Pythonで大谷翔平選手の2022年シーズンのホームラン数を予想しよう!

目次
A.はじめに
B.実行環境
C.目的
D.実行コードの解説と考察
E.結論
F.おわりに
A.はじめに
この機械学習モデルはAidemy Premium データ分析3ヶ月講座で学んだスキルを基に作っております。
データがお金以上に大事な資産と言われている昨今、具体的にどのようなデータが、どのように活用されているのかに興味を持ち、機械学習を作る側の世界も実感してみたいと思い、Aidemyの受講を決めました。
作る側の世界を実感してみた感想として、
1. 機械学習前のデータ処理の作業が一番ウェイトが重く、ライブラリーや関数の技の範囲を広げるには熟練が必要。
2 . どのように機械学習を利用したいのかによって、必要な数学の理解度が異なってくる。例えば、アルゴリズムを作る側になるには、そのアルゴリズムの原動力となる数学モデルを自ら創り上げれる程の理解度が必要がある。
一方で、既に存在するアルゴリズムを使用した今回の機械学習モデルであれば、
数学の理解度はそこまで必要無く、このアルゴリズムでは何がされているのか?という理解のみで機械学習モデルを作ることができる。
3 . やればやるほど奥深さがあり、シンプルに楽しい。マインクラフトやLego作りなどにも通ずる所があり、好きな人は是非機械学習への挑戦もおすすめです。
Aidemy Premium データ分析講座を受講してみた結論として、世界の先端技術の根底にあるメカニズムに触れることができ、簡易的ながらも自作の機械学習モデルまで作れた事に大変満足です。
B.実行環境
Jupyter Notebook 6.4.5
Python 3.9.3
C.目的
今回の最終的な目標は、大谷翔平選手の2022年のHR数を予想する機会学習モデルを作成します。
そのためには、大きく4つのステップにわけて、処理を進めていきます。
2016〜21年の全選手(野手)の※スタットキャストの各指標を説明変数、HR数を正解ラベルに設定し、2022年のHR数を予想する重回帰モデルを作成する。
2016〜21年の全選手(野手)の※スタットキャストの各指標を第一、第二主成分の2次元の特徴量に変換し、KMeans法で全選手のクラスター分けを行う。
各クラスター毎に任意の平均と標準偏差に従う確率分布を作成し、2022年のスタットキャストの各指標として、Random.normal関数を使用して確率変数を振り分ける。
ステップ3で振り分けした各指標を重回帰モデルに入力して、2022年のHR数を予想する。
以上4つのステップを一つずつ細かく解説していきます。
単に大谷翔平選手の今シーズンのホームラン数が気になる方、機械学習のメカニズムに興味がある方、自分で機械学習モデルを作ってみるのに興味がある方はぜひ最後まで読んでみてください。
また、結果のみが気になる方は、最後のE.結論まで飛ばして頂いても構いません。
※スタットキャストとは - https://ja.wikipedia.org/wiki/スタットキャスト
D.実行コードの解説と考察
ステップ0 必要なデータとライブラリーの取得

野球専用の米データサイト「Fangraphs」より、2016〜21年間の全選手のスタットキャストの指標をCSV形式でダウンロード。それをエクセルで一つのグラフにまとめて、”MLB data"というタイトルのCSVファイルで保存。
そのファイルをJupyter Notebookにアップロードすることによって、データを利用できるようにします。
下記が今回利用するデータをデータ群に変換したものになります。
左側の1列目が選手名[Name]で始まり、一番右側の[player id]まで、1368行27列のテーブルです。

こちらがデータ群のカラム(特徴量)一覧です。
・Name = 選手名
・Team =所属チーム
・Events =打席数(三振、四球/四球を除く)
・EV = 平均打球速度
・ maxEV = 最速打球速度
・LA = 平均打球角度
・FB% =フライ率
・LD% =ラインドライブ率
・GB% =ゴロ率
・Barrels=バレル(簡潔にいうと、任意の打球速度と打球角度を組み合わせた指標)
・Barrel%=バレル率
・HardHit=打球速度が95mph以上だった打球数
・Hardhit%=打球速度が95%以上である確率
・SLG =長打率
・xSLG=期待長打率
・wOBA ※
・xwOBA=期待wOBA
・PA = 打席数
・HR=ホームラン数
・HR/AB=ホームラン率
・Age=年齢
・under 25,30,35,over 35 = 年齢がある値以下、もしくは以上か
・year =年度
・playerid = 選手Id
※wOBAとは- https://ja.wikipedia.org/wiki/WOBA

上記のカラムから今回利用するカラムのみを抽出します。
次に、FB%,LD%,GB%,Barrel%,HardHit%のカラムでは、数値に%が付いたObject型のデータとなっており、このままでは重回帰モデルに数値を渡せないので、以下3つの処理を行います。
1. 数値から%の表記を外す。
2.Object型をfloat(浮動小数点)型に変換する。
3.パーセント数値を小数点に直すために、100で割る。
上記処理を行なったデータ群をstatistics変数に代入します。

ステップ1 重回帰モデルの作成
重回帰モデルの作成には4つのデータ群が必要となります。
1.訓練用データ
2.テスト用データ
3.訓練用データの正解ラベル
4.テスト用データの正解ラベル
これから先ほど作成したstatistics変数のデータ群を4つのデータ群に分けていきます。
まずは、訓練用とテスト用の2つにデータを分けたいので、その処理を行います。
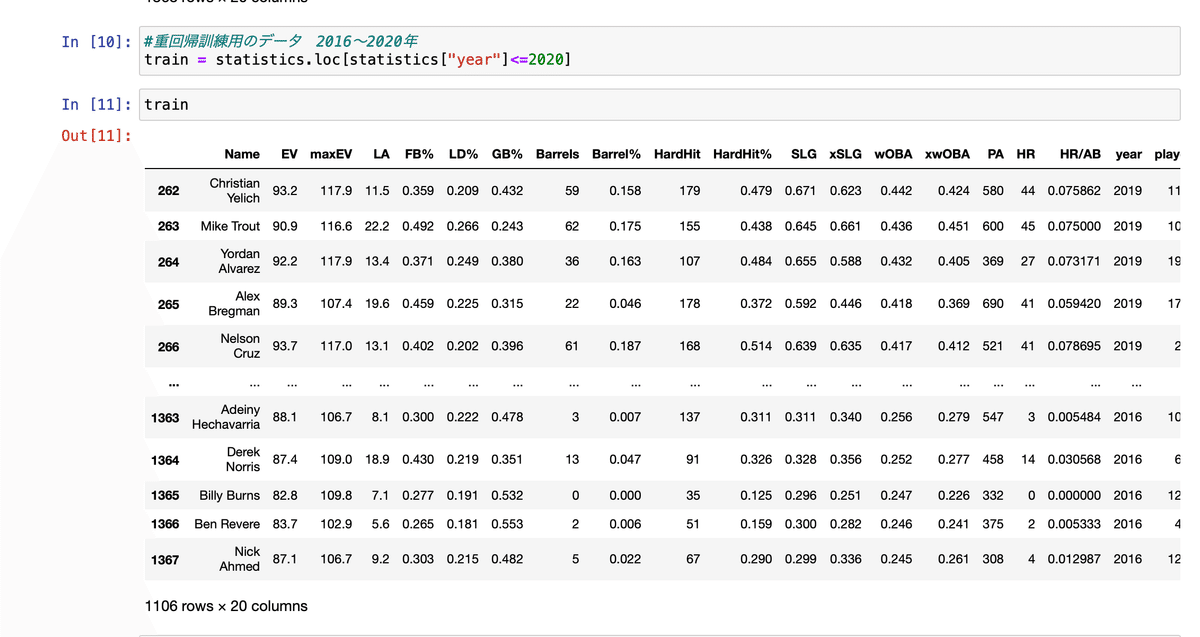
訓練用データ群には2020年以前のデータを使用していきますので、train変数にstatistics変数の2020年以前のデータを代入します。
同様にテスト用のデータ群(test変数)を作成します。

更にここから4つのデータ群に分けていきます。
1. 訓練用データ
重回帰モデルに渡す以外の列は全て削除します。

2.テスト用データ
テスト用にも同様の処理を行います。

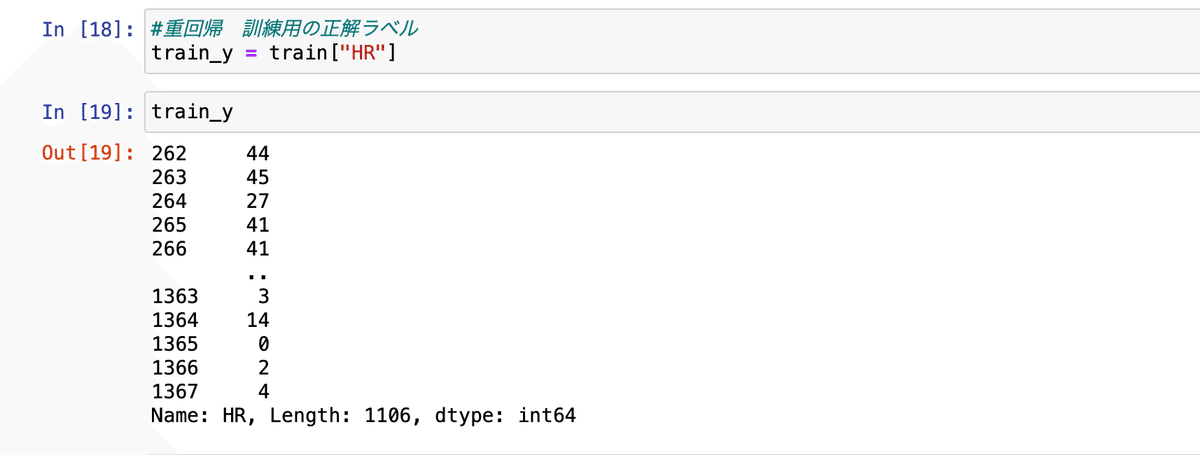
3.訓練用データの正解ラベル
train_y変数を作成して、train変数のHR列を代入します。
4.テスト用の正解ラベル
3と同様の処理を行います。

4つのデータ群を作成したところで、重回帰モデルを作成していきます。
ここで重回帰を含む回帰分析の性質として、特徴量が多すぎたり、過去のデータに適合しすぎたりすると、データの予測がうまくいかない場合もあります。この現象を過学習と呼びます。
そのため、15列のデータ全てをそのまま機械学習モデルに渡す線形回帰モデルの他に、過学習を防ぐための正則化を行なったラッソ回帰、リッジ回帰、ElasticNet回帰の計4つのモデルにデータを渡し、決定係数の一番高いモデルを採用することにします。

その結果、線形回帰モデルが92%で最も精度の高いモデルであることがわかりました。よって線形回帰モデルを利用していきます。
なお、線形回帰モデルの精度の基準には最小二乗法が利用されています。
最小二乗法や線形回帰、ラッソ回帰、リッジ回帰、ElasticNet回帰などに関して詳しく知りたい方は、その前後の一連の流れもありますので、Aidemyさんを受講されたり、テキストで勉強される事をお勧めします。

今回採用した線形回帰モデルの各列の偏相関係数はこのようになりました。最後の-13.65…は切片となります。
計算式としては、予測HR数 = -170.39..*wOBA + (-114.70..)*Barrel%+・・・+145.66…*SLG+(-13.65…)です。

作成した線形回帰モデルに2021年の特徴量(各カラム)のデータを渡して、予測数値を可視化します。
また、精度を比較するために、2021年の実際のホームラン数ランキング上位10人と予測ホームラン数ランキング上位10人を表示します。

ご覧の通り上位10名には同じような選手が表示され、また、ホームラン数も似たような数字を予測しております。
但し、上位10名のみでは下の選手まで正確に精度をだせているのかがわからないので、全体が可視化できるように図と表にします。


上から下までほぼ正確に予測できていることが分かりましたので、この線形回帰モデルを採用することを決定し、次にステップ2に進みます。
ステップ2 全選手のクラスタリング
クラスタリングを行うためのデータ前処理を行っていきます。
前処理で行う処理は以下の通りです。
・statisitics変数のDataFrameに入っているデータの内、”Name","HR","year","HR/AB","PA"の特徴量を除いたデータをstatistics_grouping変数に代入します。
・年度別によって重複している選手が存在するので、特徴量の平均をとって、重複している選手を1つに統合します。同じ選手の抽出方法として、”playerid"を使用します。また、統合した後に、”playerid"の列は削除します。その新しいデータをgroupby_sameplayers変数に代入します。

・全データを特徴量毎に標準化し、相関行列を作成します。
相関行列のヒートマップが下記の通りとなります。


・相関行列を固有値と固有ベクトルに分解します。また、固有値と固有ベクトルは特徴量の数の分だけ取得できますが、大きな固有値に対応する固有ベクトルほど元の行列の構成に深く関わっているという性質を持ちます。
その性質を利用して14個の固有値の内、特に大きい値を示す上位2つの固有値を第一主成分、第二主成分として抽出します。
ちなみに、これは何をやっているのかというと「主成分分析」と呼び、データの要約を行なっています。主成分分析の代表例として、身長と体重(二次元のデータ)から肥満度を示すBMI(一次元のデータ)への変換等があります。つまり、身長と体重をBMIに変換することで、なるべく少ない特徴量、かつ、なるべく情報を落とすことなく、ある人の特徴を表すことができます。
それと同じ原理で、選手を表す14個の特徴量を最も深く表す2つの特徴量(固有値)に変換する作業を行なっておりました。

・前処理の最後として、14次元の特徴量を持つ変数groupingxのデータ群を、第一主成分と第二主成分の2次元の特徴量のみを持つ新しいデータ群として変数X_pcaに代入します。

ここから2次元の特徴量データ群を利用して、全選手をクラスター分けしていきます。大体一つのクラスターに15〜20人の選手が振り分けられるのが理想的なので、30個のクラスターに分けていきます。

その結果、元々の散布図に対して、色分けされているのがクラスタリングされた散布図です。

ここからはクラスタリングされた結果を表にしてみていきます。
まずは各クラスターに属する選手数。少しばらつきはありますが、良い感じに振り分けられました。この時点では、各クラスターの特徴は全く分かりません。

次に、平均ホームラン数が多い選手のランキングとその選手が属するクラスター番号を可視化していきます。見た感じでは、クラスター12,5,21,8番にホームランヒッターが多そうです。
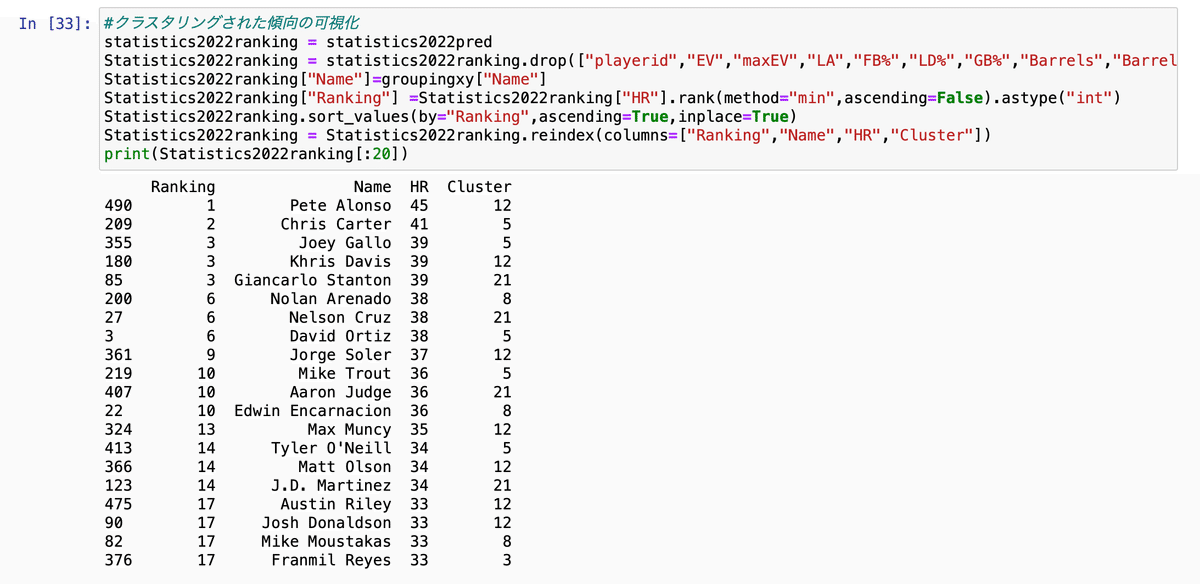
ちなみに、大谷翔平選手はクラスター21番に!これは2022年の予想ホームラン数に期待がもてます。

クラスター21番に属する他の選手も気になったので、こちらも表に。
大物たちが揃うグループに入っておりました。

それでは、クラスタリングも無事完了しましたので、ステップ3に移っていきます。
ステップ3 Random.normal関数を使用して確率変数を振り分ける
このステップでは、以下2つの処理を行います。
1. クラスター毎の平均と標準偏差を計算する。
2.各クラスターに属する選手の2022年の特徴量の値は、クラスター毎の確率分布に従うことにする。
まずは、クラスター毎の平均を計算します。


次に標準偏差の計算を行います。
また、クラスター24番は選手が1人しか属していなかったため、標準偏差がとれませんでした。しかしそのままではRandom.normal関数が利用できないので、手動で標準偏差を0で埋めます。


最後に各選手が属するクラスターの平均・標準偏差に従う確率変数をrandom.normal関数で算出し、その数値のデータ群をdf_dist変数に代入しました。これで2022年のホームラン数を予想する準備が整いました。
ちなみに、平均・標準偏差・確率変数・正規分布に関して詳しく知りたい方は、統計学の勉強されることをお勧めします。

E.結論
最後のステップとして、先ほどのステップで算出したdf_dist変数を線形回帰モデルに渡します。

その結果!!

なんと大谷翔平選手はホームラン数45本で2位に!
確率変数を算出するのは1回勝負と決めていたので、かなり嬉しい結果に。
F.おわりに
FangraphやSteamerなど同じように選手の成績を予想するサイトは、より細かく、より精密に分析を行なっていることは間違いありませんが、だからと言って、FangraphやSteamerの方が2022年の予想が確実に当たるのかというと、それは分からないと思います。
つまり、データの分析をする能力や数字を扱うスキルは確かに重要ですが、一番重要なのは、まずは、何を目的として、その目的を達成する手段としてデータをどう扱うのかという目的意識を持つことなのではないかと感じました。そしてその目的と手段が理に適っていれば、仮に他の機械学習モデルより精密さは欠けていたとしても、一つの正解なのではないかなと思います。
しかし、自分の機械学習モデルは、年齢による成績の低下など、細かい要素が全く考慮されていないので、かなり初心者的なモデルであり、改善点はまだまだたくさんあります。
今回の経験を皮切りに更なるレベルアップを目指していきたいと思います。
Googleさんなどのハイテク企業がどんどんと新しいAIモデルを開発しておりますが、いつかはその内部の仕組みが分かるレベルになれたら良いなと思います。
それでは最後までありがとうございました!
この記事が気に入ったらサポートをしてみませんか?