Ord10まで行った今こそ振り返り!~Ord5編~

ここまで復習している間にもう復習したことを忘れている…。意識して技術を使わないと忘れますが、日常でそれをやるのは難しいですね。どういう表現がしたいからこの技術を使おう!というのが、学んだ技術と合致しないとなかなか使う機会は訪れない…。
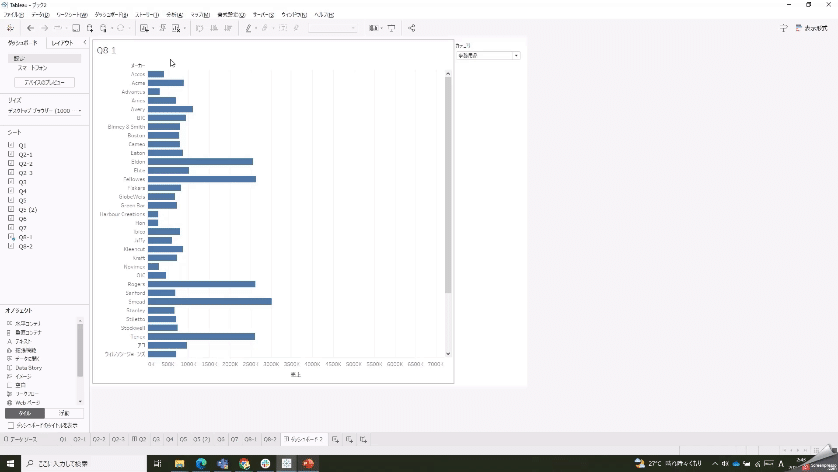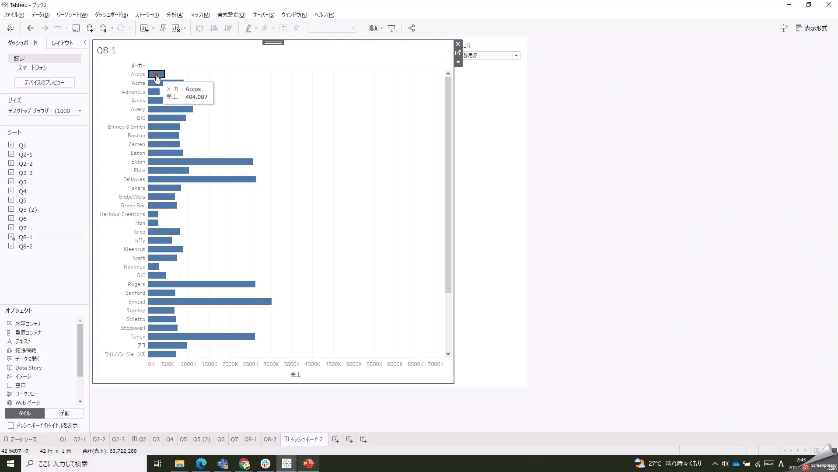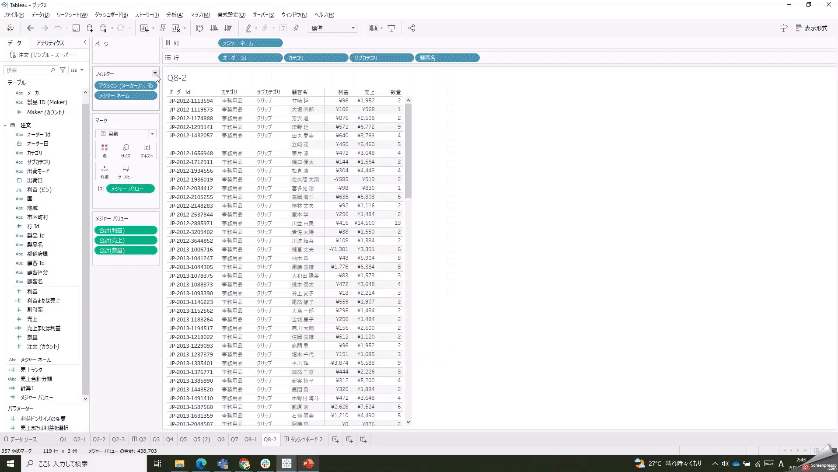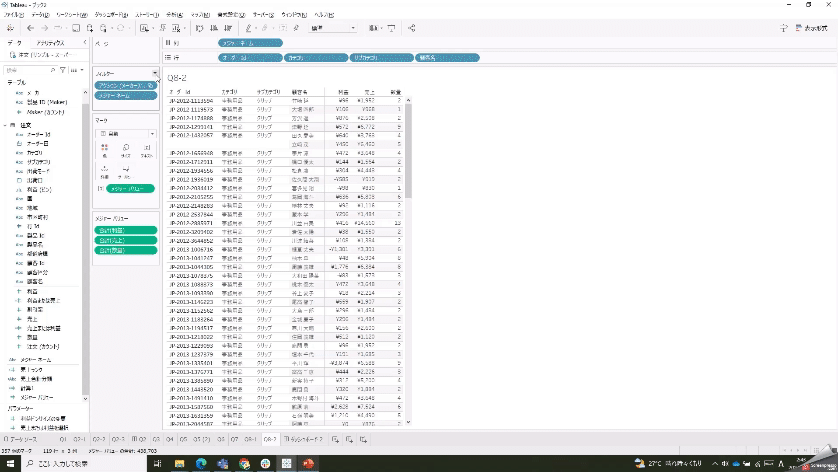
Q1
2000万以上・1000万以上・500万以上・500万未満(問題は"以下"になっていますが)にカッチリ分けるには、ぱっと見ステップドカラーが使えそうなのですが、ステップドカラーの「<<詳細」から最小・最大を決めてよしなに値を分けてカラーをつけてくれるもので、問題のようにキレイな数値では分けられません。逆に言うと、その最大・最小さえ変えれば柔軟にカラー分けしてくれる利便性があります。
今回のようにキレイに分けるには無理やり計算式で分けてやるしかありませんが、計算式はこれらの分類を変えるメンテナンスが都度発生する可能性があります。
IF SUM([売上]) >= 20000000 THEN "2000万円以上"
ELSEIF SUM([売上]) >= 10000000 THEN "1000万円以上"
ELSEIF SUM([売上]) >= 5000000 THEN "500万円以上"
ELSE "500万円未満" END非集計(行レベル)計算・集計計算・ディメンションの集計?
上記で作成した計算式は処理結果としては文字列を返しているのですが、その結果はSUM([売上])という集計によって返されたものなので、ディメンションに移動することはできません。なので、MIN([地域]) も結果は「関西地方」という文字列が返ってきますが、集計の結果なのでメジャー扱いであってディメンションには移動できません。
集計計算は以下の画像に入っているもの全部です。

列・行シェルフにドラッグした際に「集計(計算1)」といった感じで表示される場合があります。集計と合計は違います。「元々集計計算されています」という意味で、どう集計計算されたものかは計算式を見ないと分かりません。計算1の中身はたとえば「SUM([売上])」という計算式です。

Q2
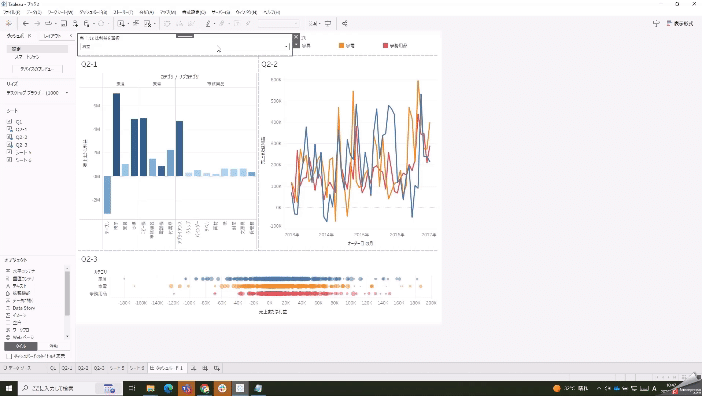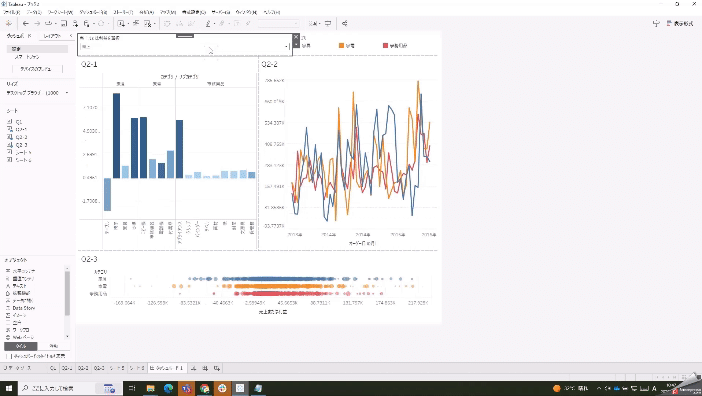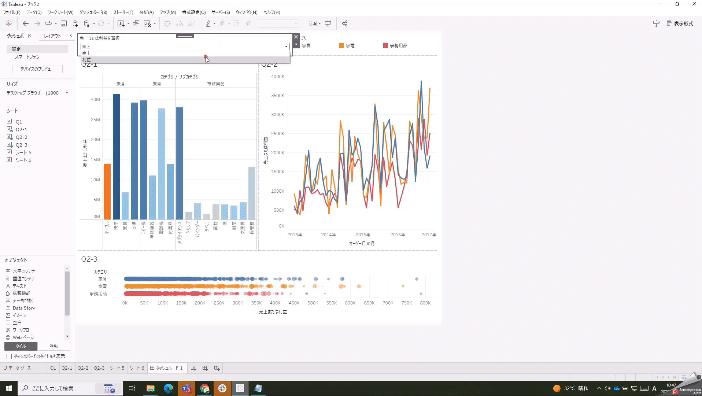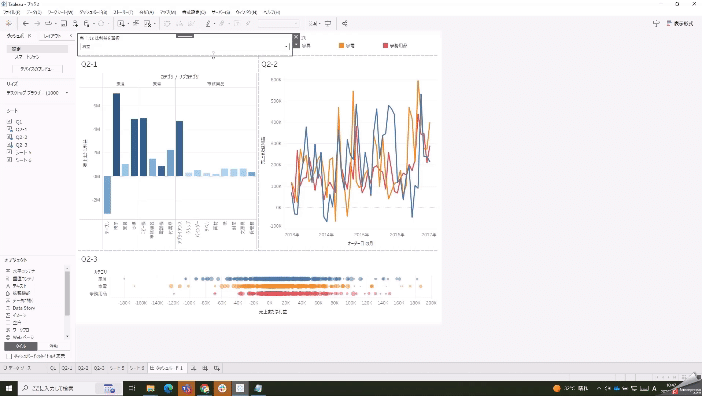
「売上」と「利益」をボタンを押して切り替えたいという問題です。
パラメータを使って切り替えます。

このパラメータに連動して表示を切り替えるには、パラメータを取り入れた計算式を用意します。作成した計算式を行シェルフに持っていきます。
IIF([売上または利益を選択]=1,[売上],[利益])問題のダッシュボードにあるグラフ3つに適用すると…
Q3
価格帯 ⇒ ビン!
対象のメジャー⇒作成⇒ビン。分布の中の頻度を見る際に便利!
また、ビンはパラメータと組み合わせることで、ダッシュボードを見ている人が自由にビンのサイズを変えられます。
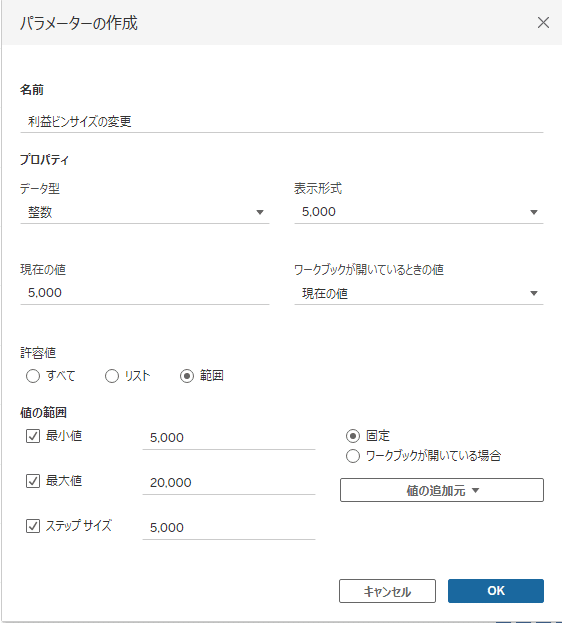
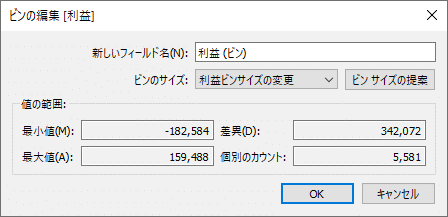
上記のように作成したパラメータをビンのサイズに組み込むと…

Q4
傾向を見るときは散布図×アナリティクスの傾向線!
(傾向が有意かどうかは今回p値やR2値は無視するので気にしないですが、業務を意識するなら見るべきではありますね)
Q5
「合計に対する割合」の使い方を注意せよ!という問題。
割合が何を全体として見ているか(見たいか)を理解しておく必要がある。
カテゴリごとに割合を出せれば良い場合は「表(横)」または「セル」で見ると要件を満たせる(A)。全カテゴリの中で割合が高いカテゴリと顧客区分の組み合わせを見たければ「テーブル」または「表(下)」を見れば割合計算の対象は全カテゴリになる(B)
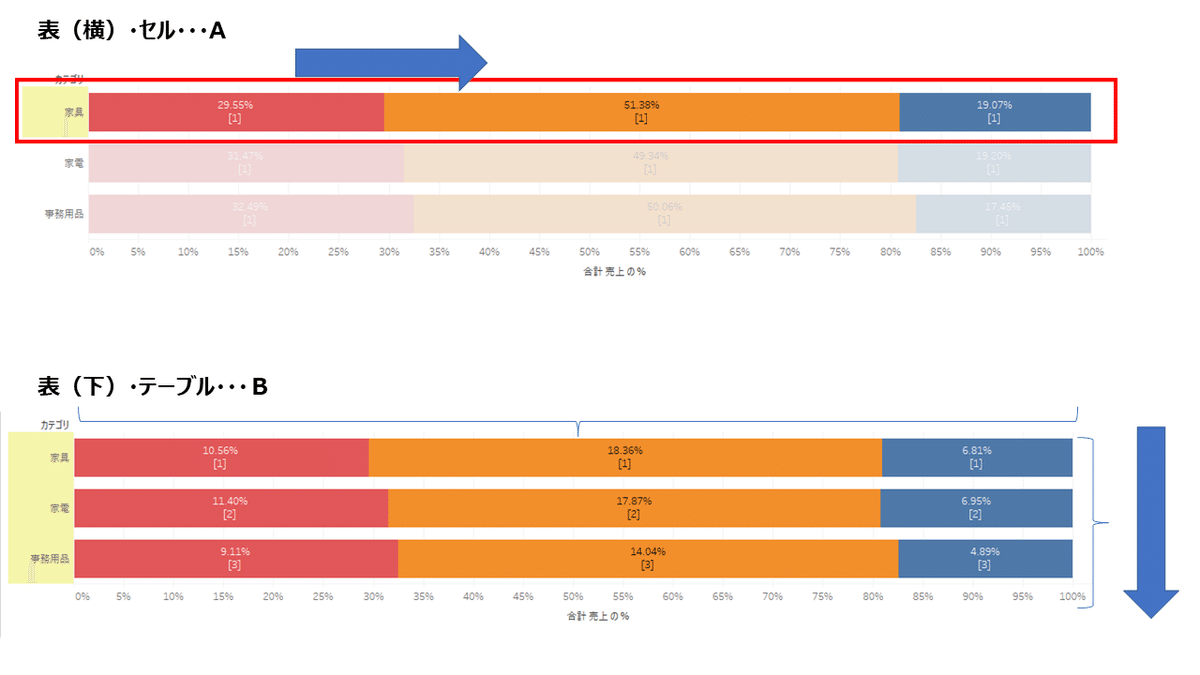
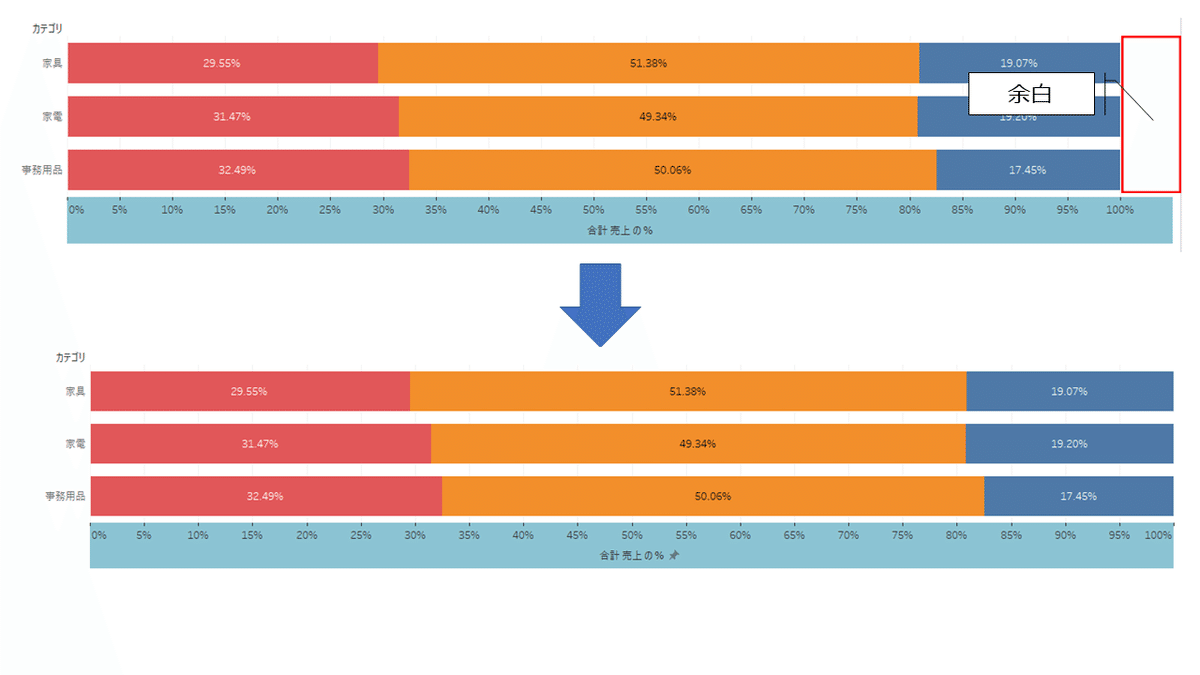
設問は、「セル」が一つ(1次元の表ということ)だったのでシンプルだが、たとえば列にカテゴリ×割合を地域ごとに見るとセルが地域単位分増えるので、より合計に対する割合の全体がどこを指しているかを注意する必要がある。なお、どの単位で見ているかの参考値として左下に合計の%が表示されている。例えば以下の「表(横)」のパターンの場合、800.00%と表示されるが、これは行の地方につき100%が8つあるからです。
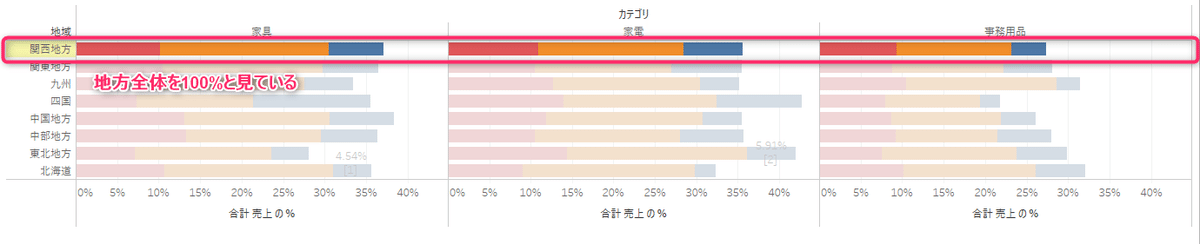



合計に対する割合を見る場合は、「表計算の編集」から何を全体と見ているかを確認すると間違いはないかと思います。
本題と逸れるが、以下図は一見100%まで表示されていますが、右端少し余白があります。これは、軸が105%をMAXとしているからです。これを右端までびっちり詰める場合は、軸の編集で「自動」⇒「固定」にして最大値を1.00にすると解決です。
Q6
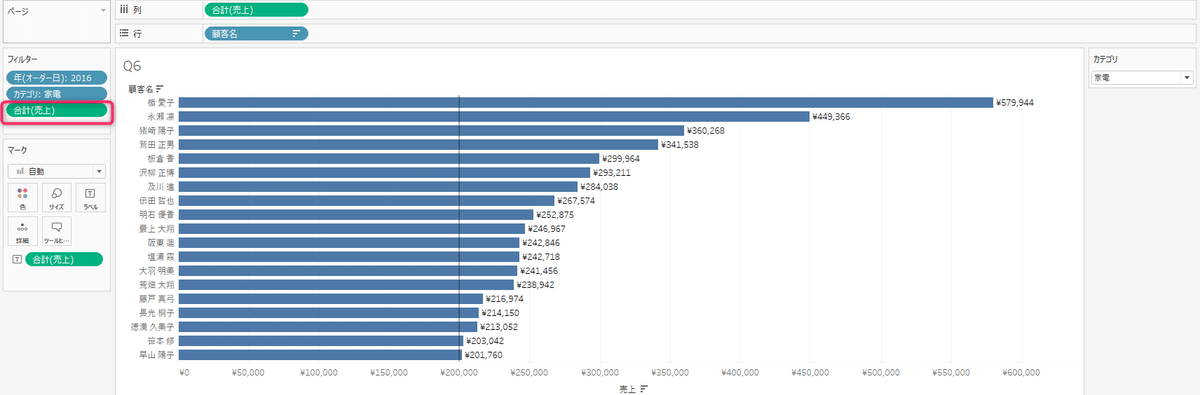
問題自体は難しくないですが、フィルターの扱いに注意点があります。
■ 青色(ディメンション)フィルター
これらが複数横並びになっている時、これらは条件を順番に絞られているわけではなく、横並びにそれぞれが条件に合致するデータを表示しているイメージです。行シェルフに「顧客名」列シェルフに「合計(売上)」があります。フィルターは次のように設定します。
・オーダー日(2016年)
・カテゴリ
・顧客名(条件で売上>=200,000)
最後の顧客名のフィルターは「2016年における売上200000円以上」というわけではない。あくまで「全体で見て200000円以上の売上を持つ顧客」の、2016年における売上を見ている。また、顧客の売上条件にカテゴリ別で見た場合も売上にはなっていない。
もし、「2016年における」「あるカテゴリにおける」売上が200,000円以上の顧客に絞る場合、コンテキストフィルターを用いて前提条件を作る必要がある。

コンテキストに追加しない場合、別のやり方があります。今回、売上が200,000円以上に絞りたいわけなので、メジャーの合計(売上)をフィルターに持っていき、200,000円以上にすればよいです。
メジャーフィルターは、ディメンションで集計された後の値になるためです(実質的にコンテキストに追加されている)。
Q7
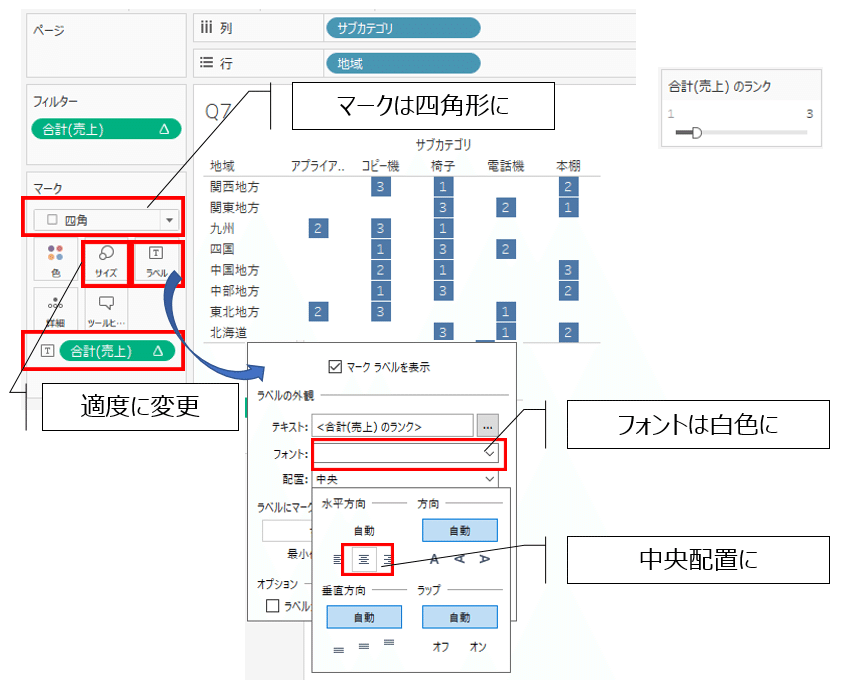
問題自体は力ずくでやれます。が、トップ3に全部入っているかどうかという歯抜けを探す上ではビジュアルでパッと分かる方が良い、ということでKTさんが「後のZENマスターのビジュアライゼーション」を紹介されていました。ただ、作り方を教えてくれませんでしたw
ということで、改めて再現方法を以下に整理します。
Q8
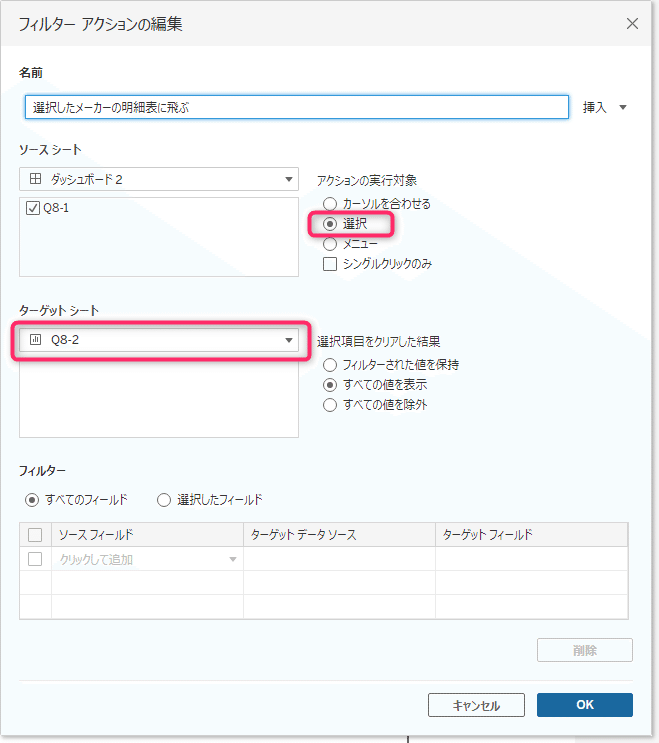
フィルターアクションはダッシュボード内のシートだけでなく、ワークシートにも飛ばせますよ、という問題。アクションの対象になったシートに自動でフィルターが作成されるのは便利ですよね。
それよりも、個人的にKTさんのここの解説で気になったのが「明細表」の作り方なのですよね…。明細形式で「売上」や「利益」を表示させる方法が分からなかったのですが、以下が参考になりました!「表示形式」から明細表に使いたい項目をドラッグ&ドロップする方法が参考になりました。
Q9
そもそも移動平均って…?はこちらを見て学びました。今回言いたかったことは時系列データの場合に簡易表計算から「移動平均」を求められるということなるのでしょうか…。
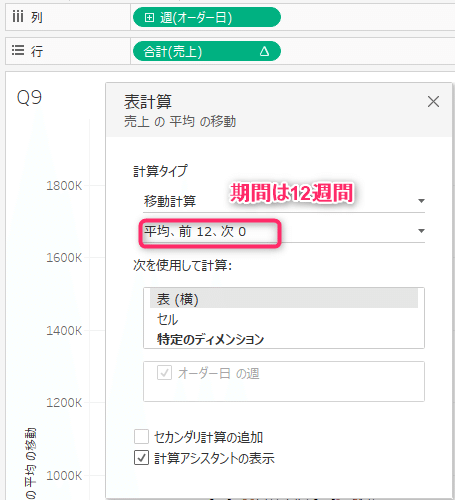
KTさん動画で移動平均の大きい月はどこかを探すのに、かなりの高度テクニック事例を共有されていました。
① 計算フィールドで以下を作成し、「色」に突っ込みます
DATETPART('month', [オーダー日])② メジャーを「中央値」に変更します。
③ 不連続にします。
これで最も頂点に達しているタイミングが多い月が色で分かりやすくなるのですが、なぜただのオーダー月だといびつなグラフになるのでしょうか。

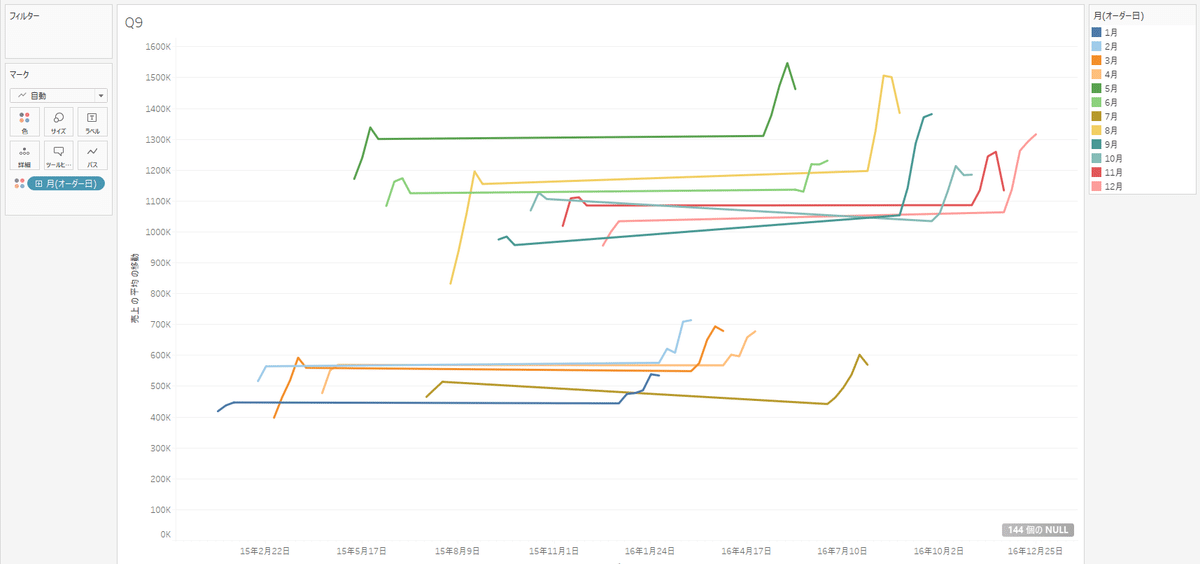
<ここからはあくまでこうなのでは??という推測と、途中で理解するのを投げ出しています。本旨じゃないので許して>
②について特に気になるのは
1. なぜ間は直線になっているのか
2. なぜ2014年以前はNULLになるのか
1点目については、あくまで「月」で見ているので、2015年の1月の移動平均を算出後、次の移動平均を求めるのは2016年の1月になるので、間が飛ぶからだと思います。
2点目については…どうしてなのでしょうかね。2013年はそもそも「前」に指定している期間のデータがないので分かるのですが、2014年は4月以降前年のデータがあるはずで、平均を出せるはずなのですよね…。
Q10
売上200,000円を超過したデータがいくつあるかをシートを見て分かるようにする問題。ランクを行ラベルに表示すれば良いので、合計(売上)の簡易表計算をランクにして不連続にすればよい。

Q11
①明細単位でサブカテゴリごとの売上で、外れ値を除いて最も売上が高いサブカテゴリはどれか
明細単位⇒売上をディメンションで見る。
外れ値⇒箱ひげ図で見る(アナリティクスペインか箱ひげ図を放り込み)
箱ひげ図のレンジで最も高い売上があるサブカテゴリが、「外れ値を除く」最も売上が高いものとなる。
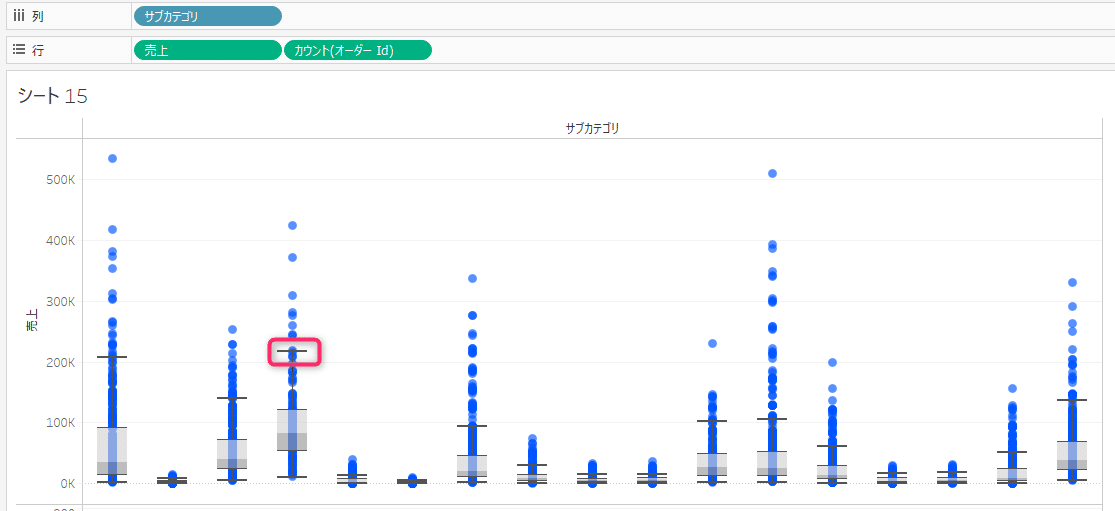
②オーダー回数が他と比べて多いか
オーダーIDのカウントだが、普通のカウントなのか、個別カウントなのかどちらを選ぶべきか、というところ。両者の違いは「重複データ」を数えるかどうかで、結論は重複をカウントしない「個別カウント」なのですが、なぜそうなるのか。例えば、テーブルのオーダーIDのカウント数に注目します。
個別のカウント⇒140件
カウント⇒142件
この2件の差は、どこから来るのでしょうか。サブカテゴリだけで見るとややこしいのですが、同じサブカテゴリでも製品名が違うものを1つのオーダーIDで複数件購入しているケースがあります。テーブルの場合、1オーダーIDで、サブカテゴリがテーブルで2つ以上製品を購入しているのは珍しいのですが、そうしたオーダーIDが2件あるわけですね。
なので、サブカテゴリ単位でカウントしたい場合、製品名の相違により同じオーダーIDでサブカテゴリを複数回カウントしないようにするには「個別のカウント」をする必要があります。"オーダー回数"を見たいので1オーダーで複数のサブカテゴリがあった時は1回しか数えてはならないので、今回は個別カウントが正しいということになりますね。
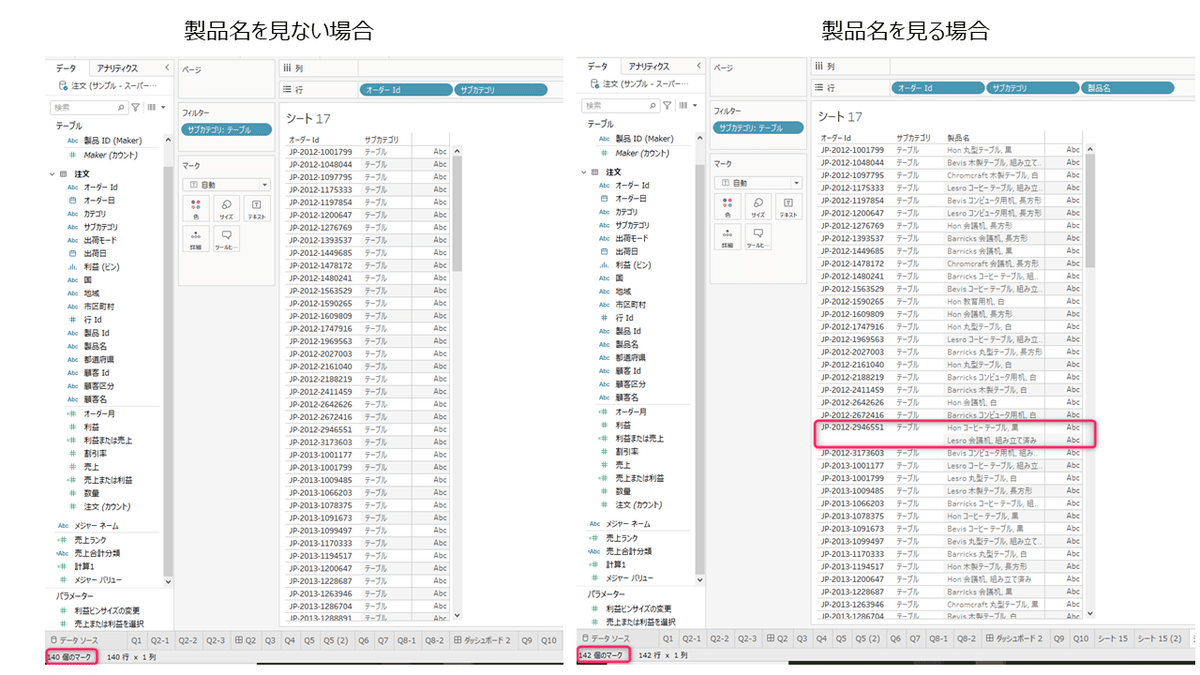
演習では全てしれっと個別カウントをしていますが、どんな数をカウントしたいかの目的を持っておくことと、個別カウントで何が排除されるかは元のテーブルをきっちり把握しておく必要がありますね。
Q12
パラメータと計算フィールドを上手く使い、計算シミュレーションを行う。
カテゴリごとでも見たいので、カテゴリの変化に連動して売上シミュレーションを行う。
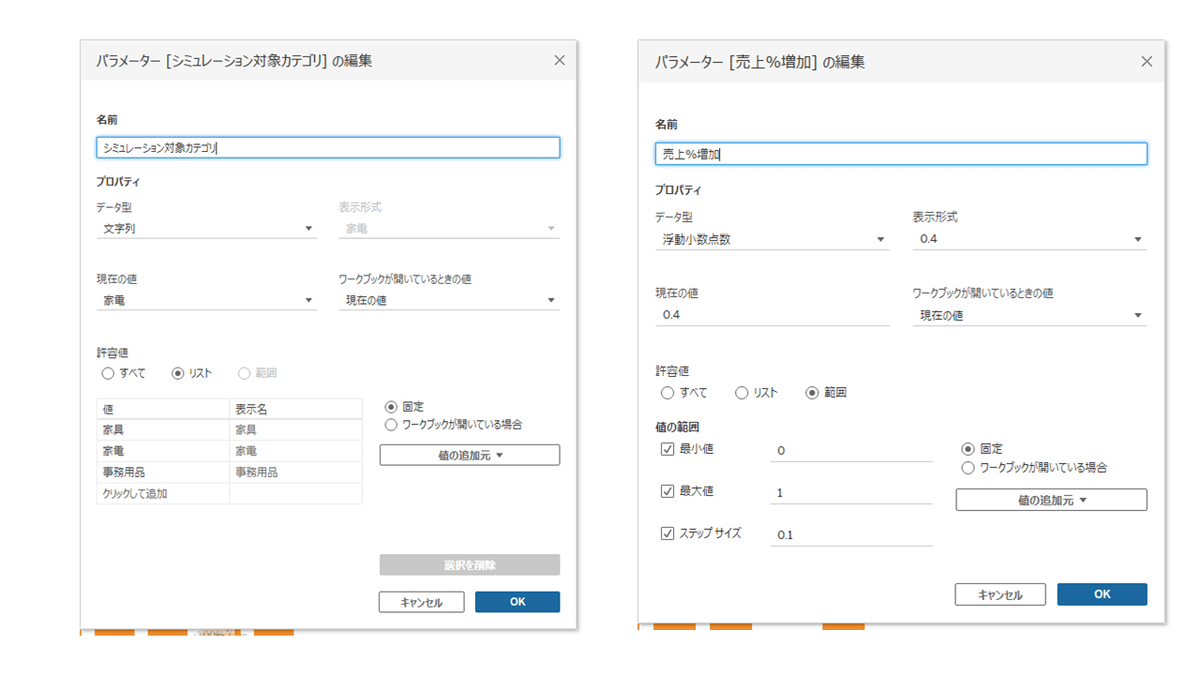
選択したカテゴリと、増加パーセンテージによって売上計算を変動させるため、以下の計算フィールド(売上%増加)を作成し、行シェルフに入れます。
IIF([カテゴリ]=[シミュレーション対象カテゴリ],[売上]*(1+[パラメーター].[売上%増加]),[売上])次に、増加パーセンテージを増やした時に元の売上の1.1倍を超えているかどうかを視覚化するためにリファレンスラインの分布をセル単位で行います。
なお、行シェルフには上記で作成したパラメータの影響を受ける売上メジャーしか入れていない。リファレンスラインに入れる売上(100%~110%幅)はパラメータの影響を受けない売上メジャーである必要があるが、リファレンスラインに参照されるにはシート上のどこかに普通の売上を入れておく必要がある。なのでマークシェルフに普通の売上メジャーを入れておく。
(リファレンスラインに、上記で作成した売上を設定してしまうと、シミュレーションで売上を増やす都度リファレンスラインの位置も同じく上にズレるのでいつまでたっても売上の1.1倍を超過するのがいつかがわからなくなる)
リファレンスラインの設定は以下。


なお、色は「SUM([売上%増加])>SUM([売上])*1.1」に設定しているが、偽のみの場合と真偽、真のみでそれぞれ色がバラバラにならないよう、真偽が表示されている状態で色の編集を行い色を設定しておくと良かったです。
Q13
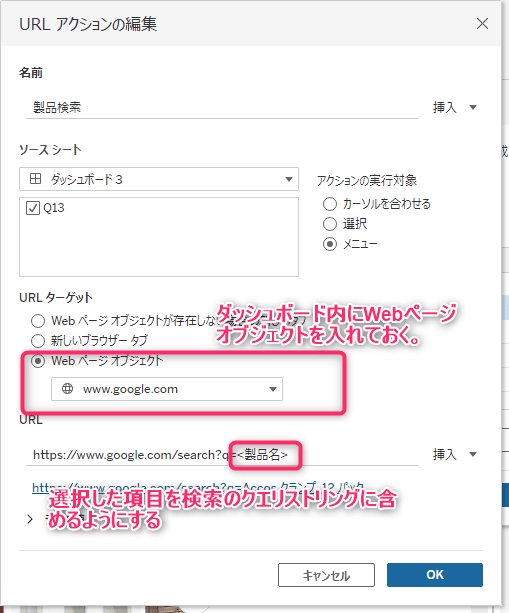
アクションを使うと選択した項目でWeb検索ができる
ダッシュボード内にWebページオブジェクトを入れられる。
1については、選択した項目をクエリストリングに含められるためです。
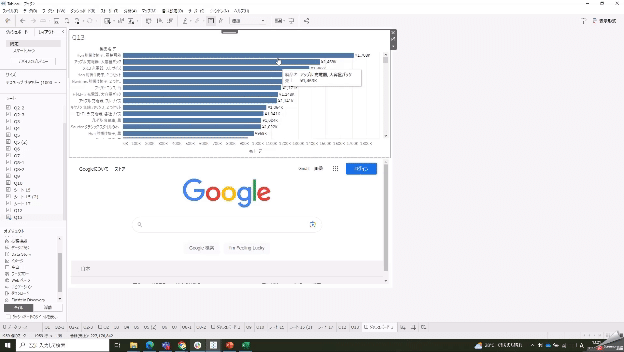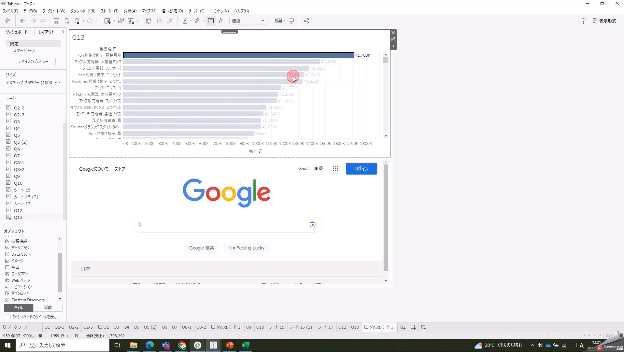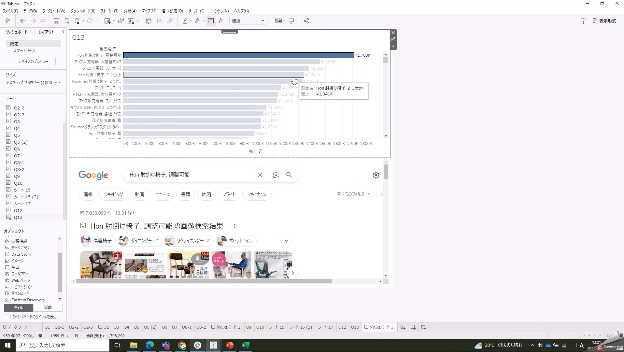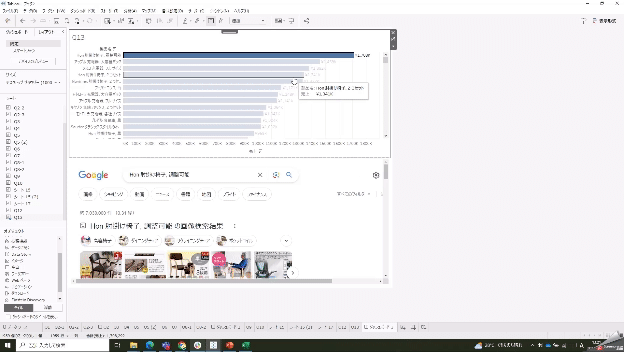
このテクニックを業務シーンで活用することを想定する場合、たとえば社員名のような列があれば、それをクリックしたときに会社の社員検索データベースで検索してくれるといった使い方ができますね。
Q14
アナリティクスの「予測」を使えばOKです。この問題で重要なのはどちらかというと「属性」とは何か?だと思います。
「属性」は、持っている情報で特定される場合にのみ使用できます。
下図のような並びでサブカテゴリを属性にした場合、サブカテゴリは家具の中に複数種類あるため、特定できず「*」となっている。

予測インジケーターを「属性」にすることで、元々の予測インジケーターは実績と予測で切り分けられた線から、「出荷モードの属性」としてつなげられた線にすることができる。

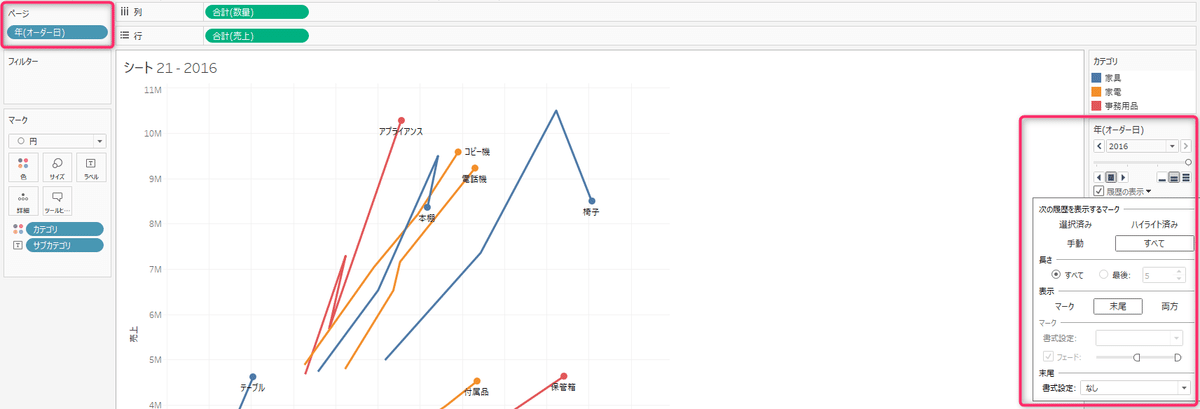
Q15
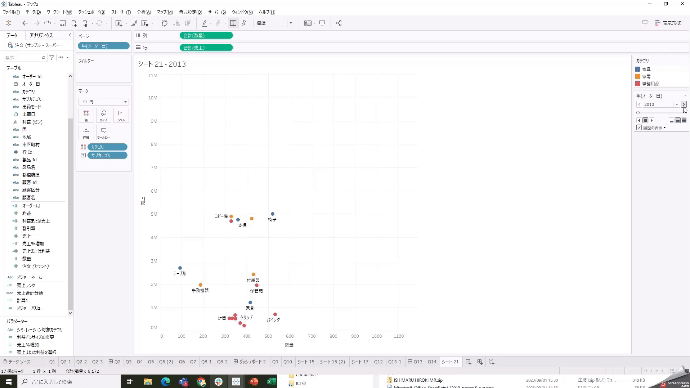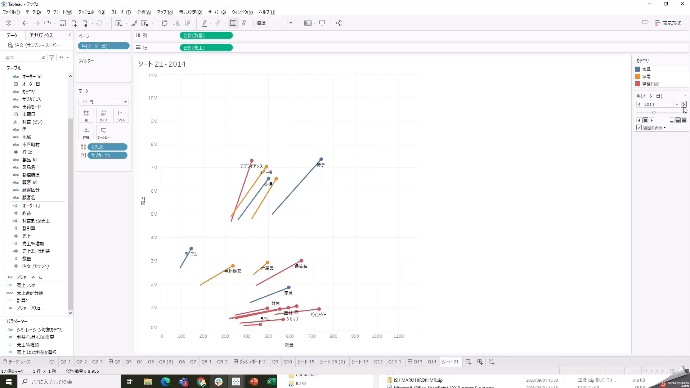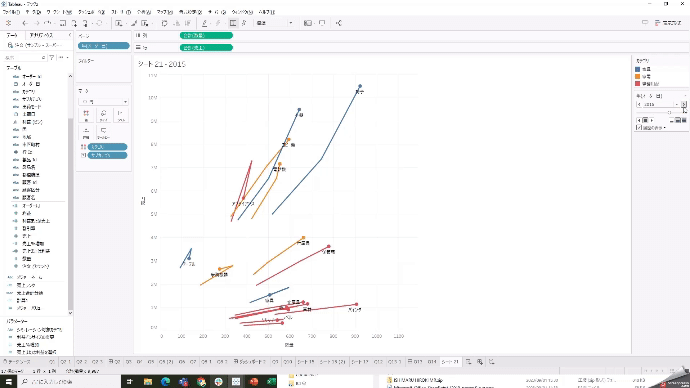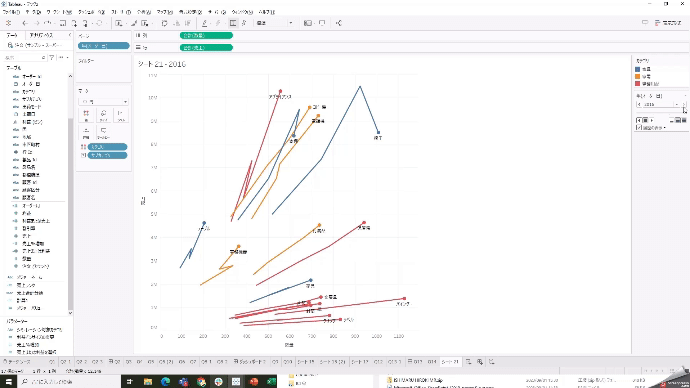
売上と数量が、年毎にどう推移しているかを見たいですが、列シェルフにオーダー年を入れても年毎に区切られるので推移がいまいち見えにくいです。
そこで、どう動いているかが軌跡で見る方法があります。
「オーダー年」を左上のページシェルフに入れて、履歴の表示をするようにすれば、推移が見やすくなります。
この記事が気に入ったらサポートをしてみませんか?