
そうだ!AI画像生成をちゃんと勉強しよう💡14章:ControlNet その4

ControlNet「Reference」「Scribble」
※勉強するのはStable Diffusion、SeaArt系になります。
ControlNetの勉強を再開したいと思います。
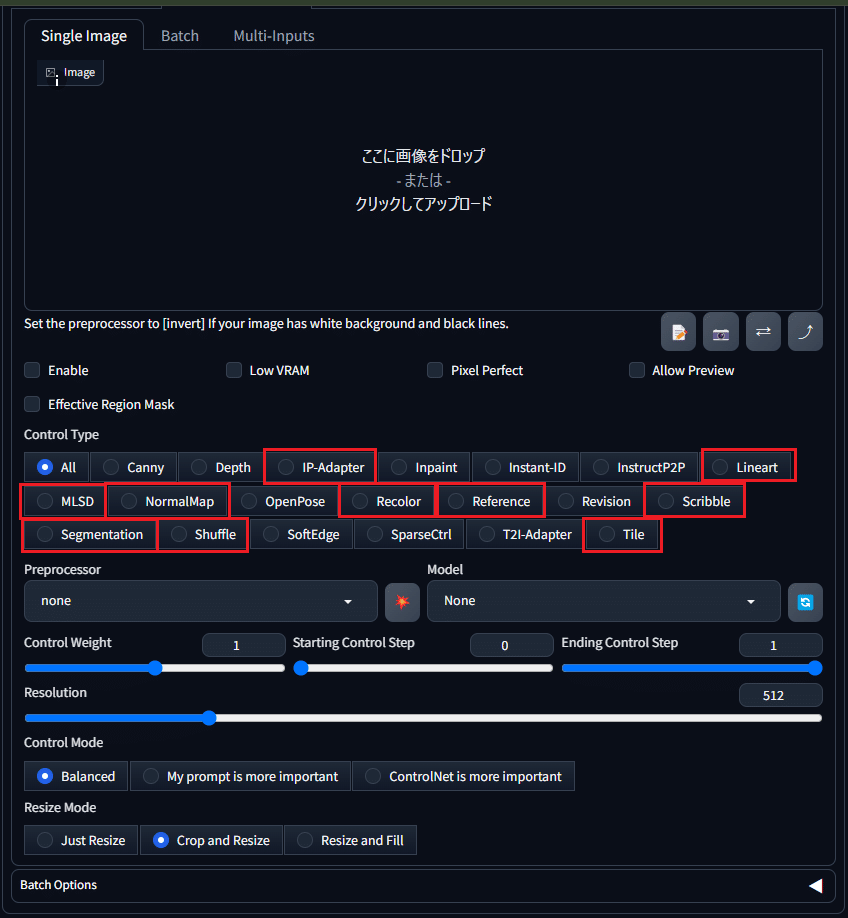
スクショの赤枠で囲ってあるものが今やっている10個です。今日はこの中の「Reference」と「Scribble」を学んでいきたいと思います。
それでは本日も等身大の私でよろしくお願いします(*⩌⩊⩌*)
Reference
既存の画像のスタイルやデザインを元にして、新しい画像を生成することができます。
特定のアートスタイルや色合いを持つ画像を基にして、そのスタイルを別の画像に適用したい場合に便利です。
Referenceの種類
リファレンス画像(参考にする画像)をどのように使いたいかによって使い分けます。リファレンス画像にとても似た画像を作りたいときや、少し変化を加えたいときなど、目的に合わせて最適な設定を選びましょう。これは同一人物が生成できるという噂をチラっと見たので楽しみです。
Referenceの種類は以下の3種類あります。
1. reference_only
概要: 「reference_only」は、リファレンス画像(参考になる画像)のスタイルや色合いをほぼそのまま使って、新しい画像を作る設定です。作成される画像は、リファレンス画像ととても似たものになります。
使い方: リファレンス画像のスタイルをそのまま使いたいときに、この設定を選びます。例えば、有名な絵画のスタイルを使って、新しい絵を作りたいときに便利です。
2. reference_adain+attn
概要: 「reference_adain+attn」は、リファレンス画像のスタイルを使いながら、細かい調整もできる設定です。これにより、リファレンス画像の特徴を保ちながら、少し柔軟に新しいスタイルに変えることができます。
使い方: リファレンス画像の雰囲気を残しつつ、細かい部分を調整したいときに、この設定を使います。例えば、リファレンス画像のスタイルを保ちながら、少し新しい要素を追加したい場合に便利です。
3. reference_adain
概要: 「reference_adain」は、リファレンス画像の全体的なスタイルや色合いを使って、新しい画像を作る設定です。Attention機能がないため、変換はシンプルになりますが、リファレンス画像の雰囲気を大まかに反映させることができます。
使い方: リファレンス画像の色調や雰囲気を別の画像に適用しつつ、シンプルな画像を作りたいときに、この設定を使います。
reference_only: リファレンス画像にとても忠実な画像を作りたいときに。
reference_adain+attn: リファレンス画像をベースにしつつ、柔軟に新しい要素や変化を加えたいときに。
reference_adain: リファレンス画像のスタイルをシンプルに適用し、大きな変更を必要としないときに。
Referenceを試してみる
3つとも試してみたのですが、違いが全然わからなかったので、SeaArtガイドブックでもおすすめされている「reference_only」を試した結果を記事にしたいと思います。
まずは元になる画像の準備です。今回は実写系の画像を用意してみました。プロンプトはモデルの参考画像からお借りします。
プロンプト:
best quality, face focus, soft light, ultra high res, (photorealistic:1.4), RAW photo, 1japanese girl, solo, cute, (pupil, lights in the eyes), detailed beautiful face, (small chest),(high resolution detail of human skin texture), (long hair), indoor, Damask Shirt Dress, (portrait)
(最高品質、顔フォーカス、ソフトライト、超高解像度、(フォトリアリスティック:1.4)、RAW写真、日本人女の子1人、ソロ、かわいい、(瞳孔、目のライト)、詳細な美しい顔、(胸が小さい)、(高解像度)人間の肌の質感の詳細)、(長い髪)、屋内、ダマスク シャツ ドレス、(ポートレート))
ネガティブプロンプト:painting,sketches,(worst quality:2),(low quality:2),(normal quality:2),((monochrome)),((grayscale)),missing fingers,skin spots,acnes,skin blemishes,loli

コントロールネットを有効化して「Reference」を選択して画像をアップロードしました。

プリプロセッサを「reference_only」にして、プロンプトは空で出力してみます。ネガティブプロンプトは残したままにします。

プロンプトが空なのですべてAI任せですが、顔は元画像と似ている気がします。
服装を変えてみる
次は服装を指定してみたいと思います。
プロンプトを「1japanese girl,t-shirt」にして(1japanese girlは元画像のプロンプトで使ったもの)出力。

服装の違う同一人物が生成されました。
髪色を変えてみる
次は髪色を変えてみます。
プロンプトを「1japanese girl,white hair」にして出力。

ちゃんと白髪になって出てきました。真っ白ではなく自然な感じになってるのがすごいです。
髪型を変えてみる
次は髪型を変えてみます「1japanese girl,hair_tucking(髪を留める)」にして出力。

表情を変えてみる
次は表情を変えてみます。元のプロンプトに「smile」を書き加えて出力。

モデルを変えてみる
最後にモデルを2パターンのアニメ系に変えて出力してみます。


Referenceは主に「reference_only」を使用し、
人物やキャラクターの顔を固定して色々なバリエーションの画像を作るときに重宝するようです。
Scribble
簡単な線画や落書きを元にして、詳細な画像を生成する機能。
シンプルなアイデアやスケッチを素早く高品質な画像に変えるのに非常に便利。
Scribbleの種類
CannyやLineartに似ていますが、落書きのような線画で画像効果をより自由に制御できる。
scribble_pidinet: 詳細な輪郭線を捉えたスケッチに向いています。
invert: 白黒を反転させた画像を作成したいときに使います。
scribble_xdog: 強調された輪郭と芸術的なエフェクトを加えたいときに適しています。
scribble_hed: 画像全体のエッジを捉えて、広範囲のスケッチを元にした画像生成に適しています。
Scribbleを試してみる
それでは4種類を試してみます。
元になる画像はリアル系(yayoimix)にして、アニメ系(awpainting)の画像を生成してみたいと思います。
サンプラー:DPM++SDE Karras
サンプリングステップ:20
CFGスケール:7
VAE:vae-ft-mse-840000
クリップスキップ:1
プロンプト:girl,one piece,smile,upper_body,top quality,super fine illustration,8K(女の子、ワンピース、笑顔、上半身、最高品質、スーパーファインイラスト、8K)

1. scribble_pidinet
概要: PidiNetは、線画やスケッチの輪郭線を抽出するためのアルゴリズムです。この設定は、スケッチや線画の輪郭を精密に捉え、それを元に画像を生成します。
使い方: 細かい輪郭や線のディテールを重視したい場合に使います。キャラクターの輪郭や建物の詳細を捉えたスケッチを元にした画像生成に適しています。


2. invert (from white bg & black line)
概要: この設定は、白い背景に黒い線で描かれたスケッチを反転させ、黒い背景に白い線に変換します。これにより、元の線画とは逆の色合いで画像を生成します。
使い方: スケッチが黒い背景に白い線で描かれている場合に便利です。また、反転した色で新しい視覚効果を試したい場合にも使えます。


※これは元画像が白黒ではなかったので想定通りの動作はしなかったようです。
3. scribble_xdog
概要: XDoG(eXtended Difference of Gaussians)は、輪郭を強調し、芸術的なエフェクトを加えるアルゴリズムです。この設定を使うと、スケッチの線を際立たせ、より芸術的な画像を生成します。
使い方: スケッチの輪郭を強調したアートスタイルの画像を作りたいときに使用します。特に、キャラクターやシーンの独特な雰囲気を出したい場合に適しています。


4. scribble_hed
概要: HED(Holistically-nested Edge Detection)は、画像全体のエッジ(輪郭)を検出するための技術です。この設定は、スケッチや線画のエッジを広範囲にわたって捉え、それを元にした画像生成に役立ちます。
使い方: 全体的なエッジ検出を重視したい場合に使います。風景や建築物など、広範囲にわたるスケッチの輪郭を元にした画像生成に適しています。


このような結果になりました。
プロンプトは空でシード値もランダムにしましたが、元の画像に近い色合いで出たりしたので、そういう機能なのかな?と思いました。
今日は実用性の高そうな「Reference」と、線画を抽出して画像生成する「Scribble」を学びました。
線が抽出系は沢山あってどの時にどれを使ったらよいかはピンときていませんが、その辺りは色々経験しながら掴んでいけたらいいなと思います。
参考にさせてもらったガイドブックです👇
今日のサムネ生成過程(ChatGPT,DALL-E 3)
私「「そうだ!AI画像生成をちゃんと勉強しよう💡14章:ControlNet その4」というタイトルのnote記事を書きました。 このタイトルに合うような画像を作ってください。 要望は、夏服を着たロングヘアーの美少女、日本の少女漫画のような繊細なタッチで、水彩画のようなカラーリングで16:9で描いてください。」

ChatGPTくん「こちらが「そうだ!AI画像生成をちゃんと勉強しよう💡14章:ControlNet その4」のタイトルに合うイラストです。ご確認ください。」
私「ありがとう!」
以上。
ここから先は
¥ 100
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?