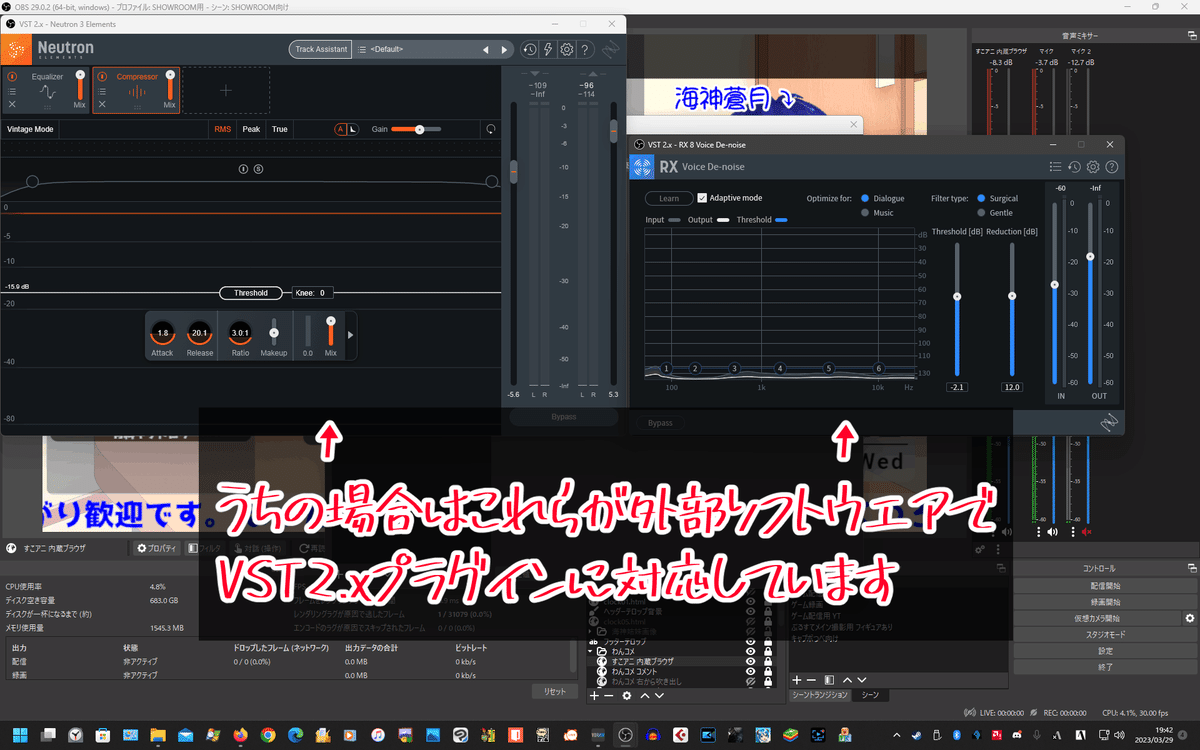
何を導入するかは人それぞれですので内容に関しては説明しませんが、うちの場合はiZotope社の「RX」というプラグインから「Voice De-noise」(ノイズゲート)と同社の「Neutron」というプラグインでコンプレッサーとイコライザーをかけていますので、OBS内蔵は使用していません。
有料のプラグインだと設定が楽だったり音質が良かったりと使う価値は大いにあります。
ちなみにiZotope社の「RX」(特にVoice De-noise)はオススメです。
この後出てくるノイズゲートの設定の煩わしさから解放されるので年に2回くらいあるセール(物にも依るけど80% OFFなんてのもあるぞ)をめがけて購入しておくと良いと思います。
ゲイン
単純に「入力側の音量」のことです。
普通はボリュームといって「出力側の音量」しか気にしないですが、フィルターを掛けるならば入力側の音量というのが大事になってくる場面があります。
いわゆる「S/N比」(Signal/Noise)というヤツが一番分かり易いのですが、それよりも出力ボリュームをいくら上げても音が小さいと言われるときはこのゲインを大きめに上げて出力ボリュームを絞ると良いと思います。
基本、配信の場合は聞く側が全体ボリュームを調整出来るものですが、小さい音を大きくするには限界がありますので「やや大きいかな?」くらいで載せた方が聴く側のボリューム調整の幅は広いように思います。
ただ、これを上げすぎてしまうと音割れにも繋がってしまうのでやり過ぎには注意ですし、他にも調整するといいフィルターがありますのでゲインだけでなんとかしようとしすぎないことが大事です。
コンプレッサー
「compressor」とは「圧縮機」の事で略称というか一般的には「コンプ」と呼ばれます。
そして今回圧縮するのはモチロン音(というかダイナミックレンジ)です。
このフィルターを使うと、一番小さい音と一番大きい音の差が少なくなります。
これの何が嬉しいかというと、まず急に大きな声を出しても音量を絞って音割れするほど大きな出力になりにくくなりますし、小さい声の時は逆に音量を上げて出力が小さくなりすぎなくなります。
車や飛行機の爆音のそばで話すと声がかき消されてしまうのですが、コンプレッサーを掛けてその音量差を小さくすることで本来埋もれてしまいがちな声を聞き取りやすくします。
いわゆる音の「ダイナミックレンジ」というヤツが関わってきますので詳しく知りたい方はこのワードを検索してみると良いかもしれません。
ノイズゲート
簡単に言うと、「設定した音量の値(しきい値・スレッショルド・thresholdなどと表記されます)」以下の音を無かったことにするフィルターです。
PCのファンの音や小さなノイズ程度なら綺麗になりますがマイクのゲインが小さいと小声での話し声や語尾まで切り飛ばしかねないので、突き詰めての調整はなかなか大変です。
ノイズ抑制
読んで字の如しです。
なんかすごい技術でノイズをなくしてくれる魔法のようなフィルターですw
正直内部で何をやってるかはよく分かりません。
女子は「RNNoise(高負荷)」に設定すると悲鳴が綺麗さっぱりなくなったりする現象が起きやすいみたいなので「Speex(低負荷・低品質)」をえらんでノイズゲートやイコライザーなどの併用が良いのかもしれません。
リミッター
音の大きさの限界値を設定します。
コンプと違うのはダイナミックレンジは触らずにただデカい音を切り飛ばす単純さでしょうか。
コンプを上手くかけるならあまりお世話になることのないフィルターです。
用語解説のコーナー
フィルターを設定する際になんだかよくわからん項目があって投げ出したくなる気持ちを少しでも和らげることを目的としています。
コンプレッサー編
・比率:左側の数字が大きくなればなるほど圧縮率が高まる。つまり大きい音と小さい音の差が小さくなるということ。
・しきい値:圧縮が開始されるレベルのこと。 しきい値より上の音声は、設定した比率により圧縮される。
・アタックタイム:音量がしきい値を超えてからどのくらいの緩やかさで圧縮が設定比率まで圧縮されるかの時間。0にすると即時圧縮になるけど、急な変化になって聞いてる人の違和感になりやすい。
・リリースタイム:音量がしきい値を下回ってからどのくらいの緩やかさで圧縮を解除するかの時間。
ノイズゲート編
・閉鎖しきい値:この音量を下回ると音声の入力を停止する。ゲートが閉じる音量上限。
・解放しきい値:この音量を上回ると音声の入力を開始する。ゲートが開く音量下限。
・動作開始時間:閉鎖しきい値を下回ってから実際に動き出すまでのアタックタイム。
・保持時間:動作のレスポンスの速さ。一旦待ってみる時間。
・解除時間:解放しきい値を超えてからのリリースタイム。
OBSの音声設定(主にSHOWROOM配信向け)
(2023.03.30追記記事です)
さてさて、ちょっとした余談のコーナーです。
フィルターを使えばノイズがなくなったり音が聴きやすくなることはわかった。
でも、結局低音質な状態では折角の美声も有り難みが減ってしまう。
ということで、自分がやっているちょっとした工夫。
効果があるかどうかは都市伝説レベルだけどね。
マイクの入力音声をモノラルで扱う
コレなんですが「逆に音質が下がるのでは?」と思われそうですが、実はそうでもないです。
高いステレオマイク(ASMRマイク含む)ならばステレオでの送信が意味をなしますが、カラオケマイクのような物とか うちのようにピンマイクはそもそもにして「モノラル出力」なので、OBS上の取り扱いもモノラルでいいです。
また、音声ビットレートに関しても人のおしゃべり程度であれば160kbpsあれば潤沢です。
楽曲でも160kbpsあれば音の劣化は感じにくいです。
しかもモノラルに設定することで160kbpsというデータ密度をフルに使えます。
どういうことかというと、ステレオは左右2チャンネルで構成されている為、この160kbpsという数字を2つに分けて80kbps(右)+80kbps(左)にして通します。
なのでこの2つのチャンネルに同じ情報(モノラルマイクだと左右どっちも音声の内容は同じになる)を送る訳で、となるとモノラルだと160kbpsという解像度で音声を扱えますがステレオだと実質80kbpsの解像度の音声を重複して使うことになります。
もし仮にOBSの音声ビットレート(解像度)を160kbpsに設定した時にステレオでも160kbps+160kbpsのデータを扱うのであれば、今度は配信サーバーに送るデータが大きくなる(倍になる)ということになります。
音声だけを見ているなら大したことが無いように思えるでしょうが(SHOWROOMの配信サーバーの場合)配信ビットレート、つまり動画部分と音声部分を全部合わせたデータ量が1500kbpsになるので音声データが増えた分は画面のデータを圧迫することになります。
まぁ、YouTubeだと配信ビットレートを9000kbps(フルHD画質での推奨値)に上げられますし、なんなら自分はYouTube向けには15000kbpsを設定していますのでこんなことは考えなくても良いのですけどね。
そして、もうひとつ。
これまたSHOWROOMに偏った話なんですが、基本SHOWROOMのリスナーはスマホやタブレットなどのモバイル端末での視聴をしていることが多いです。
そういった端末の音声出力に定位(音が左右のどの辺から発せられたかということ)なんてほとんど求められませんし、仮にPCで見ていたって人のおしゃべりが右から来ようが左から来ようがどうでもいいです。
そんなことに気を遣うくらいならモノラルでもはっきり耳心地のいい音で聞こえた方がいいに決まっています。
まぁ、ASMRのように距離感や定位が重要なものを除きますけどSHOWROOMじゃあまりやらないでしょうし。
さすがに楽曲を聴かせたい場合などはどうしてもステレオでの出力をするんですが、アレはきちんと左右で違う音声信号を扱っていて意味がちゃんとあるので今回の話は適用されません。
まぁ、BGM程度なら、別にその曲を全面にフィーチャーしたい訳でもないでしょうからモノラルでも良いんじゃね?とは思います。その辺は手間と好みで決めていいでしょうね。

PCのサンプリングレートを上げる
さてサンプリングレートとは?という話になると思いますのでざっくり解説。ちょっと難しい話しもするかもなのでわからなければわかった気になって貰っていいです。

音声というのは音の波で基本アナログなものです。
しかしPCを始めとしたデジタル機器がそのアナログのものを扱おうとするとどうしてもデジタル化(数値化)という工程が欠かせません。
しかしアナログとデジタルの大きな違いは連続的に滑らか(リニア)な変化をするかどうかです。
サンプリングレートとはデジタルでは完全再現出来ないそのリニアな変化をどれだけ精細に数値化するか、という指標です。
基本的に数値化する際にどれだけの桁数の数字を使うかというのが16bitとか24bitとかです。(bitは2進数における桁数です)
16bitだと0から65,535までの範囲で(ここでは)音の大きさを区分けすることが出来ますし、24bitだと0から16,777,215まで、32bitだと0から4,294,967,295まで区分けして認識することが出来ます。
音量変化の認識の細かさがコレに出ます。
当たり前ですが桁が増えればデータ量もデカくなり、その分処理の負荷も大きくなります。(まぁ、今のPCは64bitデータを扱うように出来てるのでアレなんですけど)
そしてもう1つは48000Hz(48kHz)とか44100Hz(44.1kHz)とか言う方ですね。
これはサンプリング周波数といってどれくらいの頻度で音声の数値化をするかということです。
Hz(ヘルツ)はそもそも1秒間に何回繰り返すか的な指標なので48kHzだと1秒間に48000回も音の波を数値化(サンプリング)していることになります。びっくりだわ。
ハイレゾ音源とかだとこれが96kHz(96000Hz)とかになるのでそりゃ綺麗に聞こえるだろという話ですが、前述の扱うbit(桁)数や次に話すビットレートにも大きく左右されるのでこれを闇雲に上げればいい音かと言われるとそう言う訳でもないんです。
ついでなんでビットレートの話
そしてビットレート。
これは特に音声圧縮が絡む音声データに関わります。
ちなみにCD音質(16bit/44.1kHz)の無圧縮音声データ(windowsだと .wavファイルが分かり易い)だとビットレートが1411kbps、上の自分ちのPCの設定(24bit/48kHz)だと2304kbpsになるそうですが、「bps」は「bit per second」の略で1秒間に○ビットという値です。
1411kbpsで3分(180秒)だと作成されるデータ量は253980kbit、PCではByte(バイト)が使われますので1/8(1Byte=8bit)して31747kByte(31.7MB)になる訳です。
これが2304kbpsだと約51.8MBになります。
今のインターネットは速いのでこれでも大丈夫そうですが、データの品質は落とさずにデータ量が小さくなれば、同じ記憶媒体により多くの情報が詰め込める訳で、そのためにデータ圧縮技術というものは昔からずっと開発され続けています。
例えばmp3(古いか?)を例に取ると最高音質は320kbpsです。
これで3分の音声を記録すると(内容によって変動はありますが)7.2MBになってしまいます。小さくなりましたね。
これでPCやサーバー、そしてネットトラフィックに負荷を掛けずに済みそうです。
ただ、基本的に圧縮にも2種類あります。
「可逆圧縮」と「非可逆圧縮」というヤツです。
可逆圧縮とは圧縮したものを伸張(解凍)した時に圧縮前のデータに寸分違わず戻せる圧縮のことを言います。ロスするデータが無いので別名「ロスレス圧縮」とも言います。
分かり易いところではzip圧縮なんかがコレに当たります。
アレを解凍したときにデータが変わってたら使い物になりませんよね。
ただ、音声の場合はもう1つの非可逆圧縮が主流です。
非可逆圧縮とは圧縮データを解凍したときに圧縮前のデータにならない(欠損が出る)圧縮のことを言います。
え?だめじゃん?と思ったそこの貴方、気持ちは分かりますがそれでも音の場合は困らないんです。
非圧縮の音声データには一部人間の耳では聞き分けられない音声データというモノがあります。
非可逆圧縮の「欠損」はそのあってもなくてもどうせ人間の耳には聞こえない音の部分をちぎって捨てているのです。
だから非可逆圧縮の方がデータ量が小さくて済みます。
そして「ビットレートが低い」というのは(ざっくり言えば)「ちぎって捨てているデータが多い」ということになるのです。
mp3の話をするなら128kbpsと160kbpsの間に1つの壁があってここを境にハイハット(ドラムのチキチキ言うアレ)の音が全然変わります。
なので自分はmp3圧縮をする際は最低でも160kbps以上、普段は320kbps圧縮をしています。
今や他にもaacだのmp4だのATRACだのいろんな音声圧縮技術があり、この話が丸々通用はしませんがこう言ったことが音声データに行われているという知識があるだけでもちょっと「わかる人」になれた気がしませんか?
最後に
書き終わり、追記を終えた今でさえ こう言った話の需要は正直解りません。
自分の覚え書きでもあります。
あと、読んでみて「それは違うぞ!」という指摘も歓迎です。
ビットレート周りの計算なんかもかなり細かいこと端折ってざっくりやっていますので「厳密ではない」ですが、一般人向けだとこれでも難しい話なんです。
とはいえ、都度修正する気持ちはあります。
もしも誰かの、そして何かの役に立てたなら。
この記事が気に入ったらサポートをしてみませんか?