Endnote desktopを使った重複除去のTips

SRを行う際の検索は,報告バイアスのリスクを低減し,できるだけ多くの関連する情報を特定するために,できるだけ広範囲に行うことが言われています。
The search for studies in a Cochrane Review should be as extensive as possible in order to reduce the risk of reporting bias and to identify as much relevant evidence as possible (see MECIR Box 4.3.a).
access 2022-12-11
Cochrane handbook for systematic reviews of interventionsでは,一般的に臨床試験の検索には"CENTRAL", "MEDLINE", "EMBASE"の3つが最も重要な情報源と挙げられています。
CENTRALの情報にはMEDLINE由来のものもありますし,EMBASE由来ものものもあります(ct.gov,cinahl由来も)。本学はEMBASEの契約がないので(MEDLINEもPubMedかEbscohost, WOSプラットフォームですが)確認できませんが,おそらくMEDLINEと重複するデータもあると思います。
すくなくともこの3つを検索してみると,かなりの数の文献がそれぞれのDB間で重複していませんか??
その際,スクリーニングに入る前にあらかじめ各データベース間の重複を除去してから作業すると何度も同じ書誌をinclude/excludeの検討に使う必要がなく作業も効率化できます。
PRISMAフローチャートの赤丸の作業です
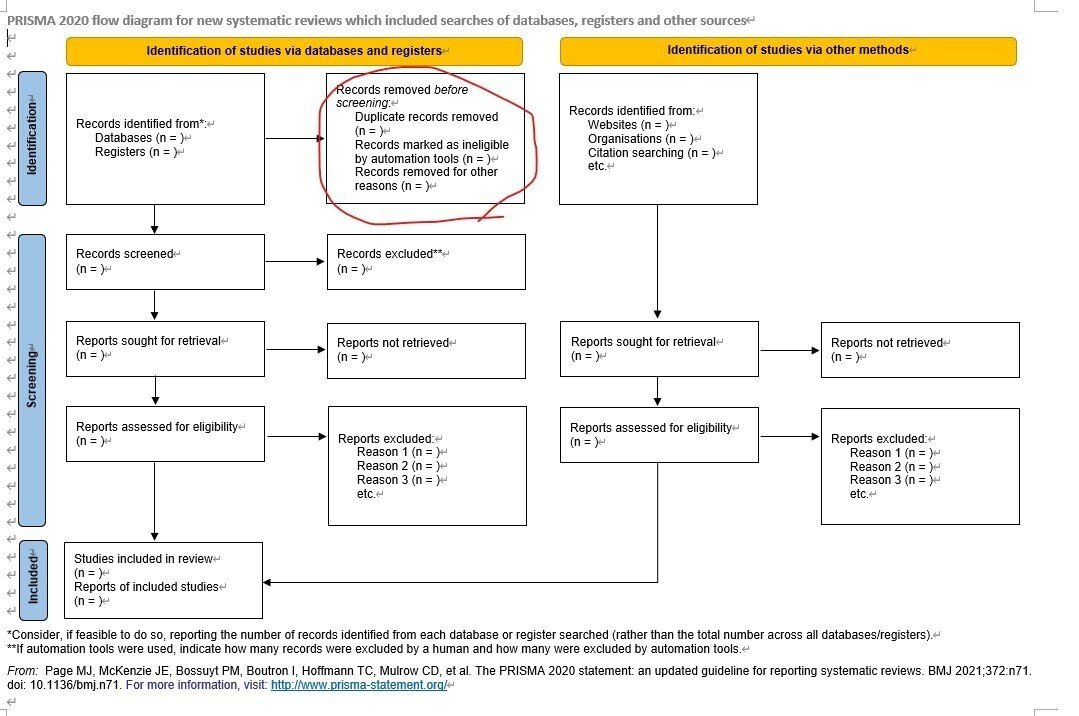
私はこの作業をEndNoteのデスクトップ版を使って行っています。
個人的には下図のように重複候補が左右に並んで表示されるので見やすい気がします。
このあとおそらくタイトル・抄録フィールドを見てのスクリーニングをされるかと思いますが,この際どのデータベースから取り込んだ書誌情報(文献情報)を優先して(スクリーニング用に)残すか意識していますか??
データベースのエクスポートで出力された情報って,そう大きく変わりないのですが,実は細かい違いがありますす。
抄録がAのデータベースにはあるけど,Bにはない。
この場合は明らかにAを残した方がタイトル・抄録フィールドスクリーニングは活用できる情報量が多くなりますよね??


また,WoS等も検索対象に入れた場合,同じ書誌でも他のデータベースの方が割に抄録情報を持っている印象があります。WOSに抄録情報がない場合,
他のデータベースで調べると持っていることも時々あります。
ですので,例えばWeb of Science core collection via web of science, MEDLINE via PubMed, CINAHL with full text via Ebscohost, CENTRAL via the cochrane library, CDSR via the cochrane library, 医中誌Web, ICTRP, CT.gov等を検索した際,重複チェックをする中でどのDB由来の書誌情報を残すか気をつけながら行うと,その後のスクリーニングに役立つかと思います。
シソーラス機能のあるDBだとキーワードやシソーラス情報もエクスポートされるのであれば,もし抄録がなかったり,抄録情報を見ても判断がmaybeになりそうな場合など,その文献につけられているシソーラスを見て判断するということもできたりするかもしれません(シソーラスを活用されている方の場合)
重複除去、単純作業ですがその後のスクリーニングを意識して残す順番を考えながら作業してみてもよいかもしれません。
また,重複除去の方法は論文化する際きちんと報告しましょう。PRISMA-Sの#ITEM16 Deduplicationの項目にも報告について記載例も挙げて示しています。
Deduplication item16
Describe the processes and any software used to deduplicate records from multiple database searches and other information sources.
日本語訳:「PRISMA-S: システマティック・レビューにおける文献検索報告のためのPRISMA声明拡張」の解説と日本語訳
私が重複除去の際気をつけているポイントをメモしました。
この記事が気に入ったらサポートをしてみませんか?