
LangChainを学ぶ(2024年3月)

下記のコース(英語)でLangChainを学んでいく際の2024年3月時点の躓きポイントの突破メモです。ファイルをダウンロードもしくはコピペして、WindowsのWSL2でUbuntuを使って試しています。
当方、カウンセリングAIを作っているわけですが、LangChainめっちゃ使えそう。
コース1
コース2
【注意】今は LangChain Expression Language (LCEL) という書き方が標準なようです。この講座で使われているものとは違うかも。
コース1
L1-Model_prompt_parser
ファイルダウンロードできない問題
File→Download as→Notebook (.ipynb) でダウンロードできるはずなんですが、できません。(L4以降はできます)
コピペしました。ウェブ上のNotebookのセルをクリックした状態でCtrl+Aで、全選択できます。ローカルのNotebookに貼り付けると、1つのセルにまとまってしまいますが、半写経的に1セル分ずつコピペして実行してました。
ちなみに、おそらく古いファイルだと思いますが、こちらにもあります。
.env の作成
'OPENAI_API_KEY' は、私の環境では、.env という名前のテキストファイルを作って、入れました。
.env の中身:
'OPENAI_API_KEY' = 'sk-faldkjgaoijeafXXX'
# 右側にはご自身で取得したキーを入れてください。openai.ChatCompletion.create() の変更
openai.chat.completions.create() に変わってます。
L3-Chains
Data_1_3.csv がない
たぶんないと思います。自分で作りました。2列しかないので、それぞれCSVに貼り付けてご利用ください。
1列目:
Product
Queen Size Sheet Set
Waterproof Phone Pouch
Luxury Air Mattress
Pillows Insert
Milk Frother Handheld\n
L'Or Espresso Café \n
Hervidor de Agua Eléctrico2列目:
Review
I ordered a king size set. My only criticism would be that I wish seller would offer the king size set with 4 pillowcases. I separately ordered a two pack of pillowcases so I could have a total of four. When I saw the two packages, it looked like the color did not exactly match. Customer service was excellent about sending me two more pillowcases so I would have four that matched. Excellent! For the cost of these sheets, I am satisfied with the characteristics and coolness of the sheets.
I loved the waterproof sac, although the opening was made of a hard plastic. I don’t know if that would break easily. But I couldn’t turn my phone on, once it was in the pouch.
This mattress had a small hole in the top of it (took forever to find where it was), and the patches that they provide did not work, maybe because it's the top of the mattress where it's kind of like fabric and a patch won't stick. Maybe I got unlucky with a defective mattress, but where's quality assurance for this company? That flat out should not happen. Emphasis on flat. Cause that's what the mattress was. Seriously horrible experience, ruined my friend's stay with me. Then they make you ship it back instead of just providing a refund, which is also super annoying to pack up an air mattress and take it to the UPS store. This company is the worst, and this mattress is the worst.
This is the best throw pillow fillers on Amazon. I’ve tried several others, and they’re all cheap and flat no matter how much fluffing you do. Once you toss these in the dryer after you remove them from the vacuum sealed shipping material, they fluff up great
\xa0I loved this product. But they only seem to last a few months. The company was great replacing the first one (the frother falls out of the handle and can't be fixed). The after 4 months my second one did the same. I only use the frother for coffee once a day. It's not overuse or abuse. I'm very disappointed and will look for another. As I understand they will only replace once. Anyway, if you have one good luck.
Je trouve le goût médiocre. La mousse ne tient pas, c'est bizarre. J'achète les mêmes dans le commerce et le goût est bien meilleur...\nVieux lot ou contrefaçon !?
Está lu bonita calienta muy rápido, es muy funcional, solo falta ver cuánto dura, solo llevo 3 días en funcionamiento.L4-QnA
ValidationError
これは結構時間取られました。ここで出ます↓
llm_replacement_model = OpenAI(temperature=0,
model='gpt-3.5-turbo-instruct')
response = index.query(query,
llm = llm_replacement_model)エラーの内容を全部載せるとこんな感じ
ValidationError Traceback (most recent call last)
Cell In[44], line 4
1 llm_replacement_model = OpenAI(temperature=0,
2 model='gpt-3.5-turbo-instruct')
----> 4 response = index.query(query,
5 llm = llm_replacement_model)
File ~/.local/lib/python3.10/site-packages/langchain/indexes/vectorstore.py:46, in VectorStoreIndexWrapper.query(self, question, llm, retriever_kwargs, **kwargs)
42 retriever_kwargs = retriever_kwargs or {}
43 chain = RetrievalQA.from_chain_type(
44 llm, retriever=self.vectorstore.as_retriever(**retriever_kwargs), **kwargs
45 )
---> 46 return chain.run(question)
File ~/.local/lib/python3.10/site-packages/langchain_core/_api/deprecation.py:145, in deprecated.<locals>.deprecate.<locals>.warning_emitting_wrapper(*args, **kwargs)
143 warned = True
144 emit_warning()
--> 145 return wrapped(*args, **kwargs)
File ~/.local/lib/python3.10/site-packages/langchain/chains/base.py:545, in Chain.run(self, callbacks, tags, metadata, *args, **kwargs)
543 if len(args) != 1:
544 raise ValueError("`run` supports only one positional argument.")
--> 545 return self(args[0], callbacks=callbacks, tags=tags, metadata=metadata)[
546 _output_key
...
Field required [type=missing, input_value={'embedding': [0.00328532... -0.021133498095708216]}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.6/v/missing
metadata
Field required [type=missing, input_value={'embedding': [0.00328532... -0.021133498095708216]}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.6/v/missingGoogle検索
langchain VectorstoreIndexCreator query
でました!
結局、これでいけます。
%pip install chromadb# インデックスの作成に用いるクラスをインポート
from langchain.indexes import VectorstoreIndexCreator
from langchain.indexes.vectorstore import VectorStoreIndexWrapper
# ベクターストアの作成
index: VectorStoreIndexWrapper = VectorstoreIndexCreator().from_loaders([loader])
query = "Please list all your shirts with sun protection \
in a table in markdown and summarize each one."CSVとインデックス後の中身を確認したい
CSVの中身の確認:
# import pandas as pd
# # CSVファイルのパス
# file_path = 'OutdoorClothingCatalog_1000.csv'
# # CSVファイルの読み込み
# df_pre = pd.read_csv(file_path)
# # 先頭の数行を表示
# print("処理前のCSVファイルの内容:")
# print(df_pre.head())インデックス後の中身の確認:
from langchain.document_loaders import CSVLoader
from langchain.vectorstores import DocArrayInMemorySearch
from langchain.indexes import VectorstoreIndexCreator
# CSVファイルからデータを読み込む
loader = CSVLoader(file_path=file_path)
data = loader.load()
# 文書のインデックスを作成
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
# 処理後のデータの例を表示(ここでは原始データの一部として)
print("処理後のデータの例(原始データからの抽出):")
print(data[:1]) # 最初の1つの文書を表示docs = db.similarity_search(query) でエラー
ValidationError Traceback (most recent call last)
Cell In[29], line 1
----> 1 docs = db.similarity_search(query)
File ~/.local/lib/python3.10/site-packages/langchain_community/vectorstores/docarray/base.py:127, in DocArrayIndex.similarity_search(self, query, k, **kwargs)
115 def similarity_search(
116 self, query: str, k: int = 4, **kwargs: Any
117 ) -> List[Document]:
118 """Return docs most similar to query.
119
120 Args:
(...)
125 List of Documents most similar to the query.
126 """
--> 127 results = self.similarity_search_with_score(query, k=k, **kwargs)
128 return [doc for doc, _ in results]
File ~/.local/lib/python3.10/site-packages/langchain_community/vectorstores/docarray/base.py:106, in DocArrayIndex.similarity_search_with_score(self, query, k, **kwargs)
94 """Return docs most similar to query.
95
96 Args:
(...)
103 Lower score represents more similarity.
104 """
...
Field required [type=missing, input_value={'embedding': [-0.0222515... -0.022251551228798728]}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.6/v/missing
metadata
Field required [type=missing, input_value={'embedding': [-0.0222515... -0.022251551228798728]}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.6/v/missing前回と同じ感じだけどどう対処していいかわからん。
困ったのでGoogle検索
LangChain embeddings db similarity_search()
見つかる。はじめからこのサイトに沿ってやればいいのではないかと思いつつ…
これでいけました!たぶん…
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = CSVLoader(file_path=file).load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())response = llm.call_as_llm(f"{qdocs} Question: Please list all your \ shirts with sun protection in a table in markdown and summarize each one.") でエラー
RateLimitError: Error code: 429 - {'error': {'message': 'Request too large for gpt-3.5-turbo-0301 in organization org-AnB6ujfUaBxOgLnDuXDDacK5 on tokens per min (TPM): Limit 80000, Requested 192003. The input or output tokens must be reduced in order to run successfully. Visit https://platform.openai.com/account/rate-limits to learn more.', 'type': 'tokens', 'param': None, 'code': 'rate_limit_exceeded'}}
とりあえずサイトを確認
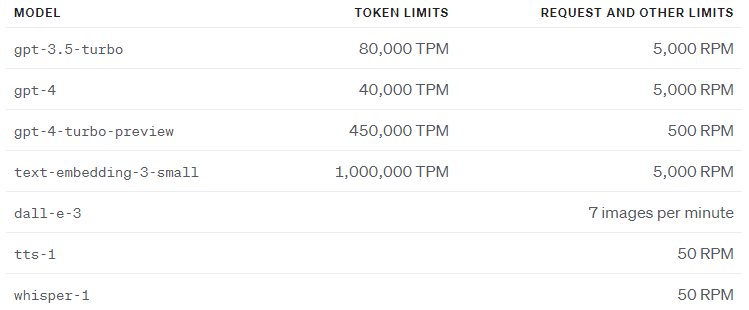
いや、リミットがあるのはわかっとんじゃい!
これでいけました。
# 最初の20の文書だけを使用
qdocs = "".join([docs[i].page_content for i in range(min(20, len(docs)))])
response = llm.call_as_llm(f"{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.")ChatGPT 4 に色々聞いてみた
L4コードの解説
このコードは、以下の二つの主要な操作を行っています:
1. **文書の連結**:
```python
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
```
この行は、`docs`(おそらく前のステップで準備された文書のリスト)から各文書の内容(`page_content`)を取得し、それらを一つの大きな文字列に連結しています。この操作により、全ての文書の内容が一つの変数 `qdocs` に格納されます。これは、複数の文書にまたがる情報を一度に処理するため、または全文書を一括で言語モデルに渡すために行われます。
2. **言語モデルの呼び出し**:
```python
response = llm.call_as_llm(f"{qdocs} Question: Please list all your \
shirts with sun protection in a table in markdown and summarize each one.")
```
この行では、言語モデル(`llm`としてインスタンス化されている)を使用して、先に連結した文書の内容(`qdocs`)に基づく特定のタスクを実行しています。この場合、タスクは「全ての日焼け防止シャツをマークダウン形式の表でリストし、それぞれを要約する」という質問への回答を求めるものです。`call_as_llm`メソッドは、提供されたテキスト(連結された文書と質問)を入力として、言語モデルによる回答を生成します。
要するに、このコードは複数の文書から情報を集め、それを一つのテキストにまとめた後、そのテキストを用いて特定の質問に答えるよう言語モデルに指示しています。この方法で、大量のテキストデータから特定の情報を抽出し、要約するプロセスを自動化しています。
後半部分も
このコードは、自然言語処理や情報検索タスクに関連するいくつかの操作を行っています。それぞれの部分を詳しく説明します:
1. **RetrievalQAインスタンスの作成**:
```python
qa_stuff = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
verbose=True
)
```
この部分は、`RetrievalQA`(検索ベースの質問応答システム)のインスタンスを作成しています。`RetrievalQA.from_chain_type`メソッドは、特定の設定(`llm`、`chain_type`、`retriever`)を使って、質問応答システムを初期化しています。ここで、`llm`は言語モデル、`retriever`は情報検索システムを指し、`chain_type`は特定のタイプの質問応答プロセスを定義します(ここでは具体的な動作は示されていませんが、特定の種類のタスクやデータを処理するための設定名を示している可能性があります)。`verbose=True`は、実行時に追加情報を表示するように指示しています。
2. **質問応答システムを使ったクエリの実行**:
```python
response = qa_stuff.run(query)
```
これは、前に作成した`qa_stuff`(RetrievalQAインスタンス)を使用して、与えられた`query`(質問やクエリ)に対する回答を生成しています。`run`メソッドは、内部的に文書検索と言語モデルを使用して最適な回答を見つけ出します。
3. **ベクトル検索のクエリ実行**:
```python
response = index.query(query, llm=llm)
```
この行では、既に作成された`index`(ベクトル検索インデックス)を使用して、与えられた`query`で検索を実行し、関連する情報またはドキュメントを取得しています。`llm`はこのコンテキストでどのように使用されるかは示されていませんが、おそらく検索結果に基づいて何らかの追加処理を行うために使用される言語モデルを指している可能性があります。
4. **ベクトルストアインデックスの作成**:
```python
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=embeddings,
).from_loaders([loader])
```
ここでは、`VectorstoreIndexCreator`を使用して、ドキュメントのベクトル表現を格納するインデックスを作成しています。`vectorstore_cls`は使用するベクトルストアのクラス(この場合はメモリ内検索をサポートする`DocArrayInMemorySearch`)、`embedding`はドキュメントをベクトルに変換するための埋め込みモデルを指しています。`from_loaders`メソッドは、一つ以上のデータローダー(ここでは`loader`)からデータを読み込んで、インデックスを作成します。これにより、クエリに対する検索や検索ベースのタスクを効率的に実行するための準備が整います。
Indexの使い方
`index` は、ベクトル検索インデックスとして機能します。これは、特に大量のテキストデータやその他の形式のデータに対して、高速な検索と類似性検索を可能にするために使われます。以下は、`index` を使用する方法に関する一般的な例です:1. **類似文書の検索**: 文書やテキストフラグメントが与えられたとき、その文書に類似した内容をデータベースから検索するために `index` を使用できます。これは、ユーザーが特定のトピックに関連する情報を求めている場合や、文書クラスタリング、重複検出などに特に有用です。2. **意味的検索**: ユーザーからの自然言語のクエリに基づいて、最も関連性が高い文書や情報を見つけ出すために `index` を利用できます。これにより、単純なキーワードマッチングを超えた、コンテキストや意図を理解した検索が可能になります。3. **レコメンデーションシステム**: ユーザーの興味や過去の活動に基づいて関連するアイテムや文書を推薦する際に、`index` を活用できます。類似性スコアを計算することで、ユーザーに最も関連性の高いコンテンツを提供することができます。4. **データクラスタリングと分類**: データセット内の文書を、その類似性に基づいてグループ化したり、特定のカテゴリに自動的に分類したりする際に、`index` が役立ちます。これは、大規模なテキストコレクションを整理し、分析しやすくするために使われます。5. **FAQやカスタマーサポート自動化**: カスタマーサポートの文脈でよくある質問(FAQ)や顧客の問い合わせに対する回答を検索するために `index` を使用できます。ユーザーの質問に最も関連する既存の回答を迅速に見つけ出すことが可能になります。`index` の具体的な使用法は、その作成方法、格納されているデータ、およびアプリケーションの特定のニーズによって異なります。しかし、基本的には、あらゆる形式の類似性検索や情報検索タスクにおいて、高速かつ効率的な検索結果を提供するために活用されます。
IndexとRetrievalQAの違い
`RetrievalQA` インスタンスと `index` は使い方が異なるだけでなく、機能においてもいくつかの重要な違いがあります。それぞれの主な目的と機能を比較してみましょう:### RetrievalQA インスタンス- **主な目的**: `RetrievalQA` は、質問応答(QA)システムの一部として機能します。これは、特定の質問に対して最も関連性の高い回答を提供することを目的としています。これを実現するために、`RetrievalQA` は、大量のテキストデータから情報を検索し、その後、検索された情報を基に具体的な質問に対する回答を生成します。- **機能**: `RetrievalQA` は、一般に、テキストの検索と自然言語理解の両方を組み合わせたアプローチを採用しています。検索コンポーネントは関連する文書や情報を見つけ出し、次に言語モデル(例えば、LLM)を使用して、具体的な質問に対する直接的な回答を生成します。### Index- **主な目的**: `index` は、主に類似性検索やベクトル検索に使用されます。これは、特定のクエリや文書に最も類似しているアイテムを大規模なデータセットから迅速に見つけ出すことを目的としています。`index` の目的は、広範な情報から特定の情報を迅速に取得することですが、`RetrievalQA` とは異なり、質問に対する回答を直接生成することはありません。- **機能**: `index` は、テキストやその他のデータのベクトル表現に基づいて構築されます。このインデックスを使用して、類似性に基づく検索を行うことができますが、これは主にデータのマッチングや取得に関連しています。質問応答のプロセスには直接関与しませんが、質問応答システム内で情報検索コンポーネントとして利用することは可能です。要するに、`RetrievalQA` と `index` は、情報検索と処理において異なるアプローチを採用しています。`RetrievalQA` は質問応答のために設計されており、関連する情報を見つけ出し、それに基づいて具体的な質問に答えます。一方で、`index` は一般的な情報検索や類似性検索のために設計されており、直接的な質問応答よりも、関連するデータや文書を迅速に見つけ出すことに特化しています。
IndexとRetrievalQAの使い分け
`RetrievalQA` システムと、ベクトル検索 `index` と LLM(Large Language Model)の組み合わせは、異なる状況やニーズに応じて選択されます。それぞれが最適な状況を以下に説明します:
### RetrievalQAを使う状況:
- **特定の質問に対する直接的な回答が必要な場合**: ユーザーからの具体的な質問に基づいて、正確で直接的な回答を提供する必要がある場合、RetrievalQAが適しています。このシステムは、関連する情報を検索し、その情報を基に質問に答える一連のプロセスを自動化します。
- **統合されたソリューションが必要な場合**: 情報検索と回答生成を一つのフローで処理したい場合、RetrievalQAが便利です。これにより、検索から回答までのプロセスがスムーズに連携し、開発者は複数のコンポーネントを個別に管理する必要がなくなります。
- **FAQや顧客サポート**: よくある質問に対する回答を自動化したい場合や、顧客サポートで迅速な対応が求められる環境では、RetrievalQAが効果的です。
### LLMとIndexを使う状況:
- **柔軟な情報検索が必要な場合**: 複数のデータソースから情報を検索したり、特定の要件に基づいて情報をフィルタリングしたりする必要がある場合、独立した `index` を使用することが有効です。これにより、検索条件をより細かく調整できます。
- **大規模なデータセットでの効率的な検索**: 大量の文書やデータセットを扱う場合、特に類似性に基づく高速な検索が必要な場合は、ベクトル検索 `index` が適しています。この後で、選択された情報を基にLLMを使用してさらに詳細な分析や回答の生成を行えます。
- **高度なカスタマイゼーションが必要な場合**: 検索プロセスや回答生成プロセスを細かく制御したい場合、LLMと `index` を別々に使用すると、それぞれのステップをカスタマイズしやすくなります。
総合的には、RetrievalQAは一連の質問応答タスクにおいて、より緊密に統合されたアプローチを提供しますが、LLMと `index` の組み合わせは、より高度なカスタマイゼーションと柔軟性を必要とする複雑なシナリオに適しています。適切なツールの選択は、プロジェクトの具体的な要件と目標に基づいて行うべきです。
L5-Evaluation
qa.run(examples[0]["query"])で、エラー
qaは…
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs = {
"document_separator": "<<<<>>>>>"
}
)indexが入ってんな。ここじゃね。
ということで、indexの定義をこれに変えて、一件落着。
# インデックスの作成に用いるクラスをインポート
from langchain.indexes import VectorstoreIndexCreator
from langchain.indexes.vectorstore import VectorStoreIndexWrapper
index: VectorStoreIndexWrapper = VectorstoreIndexCreator().from_loaders([loader])GPT-4の解説
ベクトル検索インデックスの作成: 読み込まれたデータを使って、DocArrayInMemorySearch クラスを使用し、インメモリのベクトルストアインデックスを作成しています。これは、情報検索タスクで使用されます。
言語モデルの設定: ChatOpenAI クラスを使用して、温度パラメーターが0.0に設定されたチャット型言語モデル(LLM)のインスタンスを作成しています。温度が0の場合、モデルの出力はより予測可能かつ一貫したものになります。
質問応答システムの設定: 読み込まれたデータと作成されたベクトルインデックスを使用して、RetrievalQA システムを初期化しています。ここでは、chain_type を "stuff" に設定し、検索にはインデックスのベクトルストアを使用し、追加の設定としてドキュメントセパレータを指定しています。
ハードコーディングされた例の設定: 特定の質問とそれに対する回答の例を設定しています。これらは、言語モデルのトレーニングやテストに使用される可能性があります。
新しい例の生成: QAGenerateChain を使用して、読み込まれたデータから新しい質問応答ペアを生成しています。これは、言語モデルに基づいていて、データの初めの5項目から新しい例を作成します。
例の組み合わせ: ハードコーディングされた例と生成された新しい例を組み合わせています。これにより、より多くの質問応答ペアをテストまたはトレーニングセットとして使用できるようになります。
質問応答の実行: 最後に、合成された質問応答ペアの最初の質問を使って RetrievalQA システムを実行し、適切な回答を得ています。
全体として、このコードはデータを読み込み、処理し、質問応答ペアを生成し、これらのペアを使って質問応答システムをテストする一連のプロセスを実装しています。
Manual Evaluationの解説
質問の入力: 最初に、ユーザーの質問が RetrievalQA システムに入力されます。この例では、質問は "Do the Cozy Comfort Pullover Set have side pockets?"(コージーコンフォートプルオーバーセットにはサイドポケットがありますか?)です。
ドキュメント検索チェーンの開始: RetrievalQA は、関連するドキュメントを検索するために、StuffDocumentsChain(文書検索チェーン)を開始します。これは、適切な情報を持つ文書をデータベースから見つけ出すためのプロセスです。
言語モデルチェーンの開始: 次に、選択された文書(または文書の一部)が LLMChain に渡されます。このチェーンは、具体的な質問に対する回答を生成するために言語モデル(ここでは ChatOpenAI)を使用します。質問と関連する文書のコンテキストがモデルに提供され、それに基づいて適切な回答が生成されます。
言語モデルの実行: 言語モデルは、提供されたコンテキストと質問に基づいて回答を生成します。この例では、"The Cozy Comfort Pullover Set, Stripe has side pockets."(コージーコンフォートプルオーバーセット、ストライプにはサイドポケットがあります。)という回答が生成されました。
チェーンの終了: 各チェーン(LLMChain, StuffDocumentsChain)と最終的な RetrievalQA チェーンが終了し、結果が出力されます。最終的な出力は、質問に対する回答です。
LLM assisted evaluation
predictions = qa.apply(examples)でエラー
ValueError Traceback (most recent call last)
Cell In[73], line 1
----> 1 predictions = qa.apply(examples)
File ~/.local/lib/python3.10/site-packages/langchain_core/_api/deprecation.py:145, in deprecated.<locals>.deprecate.<locals>.warning_emitting_wrapper(*args, **kwargs)
143 warned = True
144 emit_warning()
--> 145 return wrapped(*args, **kwargs)
File ~/.local/lib/python3.10/site-packages/langchain/chains/base.py:708, in Chain.apply(self, input_list, callbacks)
703 @deprecated("0.1.0", alternative="batch", removal="0.2.0")
704 def apply(
705 self, input_list: List[Dict[str, Any]], callbacks: Callbacks = None
706 ) -> List[Dict[str, str]]:
707 """Call the chain on all inputs in the list."""
--> 708 return [self(inputs, callbacks=callbacks) for inputs in input_list]
File ~/.local/lib/python3.10/site-packages/langchain/chains/base.py:708, in <listcomp>(.0)
703 @deprecated("0.1.0", alternative="batch", removal="0.2.0")
704 def apply(
705 self, input_list: List[Dict[str, Any]], callbacks: Callbacks = None
706 ) -> List[Dict[str, str]]:
707 """Call the chain on all inputs in the list."""
--> 708 return [self(inputs, callbacks=callbacks) for inputs in input_list]
...
277 missing_keys = set(self.input_keys).difference(inputs)
278 if missing_keys:
--> 279 raise ValueError(f"Missing some input keys: {missing_keys}")
ValueError: Missing some input keys: {'query'}どうやら、ここがうまくいってないらしい。
examples += new_examples
examples
[{'query': 'Do the Cozy Comfort Pullover Set have side pockets?',
'answer': 'Yes'},
{'query': 'What collection is the Ultra-Lofty 850 Stretch Down Hooded Jacket from?',
'answer': 'The DownTek collection'},
{'qa_pairs': {'query': "What is the weight per pair of the Women's Campside Oxfords?",
'answer': "The approximate weight per pair of the Women's Campside Oxfords is 1 lb. 1 oz."}},
{'qa_pairs': {'query': 'What is the material used to construct the Recycled Waterhog dog mat?',
'answer': 'The Recycled Waterhog dog mat is constructed from 24 oz. polyester fabric made from 94% recycled materials, with a rubber backing.'}},
{'qa_pairs': {'query': "What are the features of the Infant and Toddler Girls' Coastal Chill Swimsuit, Two-Piece?",
'answer': "The swimsuit features bright colors, ruffles, and exclusive whimsical prints. The four-way-stretch and chlorine-resistant fabric helps the swimsuit keep its shape and resist snags. The swimsuit has a UPF 50+ rated fabric that provides the highest rated sun protection possible, blocking 98% of the sun's harmful rays. The crossover no-slip straps and fully lined bottom ensure a secure fit and maximum coverage. The swimsuit can be machine washed and line dried for best results."}},
{'qa_pairs': {'query': 'What is the percentage of recycled nylon in the body of the Refresh Swimwear V-Neck Tankini Contrasts?',
'answer': 'The body of the Refresh Swimwear V-Neck Tankini Contrasts is made of 82% recycled nylon.'}},
{'qa_pairs': {'query': "What is the main feature of the EcoFlex 3L Storm Pants' TEK O2 technology?",
'answer': "The main feature of the EcoFlex 3L Storm Pants' TEK O2 technology is its exceptional breathability, which is the most breathable the company has ever tested."}}]と、いうことで修正。
# 新しい例から 'query' と 'answer' のペアを抽出し、元の examples に追加する
for item in new_examples:
# item が 'qa_pairs' キーを持っていることを確認
if 'qa_pairs' in item:
# 'qa_pairs' キーから 'query' と 'answer' を取り出す
extracted_example = {
"query": item['qa_pairs']['query'],
"answer": item['qa_pairs']['answer']
}
# 抽出した例を元の examples リストに追加
examples.append(extracted_example)for i, eg in enumerate(examples):…でエラー
Example 0:
Question: Do the Cozy Comfort Pullover Set have side pockets?
Real Answer: Yes
Predicted Answer: Yes, the Cozy Comfort Pullover Set has side pockets.
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[95], line 6
4 print("Real Answer: " + predictions[i]['answer'])
5 print("Predicted Answer: " + predictions[i]['result'])
----> 6 print("Predicted Grade: " + graded_outputs[i]['text'])
7 print()
KeyError: 'text'シンプルにミスってる気がする。次のように修正。これでいいんだよね?
for i, eg in enumerate(examples):
print(f"Example {i}:")
print("Question: " + eg['query']) # 修正: examples から 'query' を取得
print("Real Answer: " + eg['answer']) # 修正: examples から 'answer' を取得
print("Predicted Answer: " + predictions[i]['result']) # 予測された答え
print("Predicted Grade: " + graded_outputs[i]['results']) # 修正: graded_outputs から 'results' を取得
print()LLM assisted evaluationの解説
このコードは、質問応答システム (`qa`) を使って、与えられた `examples` (質問とその正答のペアを含むリスト)に基づいた予測を行い、その後でこれらの予測の品質を評価する一連のプロセスを実行しています。ここでの各ステップを詳細に説明します:
1. **予測の生成**:
```python
predictions = qa.apply(examples)
```
ここでは、`examples` に含まれる各質問に対して `qa`(質問応答システム)を適用し、予測された回答のリスト `predictions` を生成しています。このリストには、各質問(`'query'`)、実際の回答(`'answer'`)、そして予測された回答(`'result'`)が含まれます。
2. **評価チェーンの設定**:
```python
from langchain.evaluation.qa import QAEvalChain
llm = ChatOpenAI(temperature=0)
eval_chain = QAEvalChain.from_llm(llm)
```
ここでは、品質評価用のチェーン `eval_chain` を設定しています。`QAEvalChain` は、言語モデル(`ChatOpenAI`)を使って、予測された回答と実際の回答を比較し、それぞれのペアに対して品質スコアまたはフィードバックを生成します。
3. **予測の評価**:
```python
graded_outputs = eval_chain.evaluate(examples, predictions)
```
`evaluate` メソッドを使用して、`examples`(正解を含む)と `predictions`(モデルの予測)を評価し、各質問応答ペアの品質に関する情報を含む `graded_outputs` リストを生成します。
4. **評価結果の出力**:
```python
for i, eg in enumerate(examples):
print(f"Example {i}:")
print("Question: " + predictions[i]['query'])
print("Real Answer: " + predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print("Predicted Grade: " + graded_outputs[i]['result'])
print()
```
最後に、各質問応答ペアについて、質問、実際の回答、予測された回答、およびその予測の評価(`'result'`)を出力しています。これにより、システムの性能をユーザーが確認できるようになっています。
`predictions` と `graded_outputs` は異なる種類のデータを保持しており、それぞれ異なる目的で使用されます。以下にそれぞれの説明を示します:
### predictions
`predictions` は、質問応答システム(ここでは `qa` として示されています)が提供した予測のリストです。具体的には、与えられた `examples`(質問のリスト)に対するシステムの回答です。各要素は通常、モデルが質問に対して生成した回答を含む辞書(`{'result': '予測された回答'}`)で構成されています。このリストは、モデルのパフォーマンスを評価するために、後のステップで実際の回答と比較されます。
### graded_outputs
`graded_outputs` は、`eval_chain.evaluate` 関数によって生成された評価の結果です。これは、各 `examples` の質問に対する `predictions` の予測回答を評価した結果を含んでいます。このリストの各要素は、通常、質問に対する予測回答がどの程度適切であったかに関する情報を含む辞書です(例えば、予測された回答の正確さや、特定のメトリクスに基づくスコアなど)。この情報は、モデルの回答品質を理解するために使用されます。
簡単に言うと、`predictions` はモデルが生成した生の予測回答を含み、`graded_outputs` はそれらの予測回答がどれだけ実際の回答と一致しているか(またはそれに対する品質がどれほどであるか)を示す評価結果を含んでいます。
LangChain evaluation の補足
L6-Agents
おそらくtoolsの読み込みでエラー
ValueError: '/home/user/.local/lib/python3.10/site-packages/langchain/agents/agent_toolkits' is not in the subpath of '/home/user/.local/lib/python3.10/site-packages/langchain_core' OR one path is relative and the other is absolute.
仮想環境を作ってPythonを入れなおしてもダメ…
検索したらあった!
とりあえずこれで一部クリア
pip install langchain_experimentalfrom langchain_experimental.agents.agent_toolkits import create_python_agentしかし、これが通らん!
from langchain.tools.python.tool import PythonREPLTool
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[18], line 4
2 from langchain.agents import load_tools, initialize_agent
3 from langchain.agents import AgentType
----> 4 from langchain.tools.python.tool import PythonREPLTool
ModuleNotFoundError: No module named 'langchain.tools.python.tool'なんだかlangchainのバージョンを上げろとか下げろとか言われている…
とりあえずアンインストールして、再インストールしたら普通にできた…
【ターミナルで】
pip uninstall langchain
pip install langchainわけわからん
import langchain
print(langchain.__version__)
## 0.1.11もしかしたらディレクトリ名に半角スペースがあったのが原因かも!ご注意を。
【変更】
LangChain for LLM
→ LangChain_for_LLM
Wikipediaがうまく動かず
result = agent(question)
---------------------------------------------------------------------------
SSLEOFError Traceback (most recent call last)
File ~/.local/lib/python3.10/site-packages/urllib3/connectionpool.py:467, in HTTPConnectionPool._make_request(self, conn, method, url, body, headers, retries, timeout, chunked, response_conn, preload_content, decode_content, enforce_content_length)
466 try:
--> 467 self._validate_conn(conn)
468 except (SocketTimeout, BaseSSLError) as e:
File ~/.local/lib/python3.10/site-packages/urllib3/connectionpool.py:1099, in HTTPSConnectionPool._validate_conn(self, conn)
1098 if conn.is_closed:
-> 1099 conn.connect()
1101 # TODO revise this, see https://github.com/urllib3/urllib3/issues/2791
File ~/.local/lib/python3.10/site-packages/urllib3/connection.py:653, in HTTPSConnection.connect(self)
651 server_hostname_rm_dot = server_hostname.rstrip(".")
--> 653 sock_and_verified = _ssl_wrap_socket_and_match_hostname(
654 sock=sock,
655 cert_reqs=self.cert_reqs,
656 ssl_version=self.ssl_version,
657 ssl_minimum_version=self.ssl_minimum_version,
658 ssl_maximum_version=self.ssl_maximum_version,
659 ca_certs=self.ca_certs,
660 ca_cert_dir=self.ca_cert_dir,
661 ca_cert_data=self.ca_cert_data,
662 cert_file=self.cert_file,
663 key_file=self.key_file,
...
--> 517 raise SSLError(e, request=request)
519 raise ConnectionError(e, request=request)
521 except ClosedPoolError as e:
SSLError: HTTPSConnectionPool(host='en.wikipedia.org', port=443): Max retries exceeded with url: /w/api.php?prop=extracts&explaintext=&exintro=&titles=Tom+M.+Mitchell&format=json&action=query (Caused by SSLError(SSLEOFError(8, '[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)'))なんと!職場のセキュリティが原因だった。自分のWifiにつないだら行けた。
これまでのところは、LangChain toolsを使って計算機とwikipediaのエージェントを作って、問題に応じてそれが使い分けられるということが示された。
その後、PythonREPLTool() を使って人名を並び替えて、その裏でLangChainがどう動いているか示したり、DateTime を使って、今日の日付を聞いたり。
コース2
補足資料はこちら
L1-document_loading
とりあえずGithubからすべてクローン
ファイルがいっぱいあるので、とりあえずGithubからプロジェクトごとクローンします。
【ターミナル】
git clone https://github.com/ksm26/LangChain-Chat-with-Your-Data.gitこれでクローンできるので、必要なディレクトリ(docs?)だけ、作業ディレクトリへコピー。
今回はPDFからテキスト抽出、YouTubeから音声をダウンロードしてテキスト変換、ウェブページからテキスト抽出。
YouTubeがうまくいかん
---------------------------------------------------------------------------
SSLEOFError Traceback (most recent call last)
File ~/.local/lib/python3.10/site-packages/urllib3/connectionpool.py:467, in HTTPConnectionPool._make_request(self, conn, method, url, body, headers, retries, timeout, chunked, response_conn, preload_content, decode_content, enforce_content_length)
466 try:
--> 467 self._validate_conn(conn)
468 except (SocketTimeout, BaseSSLError) as e:
File ~/.local/lib/python3.10/site-packages/urllib3/connectionpool.py:1099, in HTTPSConnectionPool._validate_conn(self, conn)
1098 if conn.is_closed:
-> 1099 conn.connect()
1101 # TODO revise this, see https://github.com/urllib3/urllib3/issues/2791
File ~/.local/lib/python3.10/site-packages/urllib3/connection.py:653, in HTTPSConnection.connect(self)
651 server_hostname_rm_dot = server_hostname.rstrip(".")
--> 653 sock_and_verified = _ssl_wrap_socket_and_match_hostname(
654 sock=sock,
655 cert_reqs=self.cert_reqs,
656 ssl_version=self.ssl_version,
657 ssl_minimum_version=self.ssl_minimum_version,
658 ssl_maximum_version=self.ssl_maximum_version,
659 ca_certs=self.ca_certs,
660 ca_cert_dir=self.ca_cert_dir,
661 ca_cert_data=self.ca_cert_data,
662 cert_file=self.cert_file,
663 key_file=self.key_file,
...
992 exc_info = sys.exc_info()
--> 993 raise DownloadError(message, exc_info)
994 self._download_retcode = 1
DownloadError: ERROR: [youtube] jGwO_UgTS7I: Unable to download API page: [SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007) (caused by SSLError('[SSL: UNEXPECTED_EOF_WHILE_READING] EOF occurred in violation of protocol (_ssl.c:1007)')); please report this issue on https://github.com/yt-dlp/yt-dlp/issues?q= , filling out the appropriate issue template. Confirm you are on the latest version using yt-dlp -Uyt-dlpの更新
【ターミナル】
yt-dlp -USSL証明書を確認
pip install --upgrade certifiターミナルでyoutubeのダウンロードはできる
【ターミナル】
yt-dlp -v jGwO_UgTS7IGoogle先生!
loader = GenericLoader(
YoutubeAudioLoader([url],save_dir),
OpenAIWhisperParser()
)
あった!
できん。
そもそもダウンロードができん。
最後は公式頼み!
とりあえずインストール
%pip install --upgrade --quiet librosa同じエラー
新たなエラー発見!
from langchain_community.document_loaders.blob_loaders.youtube_audio import (
YoutubeAudioLoader,
)
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import (
OpenAIWhisperParser,
OpenAIWhisperParserLocal,
)
-------------------------------------------------------------------------
ImportError: cannot import name 'OpenAIWhisperParserLocal' from 'langchain_community.document_loaders.parsers' こちらで直るか…
修正
from langchain_community.document_loaders.parsers import ( OpenAIWhisperParser, OpenAIWhisperParserLocal, )
※OpenAIWhisperParserLocalはなくなったよう。
→ from langchain.document_loaders.parsers.audio import OpenAIWhisperParser
これもとりあえずインストールしてみる
pip install transformers torch pydub librosaだめ
このプラグインもダメ↓
絶対できるはず!
Langchain youtube
で、検索
これは!
これでできたからとりあえずいっか…
import os
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import YoutubeLoader
youtube_url = "https://www.youtube.com/watch?v=jGwO_UgTS7I"
loader = YoutubeLoader.from_youtube_url(youtube_url)
docs = loader.load()音声ファイルのダウンロードができないのが気になる…
一筋の光明が!
import subprocess
# コマンドと引数をリスト形式で指定
command = [
'yt-dlp',
'--extract-audio',
'--audio-format', 'm4a',
'--audio-quality', '0',
'-o', 'docs/youtube/%(title)s.%(ext)s',
youtube_url # 実際のYouTube URLに置き換えてください
]
# コマンドを実行
subprocess.run(command)
--------------------------------------------------------------------
[youtube] Extracting URL: https://www.youtube.com/watch?v=jGwO_UgTS7I
[youtube] jGwO_UgTS7I: Downloading webpage
[youtube] jGwO_UgTS7I: Downloading ios player API JSON
[youtube] jGwO_UgTS7I: Downloading android player API JSON
[youtube] jGwO_UgTS7I: Downloading m3u8 information
[info] jGwO_UgTS7I: Downloading 1 format(s): 251
[download] docs/youtube/Stanford CS229: Machine Learning Course, Lecture 1 - Andrew Ng (Autumn 2018).m4a has already been downloaded
ERROR: Postprocessing: ffprobe and ffmpeg not found. Please install or provide the path using --ffmpeg-locationUbuntuにffmpegを入れる!
sudo apt update
sudo apt install ffmpegできた!
ちなみに、これやったら元のコードでもできた!
でも、何が効いているのかわからないので、一応通ったものを掲載
from langchain.document_loaders.generic import GenericLoader
#from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.parsers.audio import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
from langchain.document_loaders import YoutubeLoaderurl="https://www.youtube.com/watch?v=jGwO_UgTS7I"
save_dir="docs/youtube/"
loader = GenericLoader(
YoutubeAudioLoader([url],save_dir),
OpenAIWhisperParser()
)
docs = loader.load()新しい環境でこれでやったら、普通に初めからエラー出たわ。
WARNING: jGwO_UgTS7I: writing DASH m4a. Only some players support this container. Install ffmpeg to fix this automatically
ERROR: Postprocessing: ffprobe and ffmpeg not found. Please install or provide the path using --ffmpeg-location結局、"langchain.document_loaders.parsers" が悪の元凶だったか。
OpenAIWhisper の有無で比較してみる
OpenAIWhisperParser() なし:
Welcome to CS229 Machine Learning. Uh, some of you know that this class has been taught at Stanford for a long time. And this is often the course that, um, I most look forward to teaching each year because this is where we've helped I think, several generations of Stanford students become experts in machine learning, go on to build many of their products and services and startups that I'm sure many of you are pre- or all of you are using, uh, uh, today. Um, so what I want to do today was spend
OpenAIWhisperParser() あり:
Welcome to CS229 Machine Learning. Uh, some of you know that this is a class that's taught at Stanford for a long time. And this is often the class that, um, I most look forward to teaching each year because this is where we've helped, I think, several generations of Stanford students become experts in machine learning, got- built many of their products and services and startups that I'm sure, many of you or probably all of you are using, uh, uh, today. Um, so what I want to do today was spend
ちょっと違う!
あたりまえだが、OpenAIWhisperParser() なしは、YouTubeの字幕と完璧に一致するな。
OpenAIWhisperParser() の方が音に忠実で、補正されていない気がするが、私の英語レベルでは甲乙つけられない。
L2-document_splitting
いろいろ文章を区切ってく!
c_splitterとr_splitter
character text splitterとは、与えられたテキストを個々の文字に分割するプログラムや関数のことです。例えば、"hello"という単語を['h', 'e', 'l', 'l', 'o']のように一文字ずつに分割します。
recursive character text splitterも基本的には文字に分割する機能を持っていますが、「recursive」(再帰的)という言葉が示すように、このタイプのスプリッターは、分割された各要素に対して再び分割を行う機能を持っています。これは主にネストされた構造や複雑なデータ形式を持つテキストで使用されます。例えば、"hello world"を分割する場合、最初に["hello", "world"]に分割し、その後、各単語をさらに文字に分割することができます。
要するに、通常のcharacter text splitterはテキストを一度だけ文字に分割するのに対し、recursive character text splitterはその分割された要素をさらに再帰的に分割することができます。
トークンやメタデータに基づく分割
NotionもMarkdownファイルなんだ
L3-vectorstores_and_embeddings
embeddingしてドット積(内積)を計算
なんで?
NumPyのdot関数を使って、これらの埋め込み間のドット積(内積)を計算しています。ドット積は、二つのベクトル間の類似度を計算するために使われる指標です。値が1に近いほど、二つのベクトル(ここでは二つの文の意味的な表現)は類似していると考えられます。
コードの最後で計算された数値は、それぞれの文のペアの類似度を示しています。例えば、np.dot(embedding1, embedding2)の結果は0.9631903595036999で、これは"sentence1"と"sentence2"が非常に類似していることを示しています。これは、両者が犬を好むという同じ意味を持っているためです。
loadしたドキュメントを使ってvectordbの作成
similarity search
不具合の数々
コードに記載されている問題点は、検索結果に重複があることを指摘しています。つまり、docs[0]とdocs[1]が同一の内容であることが観察されています。これは、データベースのインデックス内に「MachineLearning-Lecture01.pdf」という文書が重複しているために発生します。結果として、類似性検索が実施された際に、同じ文書が複数回結果に現れることになります。
セマンティック検索(意味ベースの検索)は文書の類似性に基づいて結果を提供しますが、デフォルトでは結果の多様性を保証または強制しないという特性があります。このため、重複した内容の文書が検索結果に含まれることがあります。重複を避け、より多様な結果を得るためには、結果を処理して重複を除外する追加のステップが必要になります。これは、例えば検索結果から重複する文書をプログラムで除去することによって実現できます。
レクチャー3から持ってこいと言われてるのに、2から持ってきちゃってる問題
そもそも、「回帰について何と言ってる?」という質問に対して、生徒の「回帰」という質問を持ってきたり、単語に引っ張られすぎだな。要約して保存して、検索するような感じがよさそう。
検索結果をどのように検証したらいいかがわかってとてもよい。
L-4_retrieval
max_marginal_relevance_search: 検索結果に多様性を持たせる
smalldb.max_marginal_relevance_search(question, k=2, fetch_k=3) を使用して、同じ質問に対する文書を、最大限の関連性と多様性を考慮して再度検索しています。このメソッドは、類似度だけでなく、既に選択されたアイテムとの異なり度も考慮するため、異なるアスペクトを持つ文書を取得するのに有効です。
メタデータを考慮した検索
docs = vectordb.similarity_search(
question,
k=3,
filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"}
)クエリから必要なメタデータを推測
metadata_field_info = [
AttributeInfo(
name="source",
description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the lecture",
type="integer",
),
]
document_content_description = "Lecture notes"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)metadata_field_infoの設定:
これは、検索される文書のメタデータの構造を定義します。ここでは、AttributeInfoオブジェクトのリストを使用して、各文書が持つべき属性(フィールド)についての情報を提供しています。
各AttributeInfoは、メタデータのフィールド名(例えば"source"や"page")、そのフィールドの説明、そしてフィールドの型("string"や"integer")を持ちます。
このメタデータ情報は、文書がどのような情報を持っているべきか、そしてそれをどのように扱うべきかを定義するのに役立ちます。例えば、文書がどの講義から来たものか、ページ番号は何かなどです。
文書内容の記述:
document_content_descriptionは、検索対象となる文書の一般的な説明を表します。この場合、「Lecture notes」という説明が用いられており、検索対象となるのは講義ノートであることを意味します。
言語モデルの設定:
llm = OpenAI(temperature=0)により、OpenAIの言語モデルを温度0で初期化しています。温度が低い(ここでは0)と、生成されるテキストはより予測可能で、一貫性があるものになります。これは、質問応答や文書検索で望ましい特性です。
レトリバーの構築:
SelfQueryRetriever.from_llm(...)は、指定された言語モデル、ベクトルデータベース(vectordb)、文書の説明、メタデータ情報を使用して、新しいSelfQueryRetrieverインスタンスを作成します。
このレトリバーは、言語モデルを使用して質問に最も関連する文書を検索します。verbose=Trueが指定されている場合、検索プロセス中に起こる様々なステップの詳細情報が表示されます。
文脈圧縮による検索の効率化
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
# Wrap our vectorstore
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever()
)
question = "what did they say about matlab?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)pretty_print_docs関数:
この関数は、与えられた文書(docs)のリストを受け取り、それらを見やすい形式で出力します。
各文書について、"Document X:" の後にそのページの内容(page_content)が表示されます。文書は番号付きで、各文書は線('-' * 100)で区切られています。
これにより、ユーザーは複数の文書の内容を一度に確認でき、文書間の比較が容易になります。
言語モデルとチェーンエクストラクター:
llm = OpenAI(temperature=0)によって、低温度でOpenAI言語モデル(LLM)のインスタンスが作成されます。これにより、一貫性のあるテキスト生成が可能になります。
LLMChainExtractor.from_llm(llm)は、この言語モデルを用いて文書から情報を抽出するためのエクストラクター(compressor)を作成します。
コンテキスト圧縮レトリバー:
ContextualCompressionRetrieverは、文書の内容を圧縮し、特定の質問に関連する情報のみを抽出するために設計されています。
このオブジェクトは、基本圧縮機能(base_compressor)として先ほどのエクストラクターと、基本検索機能(base_retriever)としてvectordb.as_retriever()(ベクトルデータベースからの検索機能)を使用します。
compression_retriever.get_relevant_documents(question)メソッドは、提供された質問(ここでは"what did they say about matlab?")に関連する文書を検索し、それらの内容を圧縮して関連情報のみを取得します。
文書の表示:
pretty_print_docs(compressed_docs)は、圧縮された文書(compressed_docs)を取得して、それらを読みやすい形で出力します。これにより、ユーザーは質問に関連する具体的な情報を手早く得ることができます。
どうやって圧縮して、どうやって戻しているの?
ContextualCompressionRetrieverは、元の文書から、特定の質問に答えるために必要な情報だけを抽出(圧縮)する機能を持っています。このプロセスでは、言語モデル(LLM)を使用して、質問に対して最も関連性が高いと思われる文書の部分を特定し、それらを「圧縮文書」として提供します。
具体的に、compression_retriever.get_relevant_documents(question)は次のように機能します:質問を受け取ります。
ベクトルデータベースを使用して、その質問に関連する文書を検索します。
各文書に対して、質問に関連する最も重要な部分(セクション、段落、文など)を特定します。
これらの部分を抽出して、元の文書から不要な情報を「削除(圧縮)」します。
pretty_print_docs関数では、この「圧縮された」文書の集合がどのように表示されているかを確認できます。具体的には、次の手順で文書を表示します:各圧縮された文書について、文書番号(Document X:)と共にその内容(page_content)を表示します。
文書の内容は改行で区切られ、各文書は線('-' * 100)で区切られています。
この関数により、ユーザーは圧縮された各文書の内容を順番に、明確に区別して閲覧することができ、質問に対する関連情報を迅速に把握できるようになります。
圧縮とリトリーバの融合
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever(search_type = "mmr")
)その他の検索法:TF-IDF, SVM
文書の検索とランキング:
SVMRetrieverとTFIDFRetrieverは、それぞれ異なる方法(SVM法とTF-IDF法)でテキストチャンクに基づいて質問に最も関連する文書を見つけ出します。
これらのレトリバーは、分割されたテキストチャンクから質問(例:「What are major topics for this class?」や「what did they say about matlab?」)に関連するものを選び出します。
結果の表示:
pretty_print_docs関数を使用して、検索によって見つかった最も関連性の高い文書(チャンク)を表示します。ここでは、各レトリバーによって最も関連性が高いと判断された文書の一部が出力されています。
vectordbのレトリバー、SVMRetriever、およびTFIDFRetrieverの違いとそれぞれの長所は?
vectordbのレトリバー:
これは一般的にベクトル検索を行うためのレトリバーであり、文書やテキストチャンクを高次元のベクトル空間にマッピングします。
長所: 高速な検索が可能で、意味的類似性に基づいて文書をマッチングすることができます。大規模なデータセットに適しており、様々なタイプのクエリに対応可能です。
SVMRetriever:
サポートベクターマシン(SVM)を用いて文書を検索します。これは教師あり学習モデルを使用して、文書と質問の関連性を評価します。
長所: 二値分類(関連あり/なし)に優れており、特にカスタマイズされたトレーニングデータに基づく場合、非常に正確な検索結果を提供することができます。特定の種類の質問や文書に対して高いパフォーマンスを発揮します。
TFIDFRetriever:
このレトリバーは、テキストの「単語の頻度」と「逆文書頻度」(TF-IDF)を使用して文書をランキングします。この手法は、文書内の単語の重要性を測定し、クエリと文書間の関連性を評価します。
長所: 簡単に実装でき、理解しやすい。特定のキーワードやフレーズが重要な場合に有効で、大規模なテキストコレクションに対して迅速な検索を提供します。また、少量のデータでも効果的に機能します。
それぞれのレトリバーは異なる状況や要求に応じて選択されるべきです。たとえば、非常に大規模なデータセットで意味的類似性を重視する場合はvectordbのレトリバーが、特定の条件下での精密なフィルタリングが必要な場合はSVMRetrieverが、そして高速で簡易な検索が求められる場合はTFIDFRetrieverが適していると言えます。
L-5_question_answering
RetrievalQAでの応答
dbサーチの結果とRetrievalの結果を見比べると面白い
dbサーチの結果:
しばらく統計学や代数学を勉強したことがあるので、復習をしたい人のためにディスカッション・セクションでその内容を説明する。 今期の後半には、ディスカッションのセクションを使って、メイン講義で教える内容の拡張についても説明します。機械学習は巨大な分野なので、メイン講義では時間が取れなかったけれど、本当に教えたい拡張部分がいくつかあります。
機械学習は巨大な分野なので、本講義では教える時間がなかったが、本当に教えたい拡張機能がいくつかある。 今期の後半には、ディスカッションのセクションを使って、メイン講義で教える内容の拡張についても説明します。機械学習は巨大な分野なので、メイン講義では時間が取れなかったけれど、本当に教えたい拡張機能がいくつかあります。授業の途中ですが、ビデオがないので、安心して座って私の顔を見てください。
見てみよう。ほとんどの人が持っていると思いますが、コースの案内プリントです。そのうちの一部について少しお話ししましょう。ページ目にオンライン・リソースという項目があります。 ああ、わかりました。もっと大きな声で?ボリュームを上げてもらえますか?テスト中です。こっちの方がいい? テスト、テスト。オーケー、クール。ありがとう
Retrievalの結果:
このクラスの主なトピックには、機械学習、統計学、代数学が含まれる。さらに、主要な講義で扱われる材料の拡張に関する議論も行われる
PromptTemplateの利用
何してるの?
プロンプトテンプレートの定義:
PromptTemplate.from_template(template)を使用して、言語モデルが質問に回答する際に従うべき指示(プロンプト)のテンプレートを定義しています。このテンプレートには、回答の生成に際して守るべきガイドラインが含まれています(例:回答は3文以内で、できるだけ簡潔に、わからない場合はその旨を言う、常に「thanks for asking!」で終えるなど)。
質問応答チェーンの構築:
RetrievalQA.from_chain_type(...)を用いて、レトリーバーとプロンプトテンプレートを組み込んだ質問応答(QA)チェーンを作成しています。このチェーンは、指定された質問に対する文書の検索と、検索結果を基にした回答の生成を行います。
ここでのretriever=vectordb.as_retriever()は、事前に構成されたベクトルデータベースから文書を検索するための機能を提供します。
return_source_documents=Trueは、回答に加えて、その回答がどの文書に基づいているかの情報も返すように指定しています。
質問応答の実行:
qa_chain({"query": question})を実行して、定義された質問応答チェーンを通じて質問(「Is probability a class topic?」)に対する回答を取得しています。
結果の表示:
result["result"]を使用して、質問応答チェーンから得られた回答を表示しています。この回答は、上で定義されたプロンプトテンプレートに従って生成されており、指示されたフォーマットと表現で回答が提供されています。
検索結果を文脈として参照するように明示するだけでなく、応答の形式を指定している。
プロンプトの結果:
はい、基本的な確率や統計に精通していることが前提なので、確率は授業で扱うトピックです。聞いてくれてありがとう!
RetrievalQA chain のタイプ
なんか、時間がかかる気がする。
chain_type="map_reduce"の結果:
このクラスの主なトピックは、統計学、代数学、機械学習です。これらに加えて、主要な講義で扱われる材料の拡張に関する議論も行われる
chain_type="refine"の結果:
このクラスの主なトピックは、機械学習、統計学、そして場合によっては代数学である。これらのトピックに加え、本講義で扱われる内容の拡張に関するディスカッションや、必要と思われる人のための統計学と代数学の再教育セッションが行われる。また、ディスカッションのセクションでは、メイン講義ではカバーしきれなかった機械学習の追加拡張についても取り上げる。コースでは、さらなる学習や参考のためのオンライン・リソースも提供する。さらに、コースの案内プリントには、受講生がアクセスできるオンラインリソースの詳細が記載されている。
map_reduceとrefineはどんな特徴があるの?
map_reduceアプローチ:
特徴: map_reduceモードでは、多数の文書または情報源から情報を集約して一つの結論に絞り込むプロセスを模倣します。最初に、複数の文書やデータポイント("map"フェーズ)から関連情報が抽出されます。次に、これらの情報ピースが組み合わされて("reduce"フェーズ)、質問に対する総合的な回答が生成されます。
長所: 複数の情報源からのデータを合成して、より広範囲の視点を提供できるため、単一の文書に依存しない、より包括的な回答を得ることができます。複雑な問題や多面的な質問に適しています。
refineアプローチ:
特徴: refineモードでは、特定の情報や回答を精査し、洗練させるプロセスを行います。ここでは、検索された情報を基に初期の回答が生成された後、さらに詳細や精度を高めるために追加の情報を探索します。
長所: 初期の回答を詳細化し、特定の質問に対するより精確な説明を提供できます。不明確な点や疑問が残る場合に、より具体的な情報を提供することで回答を改善できます。
RetrivalQAの限界:会話履歴の保存ができない
"確率は授業のテーマですか?"
そう、確率はこのクラスの学生にとってなじみのあるトピックであることが前提である。講師は、基本的な確率と統計がこの授業の前提条件であることに言及しており、スタンフォード大学で教えているStat 116のような、ほとんどの学部の統計の授業で十二分であると想定している。
"なぜそのような前提条件が必要なのですか?"
この授業の前提条件は、コンピュータサイエンスの基礎知識、コンピュータの基本的な技術と原則である。講師は、すべての受講生がBig-O記法を知っており、コンピュータサイエンスの基本的な理解を持っていることを前提としている。これらの前提条件は、すべての受講生が授業の技術的な内容についていけるようにするために必要である。
会話のコンテキストの保存が難しい:
このタイプのシステムは、それぞれの質問を独立したエンティティとして扱います。これは、過去の質問と回答のコンテキストを次の質問へと「引き継ぐ」ことが難しいことを意味します。上の例では、最初の質問「Is probability a class topic?」への回答の後、二番目の質問「why are those prerequisites needed?」は、最初の質問のコンテキストを全く反映していません。
限定された情報源に依存:
RetrievalQAは、事前に指定された情報源(例えば、特定の文書セットやデータベース)からのみ情報を取得します。これにより、情報が古い、不完全、またはバイアスがかかっている可能性があります。
回答の精度と信頼性:
システムが提供する回答の正確さは、使用されるモデルや情報源の品質に強く依存します。不正確な情報源からの情報を基に回答が生成されると、誤った回答や誤解を招く情報が提供される可能性があります。
ジェネリックな回答の生成:
特に広範な質問や一般的な質問に対して、システムが非常に一般的な回答を生成することがあります。これは、質問に対する具体的で有用な回答をユーザーが得られない場合があることを意味します。
テクニカルな制限とシステムの信頼性:
上記の例で見られるように、システムがサービス不可や過負荷のために回答を提供できない場合があります。これにより、ユーザー体験が損なわれ、信頼性が低下する可能性があります。
これらの限界を理解することは、RetrievalQAのようなシステムを効果的に使用し、適切なコンテキストや状況で適用するために重要です。また、これらの問題を解決するための改善策や代替アプローチを検討することも有効です。
L6-chat
ModuleNotFoundError: No module named 'panel'
久々にエラーきた!
%pip install panelModuleNotFoundError: No module named 'jupyter_bokeh'
%pip install jupyter_bokehAttributeError: type object 'hnswlib.Index' has no attribute 'file_handle_count'
%pip install --upgrade hnswlib
%%pip install --upgrade langchain-communityできん!
embeddingに警告が出ていた。
/home/user/.local/lib/python3.10/site-packages/langchain_core/_api/deprecation.py:117: LangChainDeprecationWarning: The class `langchain_community.embeddings.openai.OpenAIEmbeddings` was deprecated in langchain-community 0.0.9 and will be removed in 0.2.0. An updated version of the class exists in the langchain-openai package and should be used instead. To use it run `pip install -U langchain-openai` and import as `from langchain_openai import OpenAIEmbeddings`.
warn_deprecated(なので…
%pip install --upgrade langchain-openai# from langchain.embeddings.openai import OpenAIEmbeddings
from langchain_openai import OpenAIEmbeddingsできん!
Copilotが教えてくれた!
%pip install chromadb==0.4.3できた…
以下、コースの中身
"確率は授業のテーマですか?"への回答
プロンプトによる:
# Build prompt
from langchain.prompts import PromptTemplate
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context", "question"],template=template,)はい、確率はこの授業の前提条件です。講師は基本的な確率と統計に精通していることを前提としており、復習としてディスカッションのセクションで前提条件のいくつかを説明します。ご質問ありがとうございました!
ConversationalRetrievalChain
メモリーもいれていく!
"確率は授業のテーマですか?"
そう、確率はこのクラスの学生にとって身近なトピックであることが前提である。講師は、受講生が確率と統計について基本的な理解を持っていることを前提とし、ディスカッションのセクションで復習として前提条件のいくつかを説明します。
"なぜそのような前提条件が必要なのですか?"
この授業では、基本的な確率と統計、基本的な線形代数、基本的なコンピュータサイエンスのスキルと原則に精通していることを前提としているため、前提条件が必要です。この授業では機械学習アルゴリズムとその応用を取り上げるが、これらの前提条件を基本的に理解しておくことは、授業で学ぶ概念をよりよく理解し、応用するのに役立つ。
メモリがあった方が、Q&Aも自然だな
リトリーバルで質問に答えるチャットボット
何してるの?
このコードは、PDF文書を読み込んで、それに基づいた対話型のチャットボットを構築するためのものです。以下は、コードが実行する主なステップです:
1. **PDF文書の読み込みと処理**:
- `PyPDFLoader`を使用してPDF文書を読み込み、その内容を取得します。
- `RecursiveCharacterTextSplitter`で文書を小さなチャンクに分割します。
- 分割されたテキストに基づいて、`OpenAIEmbeddings`を使用して各チャンクの埋め込みを生成します。
- 生成された埋め込みを使用して、`DocArrayInMemorySearch`ベクトルデータベースを作成し、類似性検索を行えるようにします。
2. **チャットボットチェーンの構築**:
- `ConversationalRetrievalChain`を使用して、対話型の質問応答チェーンを構築します。このチェーンは、ユーザーからの質問に基づいて関連する情報を検索し、回答を生成します。
- `load_db`関数を通じて、上記の処理を実行し、構築されたチャットボットチェーンを取得します。
3. **チャットボットのインターフェース構築**:
- `panel`と`param`ライブラリを使用して、チャットボットのGUI(グラフィカルユーザーインターフェース)を構築します。
- `cbfs`クラス内で、ユーザーの質問を処理し、チャットボットからの回答を表示するためのメソッドを定義します。
- ユーザーからの質問を処理する`convchain`メソッド、データベースへの最後のクエリを表示する`get_lquest`メソッド、データベースの応答を表示する`get_sources`メソッド、現在のチャット履歴を表示する`get_chats`メソッドなどがあります。
- ユーザーが新しい質問をすると、`convchain`メソッドがそれを処理し、チャット履歴を更新し、新しい回答を表示します。
4. **チャット履歴の管理**:
- チャット履歴は、ユーザーとチャットボット間の対話の記録を保持します。
- `clr_history`メソッドによって、チャット履歴をクリアする機能が提供されます。
このコード全体は、指定されたドキュメントに関する質問に答える能力を持つ対話型のチャットボットを提供するためのものです。このチャットボットは、ユーザーが提出した質問に基づいて文書から関連情報を検索し、それを用いて回答を生成します。
panelとparamってなに?
panel は、Pythonのデータ可視化ライブラリで、インタラクティブなウェブアプリケーションやダッシュボードを簡単に作成できます。Bokeh、Matplotlib、Plotlyなどの他の可視化ライブラリと組み合わせて使用されることが多いです。panelを使うと、Pythonのコードで定義したインターフェースをウェブブラウザ上で動作させることができます。データサイエンティストや開発者は、panelを使ってデータ分析結果をインタラクティブなグラフや表として表示したり、ユーザー入力に基づいて動的に内容を変更するウェブアプリを簡単に作成できます。
param は、Pythonで宣言的なパラメーターと設定を管理するためのライブラリです。paramでは、クラスの属性をパラメータとして定義し、その属性の型、デフォルト値、有効範囲などを指定できます。これにより、コードの再利用性を高め、クラスのインターフェースを明確にし、エラーを減少させることができます。panelと組み合わせて使用されることで、ユーザーインターフェースからパラメータを動的に調整し、その結果をリアルタイムで反映させるアプリケーションを作成できます。
例: paramライブラリを使って、数値の範囲や選択肢を持つパラメータを持つシンプルなクラスを定義し、panelを使ってそれをユーザーインターフェースに組み込むことができます。ユーザーがインターフェース上でパラメータを変更すると、その変更がPythonコードに自動的に反映され、結果がウェブアプリケーション上で更新されます。
細かく見ていく
def load_db(file, chain_type, k): ってなに?
このload_db関数は、特定のPDFファイルからデータを読み込み、処理して、それを基に会話型チャットボットを構築する一連のプロセスを実行するためのものです。以下、関数内の各ステップについて詳しく説明します:PDF文書の読み込み:
PyPDFLoaderを使用して、引数fileで指定されたPDFファイルを読み込みます。これにより、PDFファイルの内容がdocumentsという変数に格納されます。
文書の分割:
RecursiveCharacterTextSplitterを用いて、読み込まれたPDF文書(documents)を小さなテキストチャンクに分割します。ここで、chunk_size=1000は各チャンクの文字数、chunk_overlap=150はチャンク間の重複する文字数を指定しています。これにより、大きな文書が小さなセグメント(docs)に分けられます。
テキストの埋め込み定義:
OpenAIEmbeddingsを使用して、分割されたテキストチャンク(docs)の埋め込み(ベクトル表現)を生成します。これにより、各テキストチャンクはベクトル空間内の点として表現されます。
ベクトルデータベースの作成:
DocArrayInMemorySearch.from_documentsを使用して、テキストチャンクの埋め込みを基にベクトルデータベース(db)を作成します。これは、後の検索で使用されます。
レトリバーの定義:
db.as_retrieverを用いて、ベクトルデータベースから検索を行うためのレトリバー(retriever)を定義します。ここでのsearch_type="similarity"は、類似性に基づく検索を指定し、search_kwargs={"k": k}は検索結果の上位k件を取得することを意味します。
チャットボットチェーンの作成:
ConversationalRetrievalChain.from_llmを使用して、会話型の質問応答(QA)チェーン(qa)を構築します。ここで、llm=ChatOpenAI(model_name=llm_name, temperature=0)は使用する言語モデル(ChatOpenAIのインスタンス)を指定し、chain_type=chain_typeはチェーンのタイプを指定します。また、return_source_documents=Trueは、回答と共に元の文書を返すように指定し、return_generated_question=Trueは生成された質問も返すように指定します。
関数の戻り値:
最後に、構築されたチャットボットチェーン(qa)を関数の戻り値として返します。これにより、このチェーンを使用してユーザーの質問に対する回答を生成したり、会話を管理したりできます。
panel と param は何をしている?
属性定義:
chat_history: ユーザーとチャットボット間の会話履歴をリストで保持します。
answer: チャットボットからの最新の回答を格納します。
db_query: チャットボットがデータベースに送った最新のクエリを格納します。
db_response: データベースからの最新の応答をリストで保持します。
初期化関数 (__init__):
インスタンスの初期化時に、デフォルトのPDFファイルからデータをロードし、チャットボット(qa)をセットアップします。
call_load_dbメソッド:
新しいPDFファイルが提供された場合、そのファイルからデータをロードしてチャットボットを再セットアップします。また、会話履歴をクリアします。
convchainメソッド:
ユーザーからのクエリを受け取り、チャットボットによる回答プロセスを実行します。結果として得られる回答、生成されたクエリ、ソース文書などを保存し、UIに表示するためのコンテンツを更新します。
get_lquestメソッド:
最新のデータベースクエリ(db_query)を表示するためのUIコンポーネントを生成します。何もクエリがない場合は、「no DB accesses so far」と表示します。
get_sourcesメソッド:
データベース応答(db_response)に基づく情報を表示するためのUIコンポーネントを生成します。
get_chatsメソッド:
会話履歴(chat_history)を表示するためのUIコンポーネントを生成します。まだ履歴がない場合は、「No History Yet」と表示します。
clr_historyメソッド:
会話履歴をクリアします。
このクラスを使用すると、ユーザーがPDF文書に基づいて質問をすると、それに対する回答を生成し、会話の履歴を追跡し、データベースクエリとその応答を管理するインタラクティブなウェブアプリケーションを構築できます。panelライブラリは、これらのプロセスとインタラクションをウェブブラウザ上で可視化し、操作可能にします。
チャットボットを作る
このコードは、panelを使ってインタラクティブなチャットボットのダッシュボードを構築しています。cbfsクラスのインスタンスを作成し、それを使用して、ユーザー入力、データベースクエリ、チャット履歴、および設定オプションを含むウェブベースのインターフェースを定義しています。以下に、主なコンポーネントと機能を説明します。
インターフェースの初期化:
cbfsのインスタンスcbを作成します。
ウィジェットの設定:
file_input: PDFファイルをアップロードするためのファイル入力ウィジェット。
button_load: アップロードされたPDFファイルを読み込んでデータベース(DB)として使用するためのボタン。
button_clearhistory: チャット履歴をクリアするためのボタン。
inp: ユーザーが質問を入力できるテキスト入力フィールド。
ウィジェットのバインディング:
bound_button_load: button_loadボタンのクリックをcb.call_load_dbメソッドにバインドし、PDFデータベースの読み込みを実行します。
conversation: ユーザーの入力(inpウィジェットからのテキスト)をcb.convchainメソッドにバインドし、チャットボットからの回答を生成します。
ダッシュボードの構成:
tab1〜tab4: ダッシュボードの異なるセクションを定義し、それぞれのタブには異なる機能があります:
tab1 (Conversation): ユーザーが質問を入力し、チャットボットの回答を表示するエリア。
tab2 (Database): 最後にデータベースに問い合わせたクエリとその応答を表示します。
tab3 (Chat History): 現在のチャット履歴を表示します。
tab4 (Configure): ファイル入力ウィジェット、データベースの読み込みボタン、チャット履歴のクリアボタン、および追加情報を配置した設定セクション。
dashboard: これらのタブを含む全体のダッシュボードレイアウト。
ダッシュボードの表示:
最後に、dashboardオブジェクトがダッシュボード全体を表し、これを使用してウェブアプリケーションのインターフェースを表示します。
チャットGUIのエラー
WARNING:param.Column00118: Displaying Panel objects in the notebook requires the panel extension to be loaded. Ensure you run pn.extension() before displaying objects in the notebook.対処:
import panel as pn
pn.extension()Notebook内でやり取りできるのすご!
注意:def load_db(chain_type, k): のセルはコメントアウト
セルを順番通りやっていくと、チャットボットの所で次のように怒られます。
TypeError: load_db() takes 2 positional arguments but 3 were givendef load_db(chain_type, k): のセルをコメントアウトすると、チャットボットの部分でdef load_db(file, chain_type, k): のセルの方がちゃんと動きます
参考Github
おまけ:ブラウザで動かす
Create a chatbot that works on your documents 以下のチャットボットに関わる3つのセルに加えて、次の部分をdashboard.py に保存
import os
import openai
import sys
sys.path.append('../..')
import panel as pn # GUI
pn.extension()
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
import datetime
current_date = datetime.datetime.now().date()
if current_date < datetime.date(2023, 9, 2):
llm_name = "gpt-3.5-turbo-0301"
else:
llm_name = "gpt-3.5-turbo"
print(llm_name)ターミナルから次のコードで、ブラウザに表示
panel serve dashboard.py --showエラーで動かん
pip install -U langchain-openai
インポート文の修正
# from langchain.embeddings.openai import OpenAIEmbeddings
# from langchain.chat_models import ChatOpenAI
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
# from langchain.vectorstores import DocArrayInMemorySearch
# from langchain.document_loaders import PyPDFLoader
# from langchain.document_loaders import TextLoader
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.document_loaders import TextLoader, PyPDFLoader何もうつらん…
ディベロッパーツールでエラーが確認できますね。
console.log("Bokeh: ERROR: Unable to run BokehJS code because BokehJS library is missing");これはHTML作らないとダメなやつかな…
Panel がダメみたいなんで、Streamlit に変えます。で、機能は入力と履歴の表示だけにします。
dashboard2.py:
import os
import openai
import sys
sys.path.append('../..')
import panel as pn # GUI
pn.extension()
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
import datetime
current_date = datetime.datetime.now().date()
if current_date < datetime.date(2023, 9, 2):
llm_name = "gpt-3.5-turbo-0301"
else:
llm_name = "gpt-3.5-turbo"
print(llm_name)
# from langchain.embeddings.openai import OpenAIEmbeddings
# from langchain.chat_models import ChatOpenAI
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
# from langchain.vectorstores import DocArrayInMemorySearch
# from langchain.document_loaders import PyPDFLoader
# from langchain.document_loaders import TextLoader
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
def load_db(file, chain_type, k):
# load documents
loader = PyPDFLoader(file)
documents = loader.load()
# split documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
docs = text_splitter.split_documents(documents)
# define embedding
embeddings = OpenAIEmbeddings()
# create vector database from data
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
# define retriever
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chatbot chain. Memory is managed externally.
qa = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(model_name=llm_name, temperature=0),
chain_type=chain_type,
retriever=retriever,
return_source_documents=True,
return_generated_question=True,
)
return qa
import panel as pn
import param
class cbfs(param.Parameterized):
chat_history = param.List([])
answer = param.String("")
db_query = param.String("")
db_response = param.List([])
def __init__(self, **params):
super(cbfs, self).__init__( **params)
self.panels = []
self.loaded_file = "docs/cs229_lectures/MachineLearning-Lecture01.pdf"
self.qa = load_db(self.loaded_file,"stuff", 4)
def call_load_db(self, count):
if count == 0 or file_input.value is None: # init or no file specified :
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
else:
file_input.save("temp.pdf") # local copy
self.loaded_file = file_input.filename
button_load.button_style="outline"
self.qa = load_db("temp.pdf", "stuff", 4)
button_load.button_style="solid"
self.clr_history()
return pn.pane.Markdown(f"Loaded File: {self.loaded_file}")
# def convchain(self, query):
# if not query:
# return pn.WidgetBox(pn.Row('User:', pn.pane.Markdown("", width=600)), scroll=True)
# result = self.qa({"question": query, "chat_history": self.chat_history})
# self.chat_history.extend([(query, result["answer"])])
# self.db_query = result["generated_question"]
# self.db_response = result["source_documents"]
# self.answer = result['answer']
# self.panels.extend([
# pn.Row('User:', pn.pane.Markdown(query, width=600)),
# pn.Row('ChatBot:', pn.pane.Markdown(self.answer, width=600, style={'background-color': '#F6F6F6'}))
# ])
# inp.value = '' #clears loading indicator when cleared
# return pn.WidgetBox(*self.panels,scroll=True)
def convchain(self, query):
if not query:
return # 何もしない
result = self.qa({"question": query, "chat_history": self.chat_history})
self.chat_history.extend([(query, result["answer"])])
self.db_query = result["generated_question"]
self.db_response = result["source_documents"]
self.answer = result['answer']
# inp.value = '' # この行は削除またはコメントアウトします。
return result # 必要に応じて結果を返します。
@param.depends('db_query ', )
def get_lquest(self):
if not self.db_query :
return pn.Column(
pn.Row(pn.pane.Markdown(f"Last question to DB:", styles={'background-color': '#F6F6F6'})),
pn.Row(pn.pane.Str("no DB accesses so far"))
)
return pn.Column(
pn.Row(pn.pane.Markdown(f"DB query:", styles={'background-color': '#F6F6F6'})),
pn.pane.Str(self.db_query )
)
@param.depends('db_response', )
def get_sources(self):
if not self.db_response:
return
rlist=[pn.Row(pn.pane.Markdown(f"Result of DB lookup:", styles={'background-color': '#F6F6F6'}))]
for doc in self.db_response:
rlist.append(pn.Row(pn.pane.Str(doc)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
@param.depends('convchain', 'clr_history')
def get_chats(self):
if not self.chat_history:
return pn.WidgetBox(pn.Row(pn.pane.Str("No History Yet")), width=600, scroll=True)
rlist=[pn.Row(pn.pane.Markdown(f"Current Chat History variable", styles={'background-color': '#F6F6F6'}))]
for exchange in self.chat_history:
rlist.append(pn.Row(pn.pane.Str(exchange)))
return pn.WidgetBox(*rlist, width=600, scroll=True)
def clr_history(self,count=0):
self.chat_history = []
return
cb = cbfs()
# GUI
import streamlit as st
# Streamlit のユーザー入力フィールドを定義
user_input = st.text_input('Enter your question here:')
# session_stateに 'chat_history' が存在しない場合、空のリストとして初期化する
if 'chat_history' not in st.session_state:
st.session_state['chat_history'] = []
# ユーザーが質問を入力した場合の処理
if user_input:
# LangChain または他のロジックを使用して回答を生成する処理をここに実装します。
# 以下は仮の処理フローです。
result = cb.convchain(user_input) # 実際には convchain メソッドの出力を適切に処理する必要があります。
real_answer = result['answer'] # 実際の回答を取得します。
st.session_state['chat_history'].append((user_input, real_answer))
# チャット履歴を表示
st.write('## Chat History')
for question, answer in st.session_state['chat_history']:
st.text(f'You: {question}')
st.text(f'Bot: {answer}')
# チャット履歴をクリアするボタン
if st.button('Clear History'):
st.session_state['chat_history'] = []
で、ターミナルから↓を実行
streamlit run dashboard2.pyできた!
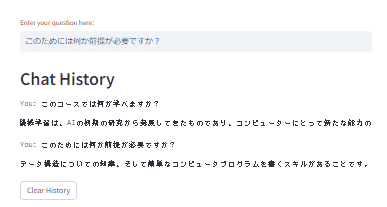
長い旅路はこれで終わり。無事完遂できてよかった。マルチターン&マルチタスク・エージェント作りたい。
LangSmithも使ってみたいな
(同)実践サイコロジー研究所は、心理学サービスの国内での普及を目指しています! 『適切な支援をそれを求めるすべての人へ』