
Amazon Redshift Serverlessを使ってみた

はじめに
新卒社員として、10月にAWS Certified Cloud Practitionerを取得しました。
今回、その試験範囲として2023年9月18日から新しく加わったサービスの一つであるAmazon Redshiftが実際どのようにしてデータ分析を可能とするデータベースなのか気になるため、利用して簡易なデータ分析を試してみました。
そして、その中でも、専門知識が少なくても試すことが容易なサーバーレスであるAmazon Redshift Serverlessを扱ってみました。
Amazon Redshift Serverlessとは
まず、Amazon RedshiftのAWS公式の説明は以下の通りです。
Amazon Redshift は、 クラウド内でのフルマネージド型、ペタバイト規模のデータウェアハウスサービスです。
データウェアハウス(DWH)とは、様々なシステムからデータを集積し、整理することのできるデータベースを指します。
そして、Amazon Redshift Serverlessは、「Amazon Redshift」をサーバーレス型で利用できるように2022年7月13日から提供したサービスです。
今回の検証
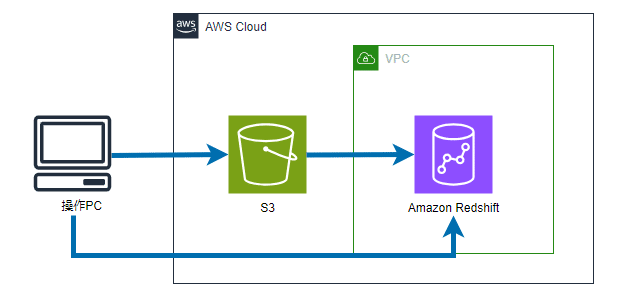
今回はS3でバケットを作成し、その中に使用するデータを格納します。
そして、Redshift上でテーブル作成とS3に格納したデータを挿入したうえでSQL文を実行し、要求通りにデータが出力されるかを確認します。
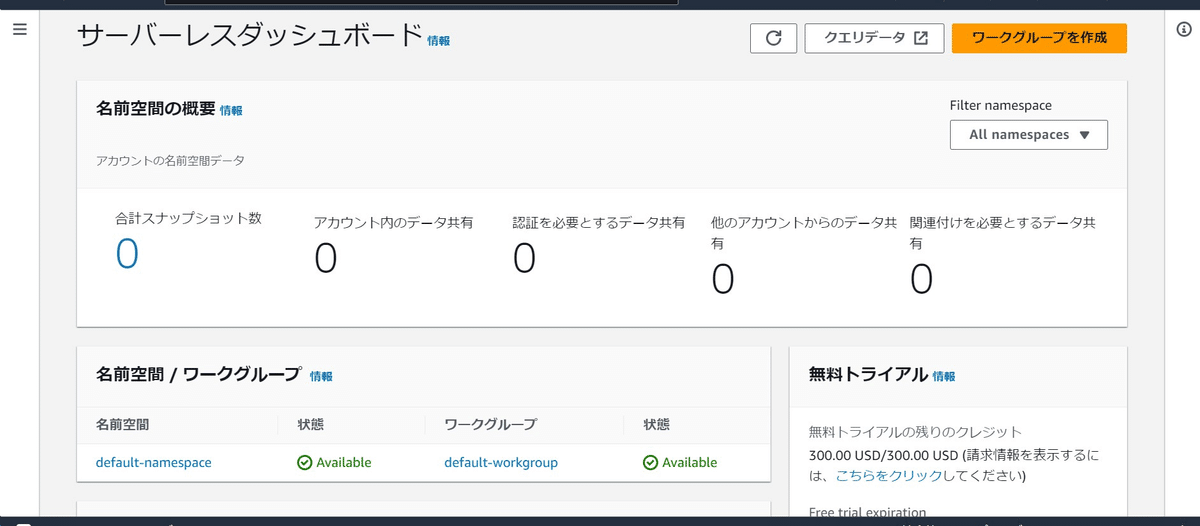
まず、Amazon Redshift Serverlessでワークグループを作成し、クエリデータからクエリエディタに遷移します。
Amazon Redshift Serverlessでは、従来のAmazon Redshiftと異なり、インスタンスの作成やチューニングが不要であるため、専門知識なくデータ分析を行うことができます。
テーブル作成用のSQL文と、S3のデータ呼び出すSQL文をコンソール部分に挿入し、「Run」で実行します。
S3のデータは、以下のSQL文で呼び出します。
COPY xxx from 's3://[S3 バケット名]/[ファイル名]' iam_role '[ロール ARN]' delimiter '|' ;

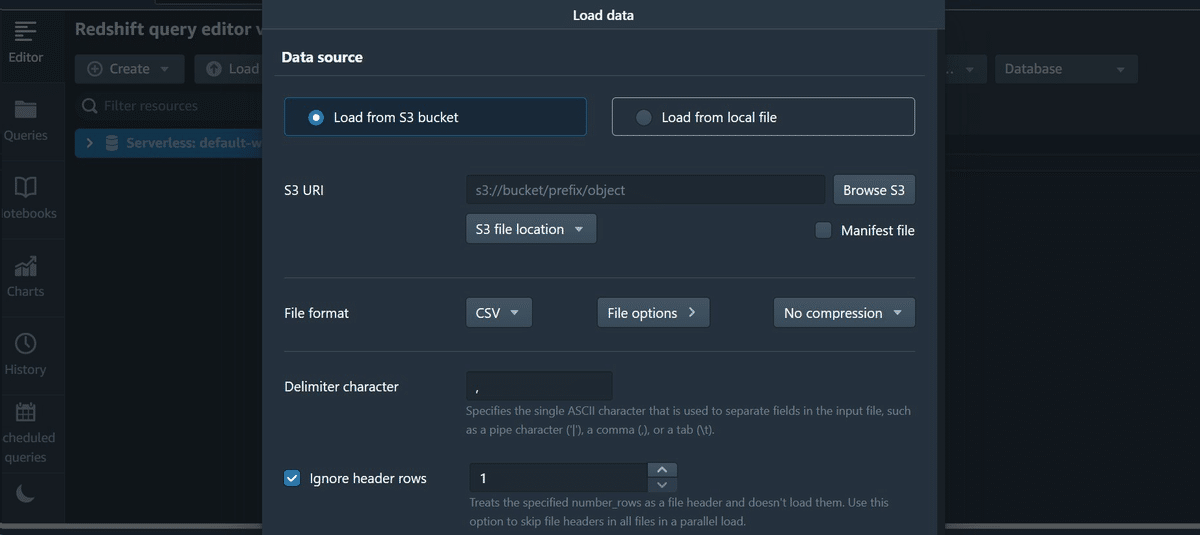
「Load data」からAmazon RedShiftにS3バケットのファイルを読み込ませることもできます。
テーブルの作成は、「Creat」から作成することもできます。
テーブル作成とデータのセットが完了出来れば、あとは、呼び出したい情報を要求するためのSQL文を同コンソールで実行すると値が返ってきます。

今回は簡易のため、Amazon Redshiftに直接データを呼び出しました。
しかし、今回は割愛しますが、Amazon RedshiftをBIツールである「Amazon QuickSight」のサービスと接続することでAmazon Redshiftから取得したデータの可視化(表やグラフを自動作成)を行うことができ、データ分析を容易にすることができます。
まとめ
今回は、簡易的にAmazon Redshiftを用いたデータ分析をするまでの方法をまとめてみました。
実際、SQL文を挿入するだけでデータ分析が可能であるため、必要な知識がとても少なく、簡単に扱うことが可能でした。
今後、より大量のデータを用いたデータの解析にAmazon Redshiftを用いてみたいです。
この記事が気に入ったらサポートをしてみませんか?