
SRE観点でモニタリングすべきCloud Runの4つのシグナル

はじめに
こんにちは、PharmaX株式会社のエンジニアの尾崎(@FooOzaki)です。
この度、PharmaXでアドベントカレンダーを実施することになり本記事は17日目の記事になります!
PharmaXではインフラ基盤をGoogle Cloud Platform(GCP)上に置いており、Cloud Runをベースとしたインフラアーキテクチャをとっています。
こちらはセルフメディケーション事業の構成ですが、主要サービスのサーバは全てCloud Runで動いています。
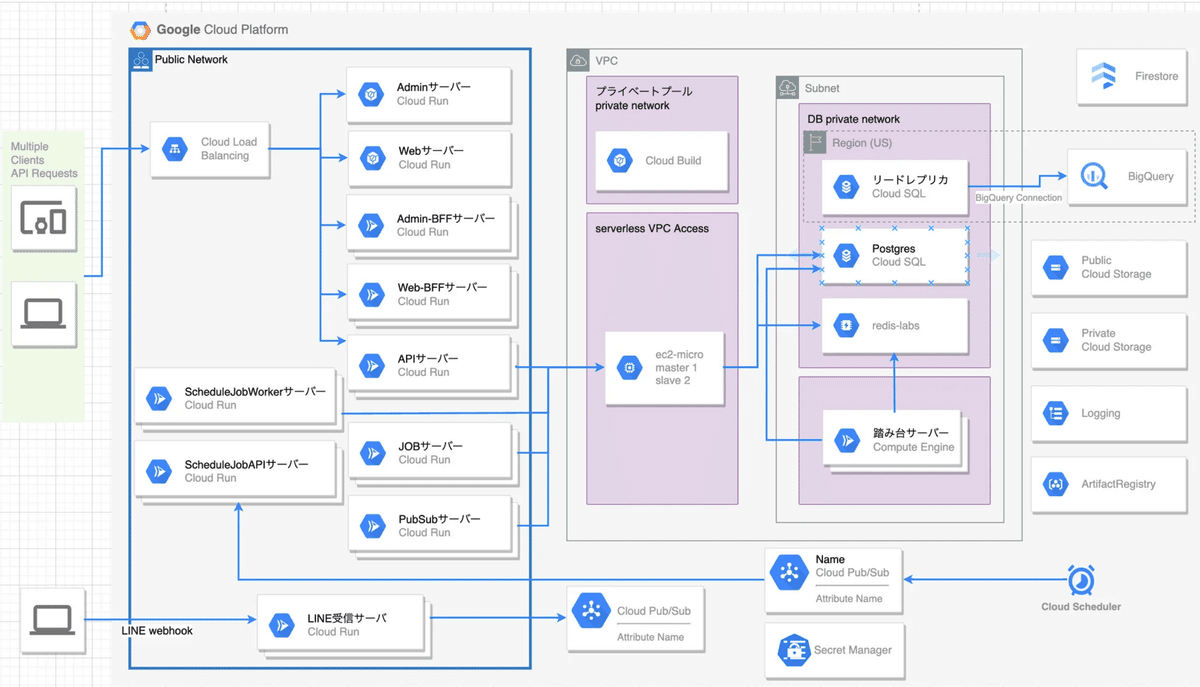
もし構成にご興味がある方はこちらの記事でも全体構成など載せていますので併せて見ていただければと思います。
Rails × GCPの各サービスの紹介
監視面もマネージドなCloud Run
Cloud RunはGoogle Cloud Platform(GCP)のサーバレスサービスで、フルマネージドなコンテナ実行環境ですが、基本的なメトリクスはデフォルトで収集され、Cloud Monitoringへ連携されます。
PharmaXでもCloud Runのインフラメトリクス面はCloud Monitoring単体で運用できています。
この辺もフルマネージドの便利なところです。
ただし、Cloud Runで実行するアプリケーションレイヤーの監視やロギングについてはCloud Loggingへ連携をしたり、アプリケーションの特性に応じて監視・ロギングツールを導入したりは別途検討は必要です。
SREの4つのゴールデンシグナル
Google が提唱するシステム運用の方法論である Site Reliability Engineering (SRE)の中で紹介されている考え方ですが、SREの4つのゴールデンシグナル(注目すべき指標)として以下が定義されています。
レイテンシ
- リクエストの処理にかかる時間トラフィック
- システムに対する要求の負荷エラー
- リクエストの失敗率サチュレーション
- サービスの全体的なキャパシティ

Cloud Runでの4つのゴールデンシグナル監視
先に述べた4つのシグナルはCloud Runのコンソール画面で全部見えます!
なので基本的にはCloud Run単体であればコンソール画面で見えるものを監視しておけばベースは押さえられます。
レイテンシ
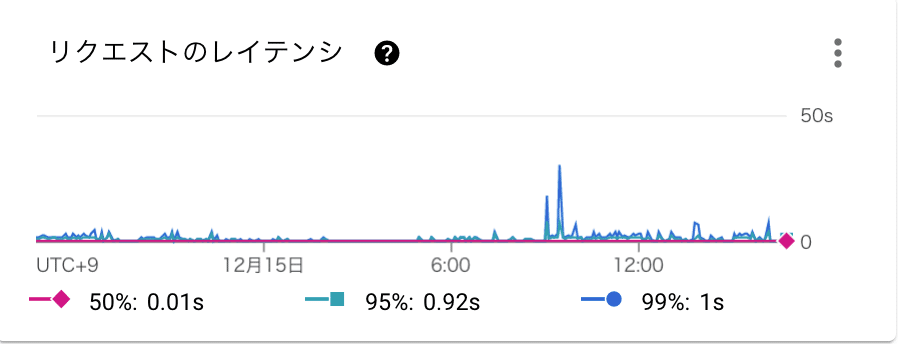
レイテンシについては特に説明することもありませんがデフォルトで取得できます。
レイテンシの目標値を設定したりスパイクを検知することでパフォーマンス改善の土台が作れます。
トラフィック&エラー
Cloud RunでもトラフィックはHTTP通信のリクエスト数、エラーはHTTPステータス(2xx以外)を見れば定量化可能です。
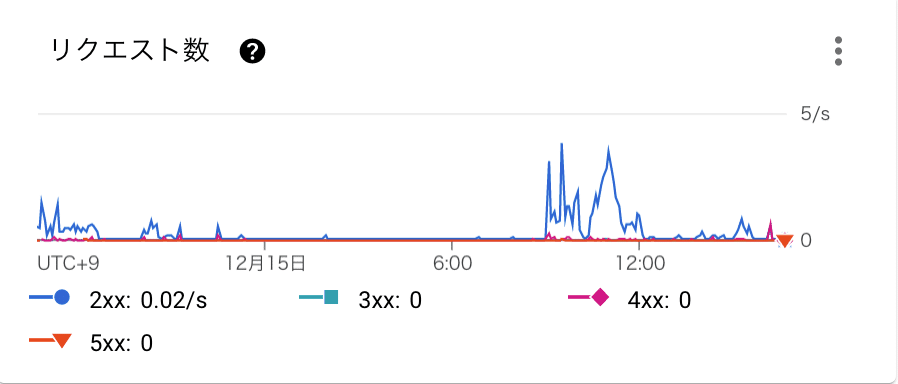
トラフィック観点では入り口のネットワークトラフィック、インスタンスへのリクエスト負荷分散まではCloud Runがフルマネージドに保証してくれます!
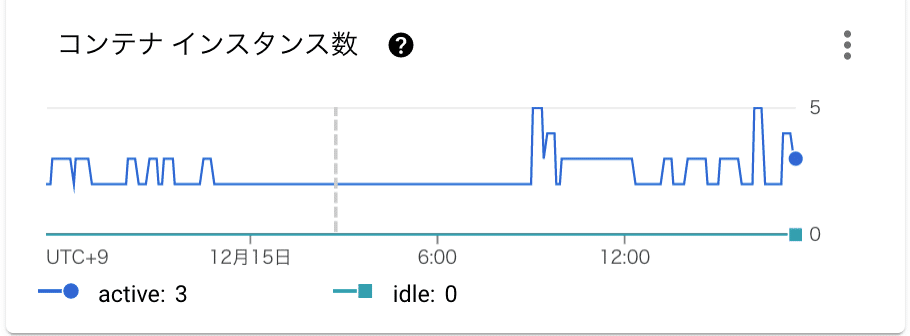
サチュレーション
Cloud Runでのサチュレーションはこのように定義できるかなと思います。
コンテナで利用されているCPUとMemoryの上限に対する割合
インスタンス数のQuota(Cloud Runは最大インスタンス数や最小インスタンス数を設定でき、インスタンス数のスケール制限が可能です)
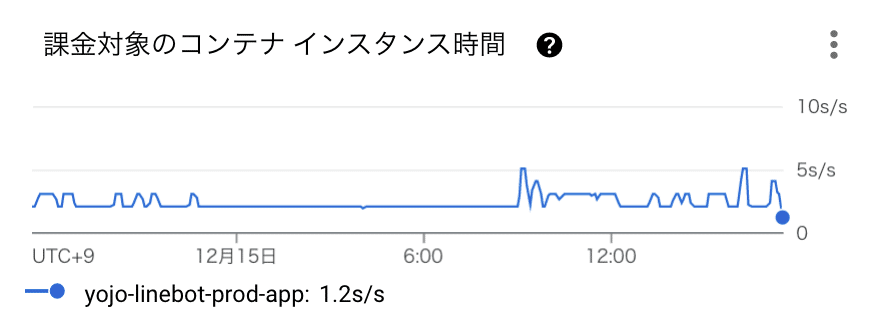
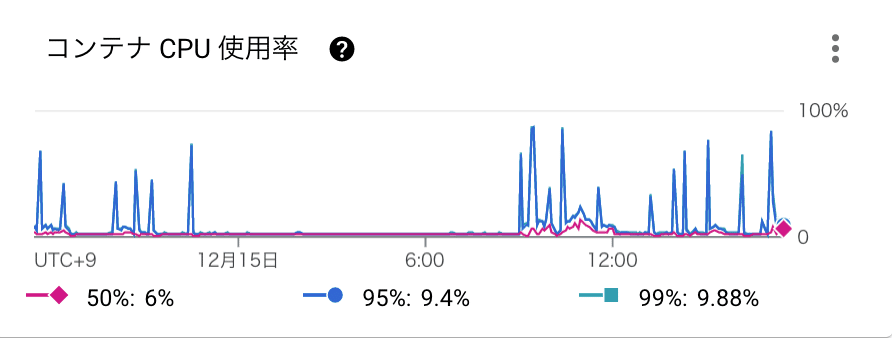
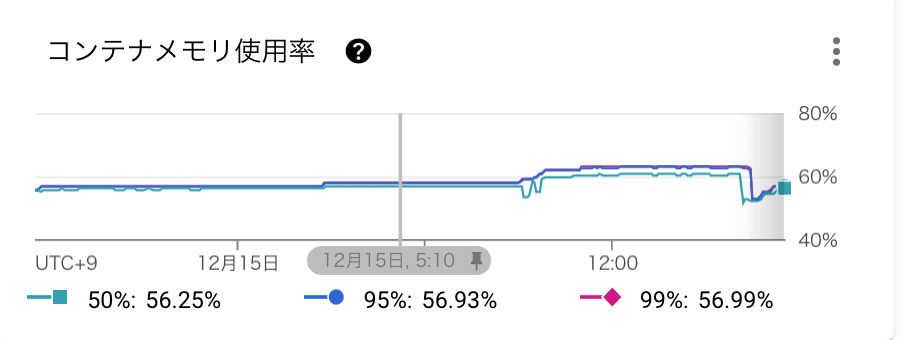
シグナル監視は最初の一歩
Cloud Run運用の要はオートスケール設定です。
個人的には細かい自由度はないなと感じるところではあるのですが、Cloud Runは以下の2点をベースとしたオートスケールの設定しかできません。
CPUの使用率
インスタンスあたりの最大同時リクエスト数
公式ドキュメントにもある通り、コンテナインスタンスのCPU 使用率を60%維持させるようにターゲティングしつつ、同時実行数を超えるリクエストがある場合は、コンテナインスタンスの最大数の範囲で自動スケールするというのが基本的な考え方です。
https://cloud.google.com/run/docs/about-instance-autoscaling?hl=ja
オートスケールについてはサービス特性に合わせて先に紹介したメトリクス を監視しながら是非チューニングをしてみてください!
また、SREの観点ではアラート・通知設定を実施し、他の基盤全体のメトリクスやアプリケーション、データベースのメトリクスと共にボトルネックを特定して改善をしていくことが必要です。
Cloud Monitoringのアラート機能を利用すれば今回ご紹介したメトリクスの閾値を設定し、通知することも簡単にできます。
Cloud Monitoring ダッシュボード
PharmaXではCloud Monitoringのダッシュボード機能を使用して各メトリクスを一覧で可視化しています。
複数サービスをまたがる全体の状況が一目でわかるのでアラートが来た際に一目で状況を把握できるので非常に便利です。
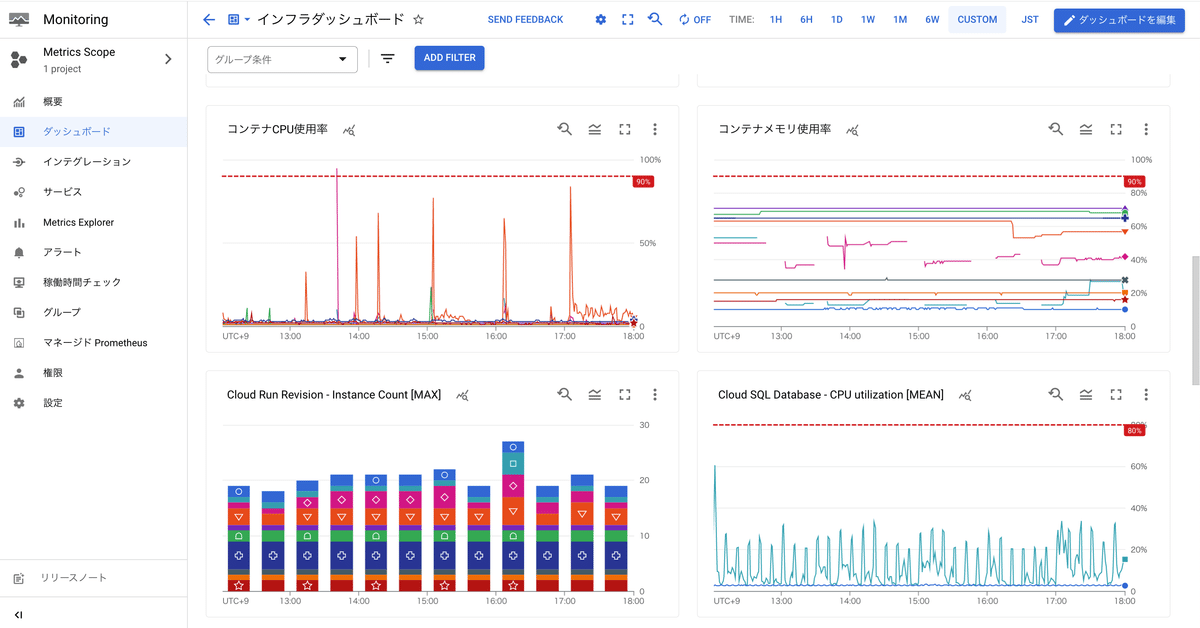
最後に
Cloud Runは今年に入ってからも頻繁に機能追加やアップデートがなされており、SLIとSLOの設定がコンソール画面からできるようになったりしました。
Cloud Runは数あるGCPサービス群の中でもGoogleが力を入れてくれているサービスなので、さらなる利便性向上に期待しつつ運用していきたいと思っています!
PharmaXでは定期的にテックイベントをオンラインで開催しています!
2023年1月は、金融業界・花き業界・薬局業界という異なる業界でDX推進をリードするスタートアップ企業3社が集まり、それぞれのオペレーションを担っているドメインエキスパートとプロダクト開発チームがどのように連携しながらプロダクトや開発組織を作っているのかについてディスカッションします。
ぜひお気軽にご参加ください。