
唇の動きから言葉へ:VSP-LLMの革命的技術解析

デジタル時代において、技術革新は情報の迅速な伝達を推進するだけでなく、人類のコミュニケーションの限界を広げ続けています。最新の開発であるVSP-LLM(Visual Speech Language Model、視覚音声言語モデル)は、この進歩の中で特に目立つ存在です。ビデオ中の人物の唇の動きを分析し、視覚情報をテキスト内容に変換するだけでなく、これらの情報を異なる言語に翻訳することができます。この技術は、Facebookが開発したAV-HuBERTモデルを基にしており、自己監督学習と大規模言語モデル(LLMs)の強力な能力を利用して、視覚音声認識と翻訳の新たな領域を開拓しています。
論文:
視覚音声モデルの自己監督学習
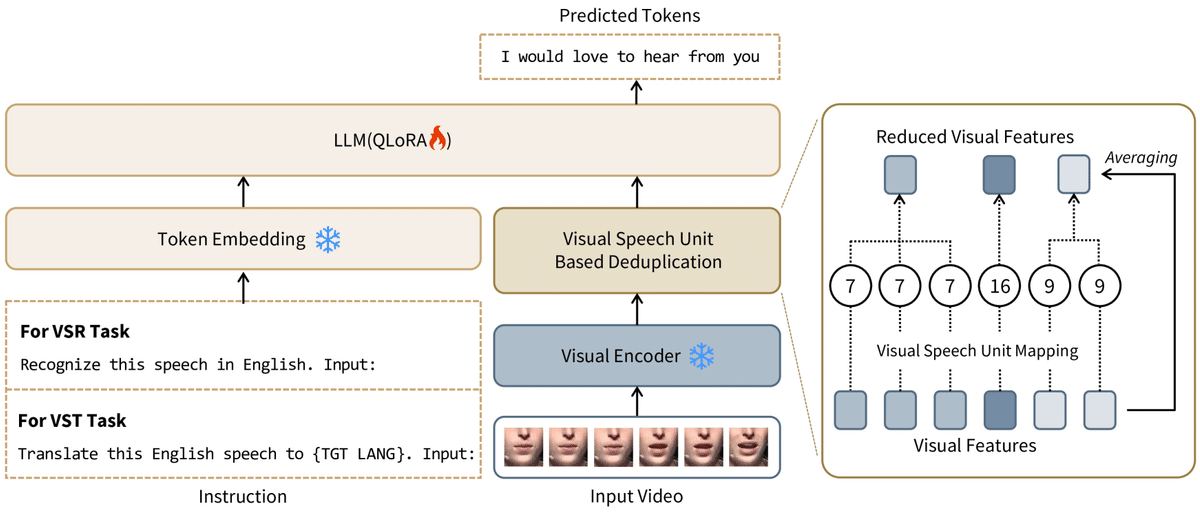
ビデオ処理と唇動作の抽出: VSP-LLMはまず、入力されたビデオデータを前処理し、話者の唇の動きを特に抽出します。これらの動作には、話されている内容が含まれています。
自己監督学習の方法: 自己監督学習を使用して、VSP-LLMは明確なラベル付けされたデータがなくても、自己生成したフィードバックを通じて学習し、唇の動きを認識して言葉を理解することができます。

冗長情報の削除による効率化
視覚音声単位の識別と重複削減: 処理効率を高めるため、VSP-LLMは視覚音声単位(ビデオ中の重要な視覚特徴)を識別し、入力フレームの冗長情報を減らす方法を設計しました。
大規模言語モデルのコンテキストモデリング能力
視覚からテキストへのマッピング: 自己監督視覚音声モデルから抽出された情報は、LLMの入力空間にマッピングされます。これにより、視覚情報が言語モデルが処理できる形式で表現されます。
コンテキスト理解: LLMの強みは、そのコンテキストモデリング能力にあります。VSP-LLMはこの能力を利用して、視覚情報に対応するテキスト内容だけでなく、コンテキスト情報に基づいてこれらの内容を理解し、翻訳することができます。
複数のタスク実行能力
視覚音声認識と翻訳: VSP-LLMは、指示に従って、ビデオ中の唇の動きを具体的なテキストに認識する(視覚音声認識)タスクや、これらの唇の動きを目的言語のテキストに直接翻訳する(視覚音声翻訳)タスクを実行することができます。
計算効率の最適化
低ランクアダプター(LoRA)の使用: トレーニングの計算効率をさらに向上させるために、VSP-LLMは低ランクアダプター技術を採用しています。これは、トレーニングプロセスを最適化し、計算リソースの要求を減らす技術です。
結論
VSP-LLMの開発は、視覚音声認識と翻訳の分野における先進技術を示しており、異なる言語間のコミュニケーションに新たな可能性を提供しています。自己監督学習と大規模言語モデルの強力な機能を組み合わせることで、VSP-LLMは視覚音声データをより正確で効率的に処理することができ、人々のコミュニケーションの新たな視点を開きます。技術がさらに洗練され、応用が拡大するにつれて、VSP-LLMは多くの分野で重要な役割を果たすことが期待されており、特に聴覚障害者のコミュニケーション能力の向上、多言語教育、異文化間交流などの分野での利用が見込まれています。
この記事が気に入ったらサポートをしてみませんか?