
【Excel】え、ついに?! 間にスペースのない氏名や住所を分割する★

こんにちは、HARUです!
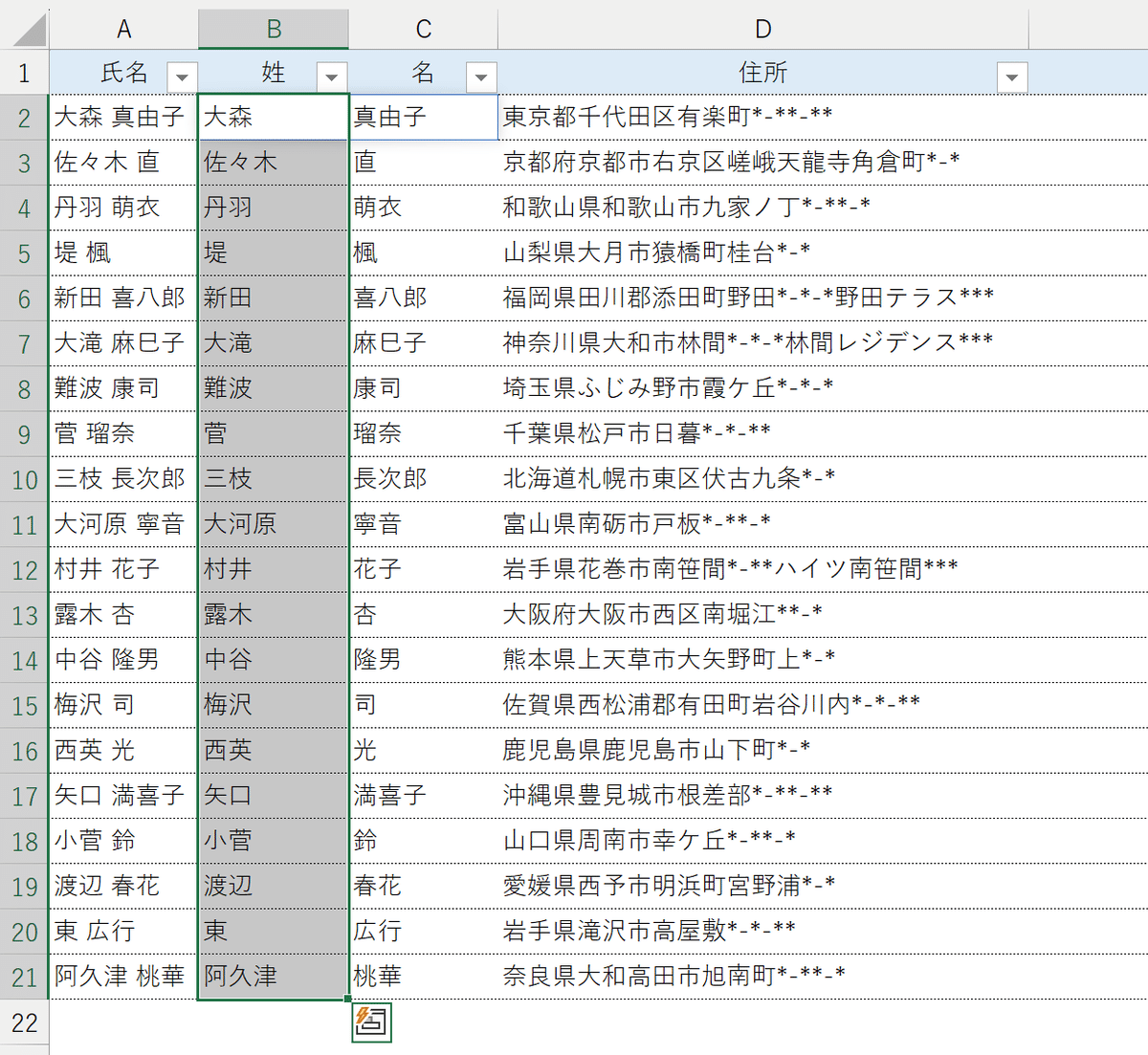
実務では、名簿の氏名を「姓」と「名」に分けたり、住所を「都道府県名」と「市区町村名(以降)」に分けたりすることがありますよね。

苗字と名前の間にスペースなどの共通の文字列がある場合や、苗字の文字数が同じ場合はExcelの標準機能または文字列操作関数を使って分割できますが、いずれの要件も満たしていないと、こうした処理を行うのは容易ではありません。
そこで今回は、間にスペースがない氏名や住所の文字列を要素ごとに分割する方法をご紹介します。
現代を生きるビジネスパーソンにとって不可欠なスキルセットを使っていきますので、ぜひ最後までお付き合いください。
↓投稿者のYouTubeチャンネルはこちらをチェック!↓
氏名の間にスペースが「ある」場合
本題に入る前に、苗字と名前の間にスペースなど基準となる文字列がある場合の対処法を簡単におさらいしておきましょう。
フラッシュフィル
1つ目は「フラッシュフィル」です。
①先頭の氏名のみ、姓と名を直接入力します。
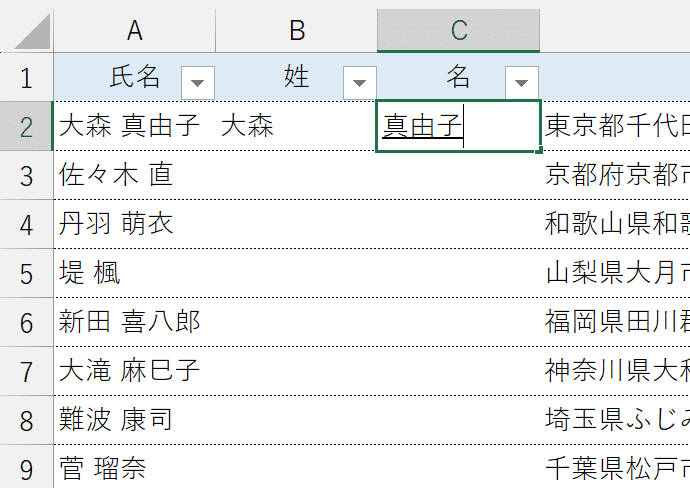
②"姓"をアクティブにして[Ctrl]+[E]を押します。
これにより、A列に入力されたすべての氏名のうち、姓の部分が一括で取り出されます。

③"名"をアクティブにして、同じく[Ctrl]+[E]を押します。
これにより、A列に入力されたすべての氏名のうち、名の部分が一括で取り出されます。
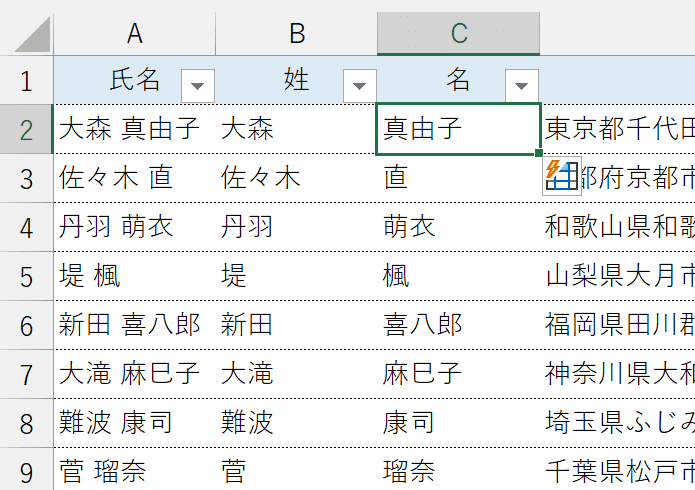
いま使った[Ctrl]+[E]は、「フラッシュフィル」という機能を実行するショートカットキーです。フラッシュフィルは、サンプルデータをもとに、そのサンプルと同じ規則性を持って値を自動入力する役割を持っています。
※ショートカットキーはExcel2013以降のバージョンが対象です。
今回の例でいえば、B2セルに入れたサンプルから、氏名の中で半角スペースの左側にある文字列を取り出すんだとExcelが判断し、すべての「姓」を返してくれます。
また、C2セルに入れたサンプルから、氏名の中で半角スペースの右側にある文字列を取り出すんだとExcelが判断し、すべての「名」を返してくれるんですね。
区切り位置
続いては、「区切り位置」です。
①A列の氏名を一度、B列の姓の欄にコピーします。

②B列の"姓"が選択された状態のまま、「データ」タブ→「区切り位置」のアイコンをクリックします。

「区切り位置指定ウィザード」ダイアログボックスが開きます。
③1ページ目の画面では特に何も設定せず、右下の「次へ」を押します。

④2ページ目の画面で、区切り文字をデフォルトの「タブ」から「スペース」に変更して、「次へ」を押します。
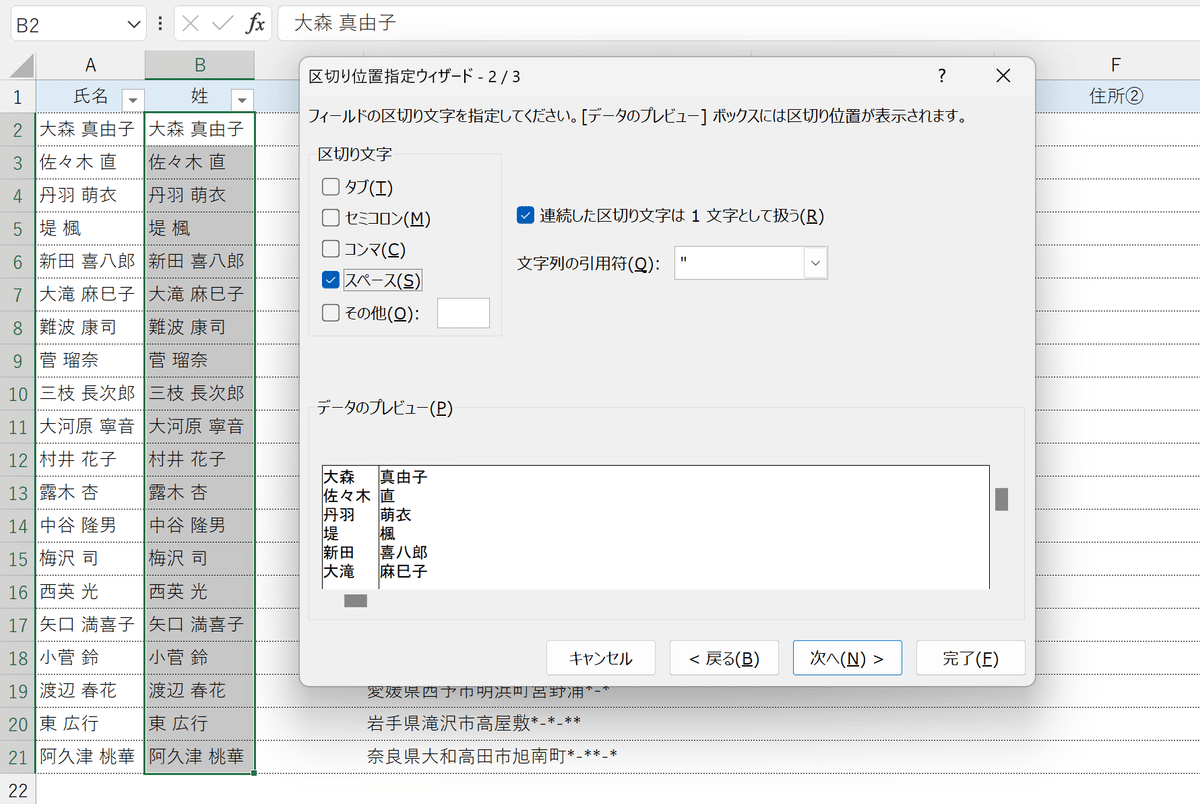
⑤3ページ目の画面は特に何も触らず、右下の「完了」で実行します。
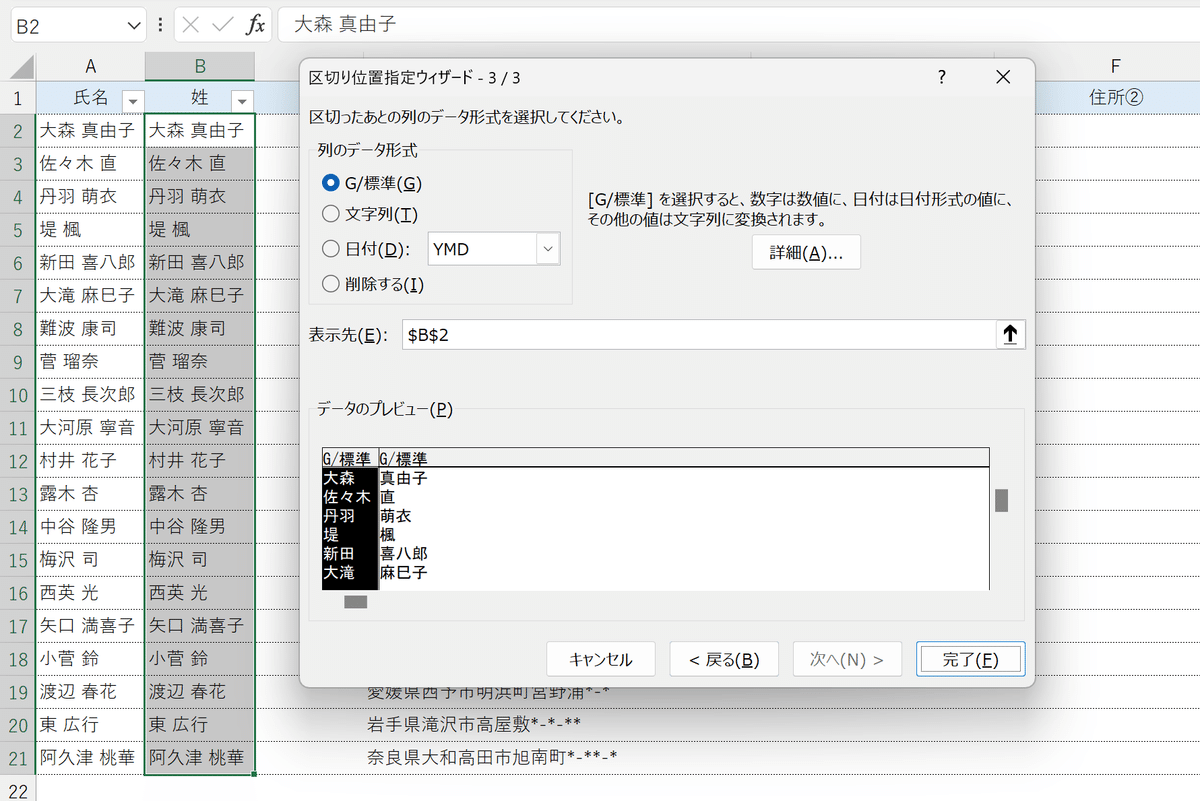
⑥下図のポップアップは「OK」でスルーします。
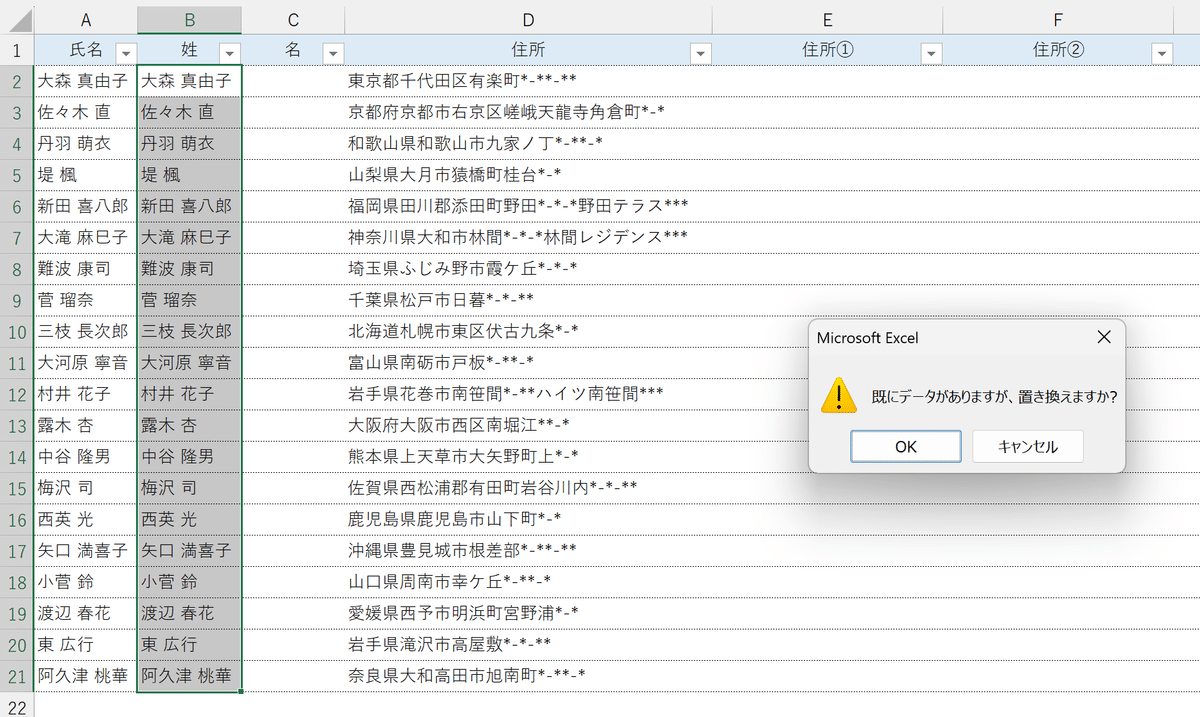
これにより、B列の氏名が姓と名に分かれます。

一連の手順をご覧いただいた通り「区切り位置」は、特定の文字列や符号を基準に文字列を分割する機能です。
CSVファイルなどで取得したデータをカンマを基準に切り分けたり、PDFファイルのデータをコピーして半角スペースを基準に切り分けたりするシーンで重宝します。
※フラッシュフィルや区切り位置は比較的かんたんな操作で実行できますが、アウトプットはあくまで「値」データなので、元の氏名で苗字が変更になった場合などはその都度同じ処理を行う、または直接手直しする必要があります。

文字列操作関数①
こんなときは、文字列操作関数を使って元データと連動するしくみが理想的です。
①"姓"の欄に次の数式を入力します。【=LEFT(A2,FIND(" ",A2)-1)】

「A列の氏名において半角スペースが左から何番目にあるかをFIND関数で調べ、その文字数から半角スペースの1文字分を差し引いた数をLEFT関数で取り出す。」という指示を出しています。
結果、氏名における姓の部分だけを取得できます。
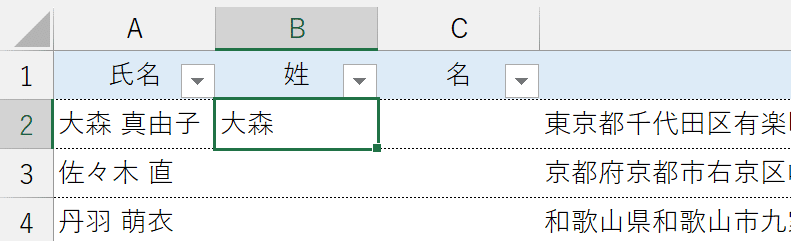
②"名"の欄に次の数式を入力します。【=RIGHT(A2,LEN(A2)-FIND(" ",A2))】
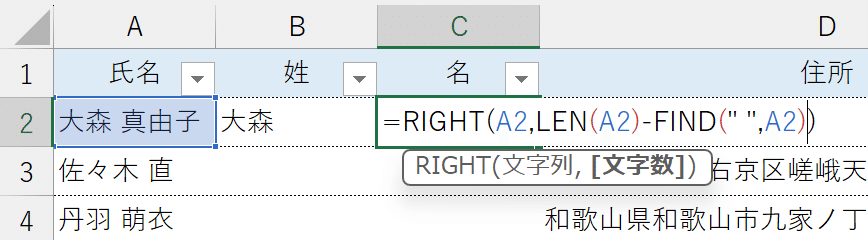
「A列の氏名において半角スペースが左から何番目にあるかをFIND関数で調べ、その値をLEN関数で数えた氏名全体の文字数から差し引く。その差し引いた文字数分だけRIGHT関数で右から取り出す。」という指示を出しています。
結果、氏名における名の部分だけを取得できます。
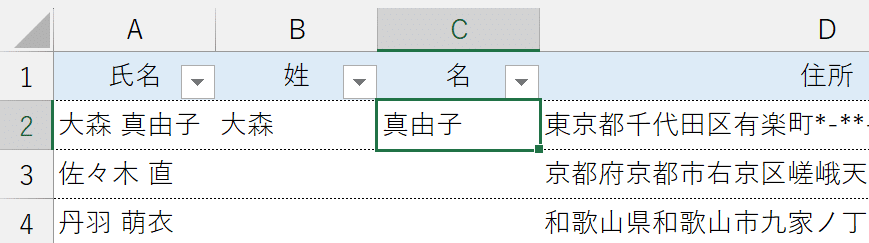
③それぞれの数式を下へコピーします。
すべての氏名が、姓と名に分割されます。

数式としてアウトプットしてしまえば、たとえ元データの内容が変更された場合でも連動して更新されます。

文字列操作関数②
Microsoft365の最新バージョンをお使いであれば、文字列操作に適した動的配列数式が使えます。
①"姓"の欄に次の数式を入力します。【=TEXTBEFORE(A2," ")】

TEXTBEFORE関数は、第1引数「text」に参照した文字列において、第2引数「delimiter」に指示する区切り文字より前のデータを取得する役割を持っています。
結果、textとして参照した「氏名」において、delimiterとして指示した「半角スペース」より前にある文字列、要は"姓"の部分が取り出せます。

なお、第1引数の参照元を氏名のリストすべてに拡張すると、すべての姓がスピルで生成されます。


②"名"の欄に次の数式を入力します。【=TEXTAFTER(A2," ")】

TEXTAFTER関数は、第1引数「text」に参照した文字列において、第2引数「delimiter」に指示する区切り文字より後のデータを取得する役割を持っています。
結果、textとして参照した「氏名」において、delimiterとして指示した「半角スペース」より後にある文字列、要は"名"の部分が取り出せます。
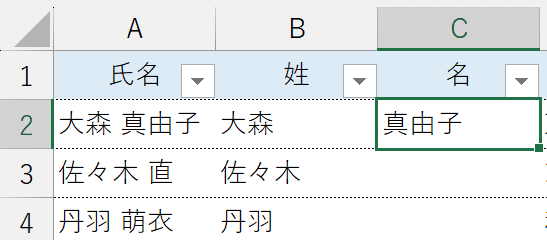
TEXTAFTER関数も、第1引数にすべての氏名を参照すれば、名がスピルで生成されます。
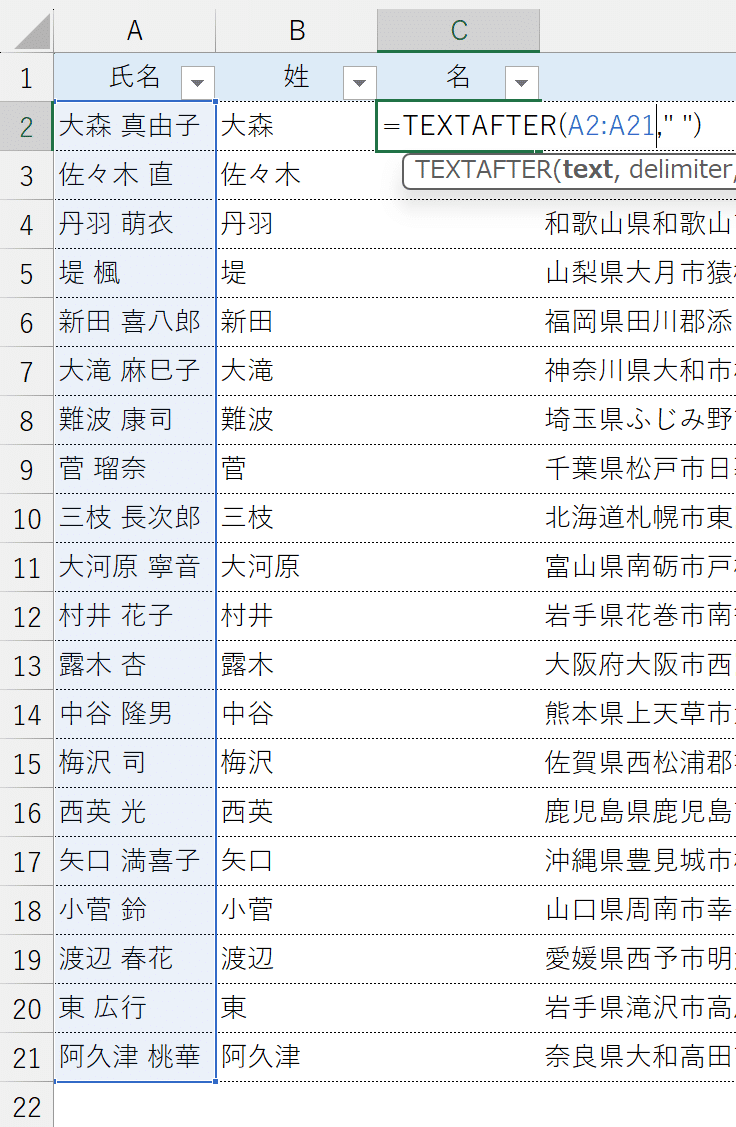

ちなみに、一連の操作はTEXTSPLIT関数でも代用できます。
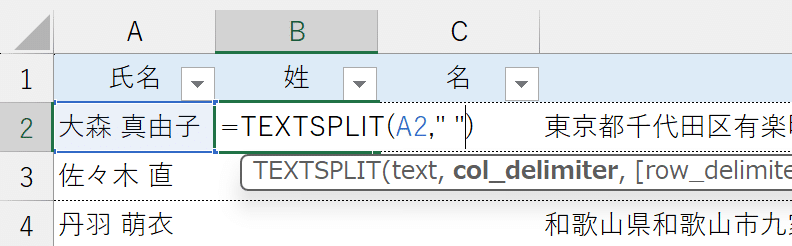
TEXTSPLIT関数は、第1引数「text」に参照した文字列を、第2引数「delimiter」に指示する区切り文字で分割する役割を持っています。
結果、textとして参照した「氏名」を、delimiterとして指示した「半角スペース」で分割し、"姓"と"名"を切り分けて取り出してくれます。
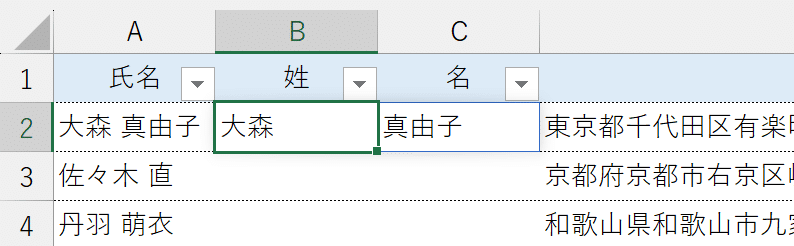
他の範囲に数式をコピーして完成です。
都道府県名を取り出す
住所の表記は都道府県名や市区町村、番地の情報が間髪入れずに連なっていることがほとんどなので、ここまで解説した手順では正確に取り出すことはできません。
ただし、都道府県名だけを取得するのであれば、次の方法があります。
住所①(都道府県名)の欄に次の数式を入力します。【=IF(MID(D2,4,1)="県",LEFT(D2,4),LEFT(D2,3))】
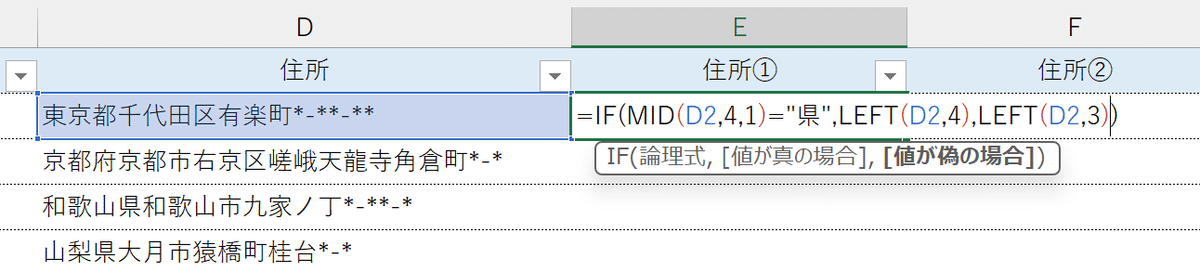
まず、日本に存在する47の都道府県名の特長として、以下が挙げられます。
都道府県名が4文字なのは"神奈川県"、"和歌山県"、"鹿児島県"のみ。
4文字の都道府県はすべて"県"で終わる。
日本に存在する自治体において、都道府県名のあとに続けて"県"で始まる市区町村はない。
これらの前提条件から、「住所の左から4文字目をMID関数で1文字だけ取り出したときに、その文字列が"県"であれば、"神奈川県"、"和歌山県"、"鹿児島県"に該当するため左から4文字取り出し、それ以外は左から3文字取り出せばよい。」という論理式が成り立つのですね。

数式を下へコピーすると、すべての都道府県名が正確に取り出せていることがわかります。

氏名の間にスペースが「ない」場合
さてここからは、苗字と名前の間にスペースがないケースの対処法です。
ここから先は
¥ 980
この記事が気に入ったらサポートをしてみませんか?