
日本語LLM祭りで課金するどころか、めちゃ勉強になってしまった話

「風が吹けば桶屋が儲かる」と申しますが、
日本語LLM祭りが起きると{Google/AWS/NVIDIA}が儲かるのでございます。
Llama_indexを触っていたとき、僕はこんなことを言っていました。
llama_indexおもしろい
— Dr.(Shirai)Hakase #AI神絵師本 #技術書典14 (@o_ob) May 14, 2023
これは寝れなくなるし
OpenAIじゃなくても動くの素敵
誰か日本語おすすめのLLM教えて https://t.co/Xme7iRIe5v
llama_indexおもしろい
これは寝れなくなるし
OpenAIじゃなくても動くの素敵
誰か日本語おすすめのLLM教えて
実はLlama_indexには最近、OpenAI以外のLLMも渡せるようになったのです。ほかのLLM、特にAPI費のかからないオープンソース型のLLMが使えればもっといろんな使い道ができるのに!でも日本語のLLMはまだまだ成熟しているとは言えません。「誰か日本語おすすめのLLM教えて」という雑な問いに、その時は誰も答えてはくれませんでした。そう、その時は。
日付変わって5月17日。そう、3日後です。生成AIで3日、72時間といえば、3か月ぐらいの意味を持つのかもしれませんが、インパクトのある日本語LLM(JLLM)が突然2つ同日に公開されました。お祭り状態です。ちなみにこの3日間には世間ではGoogleBard日本語版やChatGPT Plusユーザ向けにリリースされたPlugins&Web検索で沸いていました。プロレス団体か君たちは。
Rinna-3.6B:日本語に特化した36億パラメータ
▼rinna、日本語に特化した36億パラメータのGPT言語モデルを公開 https://prtimes.jp/main/html/rd/p/000000042.000070041.html
落ち着いて、まずはRinna社のプレスリリースから読んでいこう。
2018年にOpenAI社から提案されたGPT (Generative Pre-trained Transformer) は、高速な学習が可能なTransformer構造と大量のテキストを学習データとして利用できる自己教師あり学習により、テキスト生成において技術的なブレイクスルーをもたらしました。その後もGPTは進化を続け、OpenAI社が2022年にサービスを開始したChatGPTは一般のユーザーが広く利用するまでの技術革新となっています。ChatGPTは、汎用GPT-3言語モデルに対して対話形式でユーザーの指示を遂行するタスクを実現するようなfine-tuningと、生成されたテキストに対して人間の評価を再現する報酬モデルのスコアを導入した強化学習により構築されます。
GPTのような大規模言語モデルを学習するためには大量の計算資源が必要となり、誰でも気軽に学習できるわけではないため、多くの研究機関や企業が事前学習した大規模言語モデルをオープンソースで公開することで発展に貢献しています。しかし、オープンソースの大規模言語モデルは英語に特化していることが多く、日本語言語モデルの選択肢は十分にあるわけではありません。rinnaはこれまでに日本語に特化した13億パラメータのGPTなどを公開し、多くの研究・開発者にご利用いただいていますが、この度、より利用の幅を広げられるよう日本語に特化した36億パラメータを持つ汎用言語モデルと対話言語モデルの2種類のGPT言語モデルをオープンソースで公開いたします。これらのモデル公開により、日本語言語モデルを活用した研究・開発がより発展することを期待します。
美しい文章だな…。
驚き屋さん構文とは全く違う。書いた人物の丁寧さが感じられます。
■ rinnaの36億パラメータの日本語GPT言語モデルの特徴
特定のドメイン特化ではない汎用GPT言語モデル (rinna/japanese-gpt-neox-3.6b) と、汎用GPT言語モデルを対話形式の指示遂行ドメインにfine-tuningした対話GPT言語モデル (rinna/japanese-gpt-neox-3.6b-instruction-sft) を学習し公開しました。これらのモデルには以下の特徴があります。
・汎用言語モデルは、日本語のWikipedia ( https://huggingface.co/datasets/wikipedia )・C4 ( https://huggingface.co/datasets/mc4 )・CC-100 ( https://huggingface.co/datasets/cc100 ) のオープンソースデータを用いて学習されています。対話言語モデルは、HH-RLHF ( https://huggingface.co/datasets/Anthropic/hh-rlhf )・SHP ( https://huggingface.co/datasets/stanfordnlp/SHP )・FLAN ( https://github.com/google-research/FLAN ) の一部を日本語に翻訳したデータを用いて学習されています。
・汎用言語モデルのperplexityは8.68を達成しています。8.68 perplexityとは、GPTが次の単語を予測するときに単語の候補数を8.68に絞られていることを意味します。
・対話言語モデルのインターフェースは、対話形式を採用しユーザーが利用しやすいように設計しています。
・事前学習済みのモデルは、Hugging Faceに商用利用可能なMIT Licenseで公開されています。
・ユーザーは、2種類のモデルから利用者の目的に応じて最適なモデルを選択することができます。さらに、特定の利用目的に対して性能を最適化させたい場合には、fine-tuningやin-context learningにより精度向上を目指すことができます。
・汎用GPT言語モデル(Hugging Faceリンク):
https://huggingface.co/rinna/japanese-gpt-neox-3.6b
・対話GPT言語モデル(Hugging Faceリンク):
https://huggingface.co/rinna/japanese-gpt-neox-3.6b-instruction-sft
早速試していきたい…と思ってたら npakaさんがすでに Google Colabで試していらしゃいました。
追いかけて何度かやってみたのですが、無料で利用できるGPU「T4」では微妙に動かないみたい…。
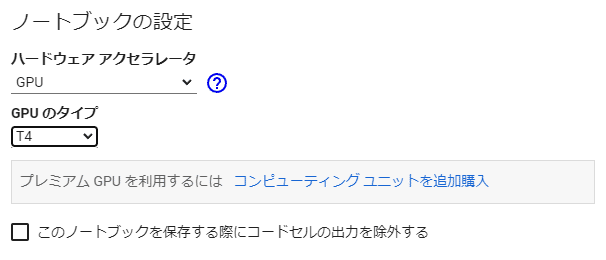
ちなみに「A100」ですが、NVIDIA Tesla A100シリーズのこと。
日本で買うと200万ぐらいするはず。
40 GBだと8000ドルぐらいからありそう。
NVIDIA Tesla A100 Ampere 40 GB Graphics Card - PCIe 4.0 - Dual Slot
まあこんなの家に置いたらエアコン代と電気代が大変なことになるのですが…。
GPUだけではなくて、メモリも足りないのかもしれない。
AutoTokenizer.from_pretrained() のところでクラッシュする…。
▼Transformersの'from_pretrained'の使い方とリスクを考察
モデルをGoogle Driveに移動させる方法もやってみたけど、まずはメインメモリが微妙に絶妙に足りない。「ハイメモリ」が選択できればいいのかも?
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", use_fast=False )
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft")
1か月あたり1179円払えば行けるのかもしれない…(ごくり)。
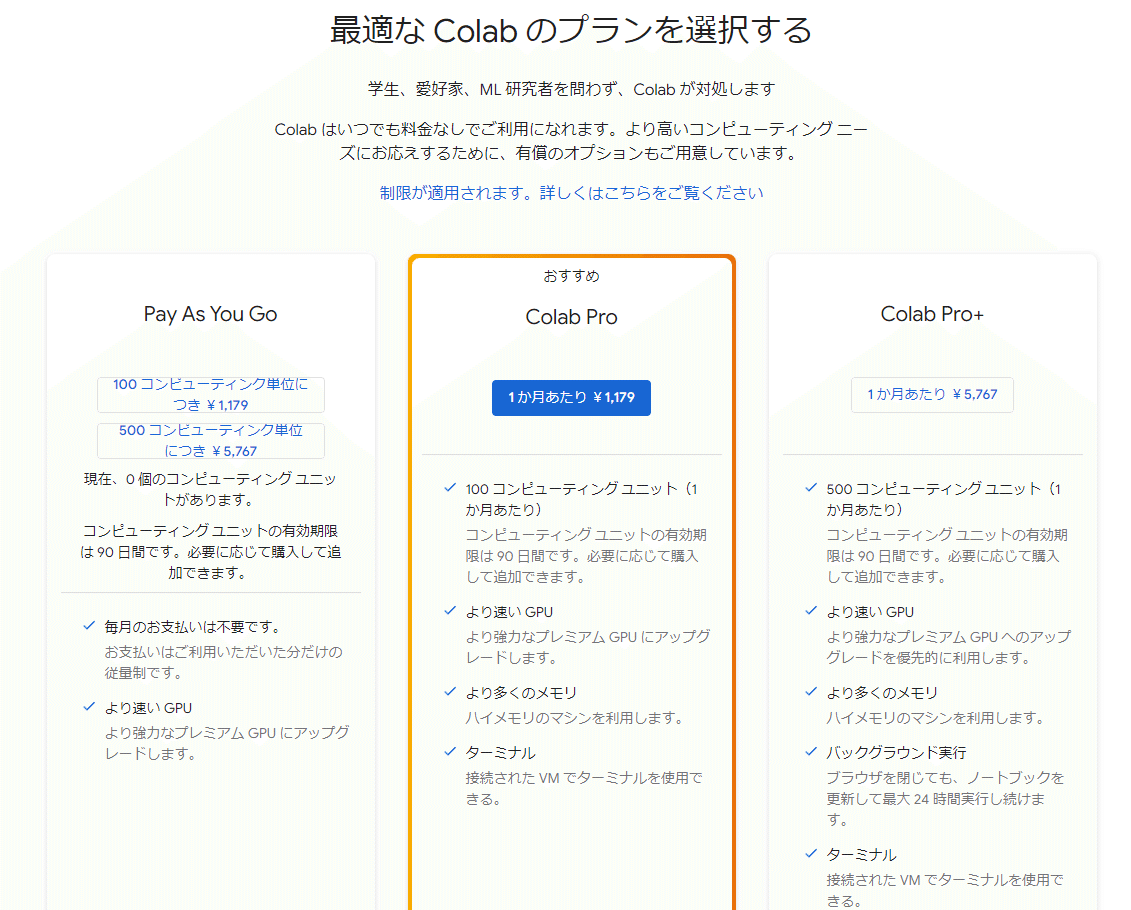
以前は無料で利用できるパワフルなPython環境として便利だったのですが、最近は生成AIのおかげか、微妙に難しいことをやろうとすると有料プランをすすめられてしまいます。もちろんそんなに高いわけではないのですが、自分のPC環境でやれるかもしれないラインだと悩む…。お金が惜しいというよりは時間が惜しい…。というかnpakaさんの言うようにA100が選べればそれで問題ないからポチってしまえばいいのか……いいのか…?
ちなみにGPT2などであれば動きます。モデルの選択かもしれない。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")ガチにやりたいならAWSでもいいんだよな…ごくり…。
と悩んでいたら、今度はサイバーエージェントさんからさらにでかいニュースが…!
CA社最大68億パラメータの日本語LLM「OpenCALM7B」公開
▼サイバーエージェント、最大68億パラメータの日本語LLM(大規模言語モデル)を一般公開 ―オープンなデータで学習した商用利用可能なモデルを提供― | 株式会社サイバーエージェント
https://www.cyberagent.co.jp/news/detail/id=28817
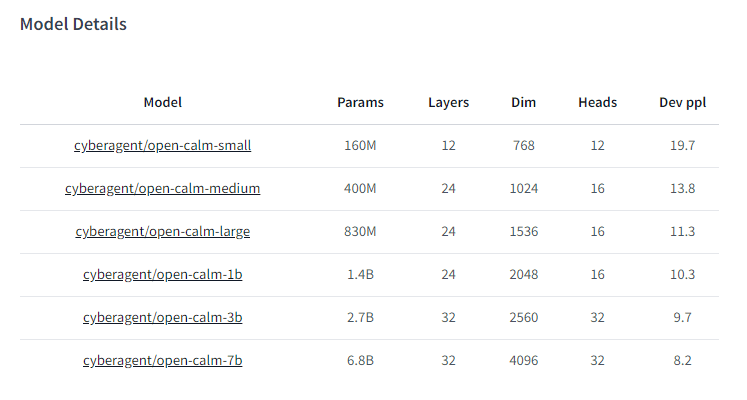
68億パラメータの日本語…!?
当社が開発した「最大68億パラメータの日本語LLM」を商用利用可能なライセンスで公開いたしました。本モデルをベースにチューニングを行うことで、対話型AI等の開発が可能です。
— サイバーエージェント 広報&IR担当 (@CyberAgent_PR) May 17, 2023
今後もモデル公開や産学連携を通し、国内における自然言語処理技術の発展に貢献してまいります。https://t.co/BYbcZYFvBi
https://huggingface.co/cyberagent/open-calm-7b
さっそく清水さんがさくらクラウドで試してくれています。
▼サイバーエージェントが公開した大規模言語モデルの実力を試す
清水亮の「世界を変えるAI」
2023年05月17日 12時10分 公開
っていうか清水さんさっき別のいいブログでこんなこと書いてたじゃない…
▼人間のために書く原稿に対してモチベーションが上がらなくなってきたWirelessWire News Updated by Ryo Shimizu on May 17, 2023, 09:06 am JST
https://wirelesswire.jp/2023/05/84684/
ちなみに自分、PhDなので「学者っぽい人物」と思われる事も多いのですが、俗な仕事もたくさんやってます。「窓の杜」での連載もありますが、このブログも無料の雑文だし。
僕も文字を書く側ですので共感できる
— Dr.(Shirai)Hakase #AI神絵師本 #技術書典14 (@o_ob) May 17, 2023
というか自分、毎日すごい勢いでブログ書いてるけど実はChatGPTで生成したりはしていない(喰わせてはいる) https://t.co/pMFScOK94r
そんな共感をしながら売文しながらすごい勢いでLLMを叩いているという意味ではホント尊敬する…。
無料版Colabで最新の日本語LLMを動かしたい!
さて、気を取り直して無料版のGoogle ColabでCALMの軽めのモデルを読んでみます。これは貧乏性というより、単に研究です。
※最後に Google Colab での ipynbを共有します
まずはモデルのダウンロード。ちょっとしたコツがあって、modelとtokenizerだと先にmodelをダウンロードするとうまくいくことが多い。ソースコードの順番を入れ替える。
!pip install transformers sentencepiece
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("cyberagent/open-calm-3b")
tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-3b", use_fast=False )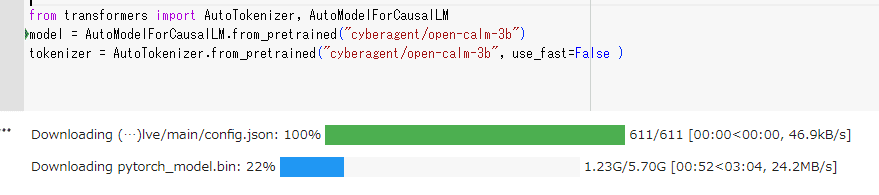
トークナイザーのほうが「そんなモデルないよ!」と言ってくることが多いのですが、AutoModelForCasualLM.from_pretrained()で HuggingFaceのリポジトリ名を指定することで必要なファイルをダウンロードしに行ってくれます。自分でダウンロードして配置してもいいですが、普通に重たいのでHuggingFace→Google間の転送に任せたほうがいい気がする。
なお、途中でコケるとキャッシュが邪魔するのでセッション作り直したほうがいいかもしれないです(キャッシュファイルの状態を見ることができます)。
モデルは読めるのですが、トークナイザーが落ちる!

f"Tokenizer class {tokenizer_class_candidate} does not exist or is not currently imported."
rinnaのほうも絶妙に乗り切らない…12.7GBのメモリに、7GBのmodelをロードしているところでクラッシュします。

そもそもトークナイザーとは何なのか?
Googleが2017年に公開した深層学習モデル「Transformer」は現在の生成AIの根幹となる技術です。画像生成AIのStable Diffusionやボイスチェンジャーなどでも使われており、現在の自然言語処理の主流になっています。「Huggingface Transformers」は、Transformerを実装するためのフレームワークであり、「自然言語理解」と「自然言語生成」の最先端の汎用アーキテクチャ(BERT、GPT-2など)と、何千もの事前学習済みモデルを提供しています。ソースコードは全てGitHub上で公開されており、誰でも無料で使うことができます。
Huggingface Transformersにおける自然言語処理では「パイプライン」と「トークナイザー」による実装方法があります。パイプラインはタスクと入力テキストによる推論処理を行います。「トークナイザー」で入力テキストを深層学習モデルに対応した形式に変換し、その入力データを使って「モデル」を直接操作して、推論を実行しています。パイプラインは手軽に実行できますが、カスタマイズ性が低く、トークナイザーはカスタマイズ性が高く、多くのタスクで日本語での推論にも対応できます。
ナイスな解説ありがとうございます。
▼【🔰Huggingface Transformers入門⑤】トークナイザーとモデルによるタスク紹介 2022年11月9日 つくもちブログ tt-tsukumochi
トークナイザーは自然言語の入力テキストを深層学習モデルの入力データに変換するプログラムのことです。入力テキストをトークンに分割し、各トークンを「トークンID」に変換し、それをテンソルでラップします。「トークナイザー」はモデルに関連付けられた「トークナイザークラス」または「AutoTokenizer」で作成することができます。以下の例のようにトークナイザーを設定します。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
2022年11月9日 tt-tsukumochi
GPU が利用できる場合は GPU を利用する
結論から言うと、OpenCALM-1Bのモデルとトークナイザーで行けました。
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "cyberagent/open-calm-1b"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained("cyberagent/open-calm-1b")
# GPU が利用できる場合は GPU を利用する
device = "cuda:0" if torch.cuda.is_available() else "cpu"
device
model.to(device)で乗った!

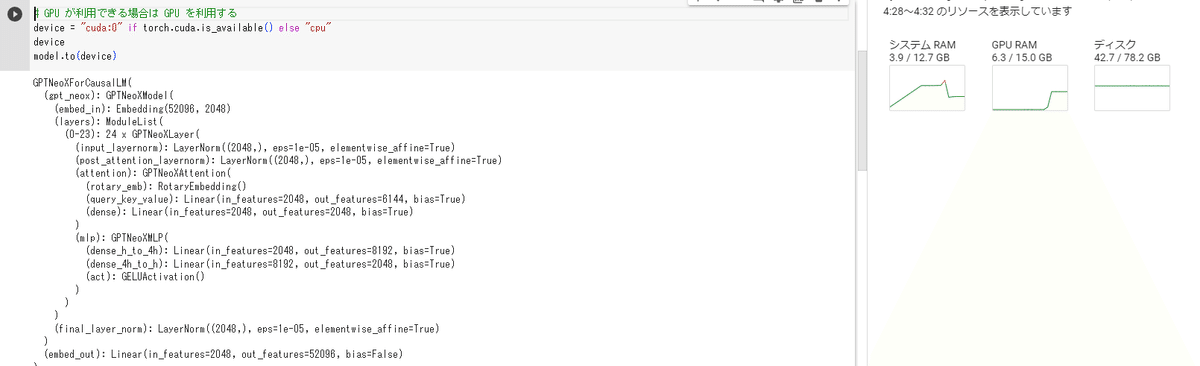
せっかくなのでOpenCALMを叩いてみる
rinnaと違って対話型ではなく補完するモデルのようですが、とりあえず対話してみます。



なお、GPTNeoXForCasualLMの機能について、センチメント分析(感情推定)をやってみたのですが、サポートされていないようでした。以下の機能が使えるのでいろいろ遊んでいきたい。
The model 'GPTNeoXForCausalLM' is not supported for sentiment-analysis. Supported models are ['AlbertForSequenceClassification', 'BartForSequenceClassification', 'BertForSequenceClassification', 'BigBirdForSequenceClassification', 'BigBirdPegasusForSequenceClassification', 'BioGptForSequenceClassification', 'BloomForSequenceClassification', 'CamembertForSequenceClassification', 'CanineForSequenceClassification', 'ConvBertForSequenceClassification', 'CTRLForSequenceClassification', 'Data2VecTextForSequenceClassification', 'DebertaForSequenceClassification', 'DebertaV2ForSequenceClassification', 'DistilBertForSequenceClassification', 'ElectraForSequenceClassification', 'ErnieForSequenceClassification', 'ErnieMForSequenceClassification', 'EsmForSequenceClassification', 'FlaubertForSequenceClassification', 'FNetForSequenceClassification', 'FunnelForSequenceClassification', 'GPT2ForSequenceClassification', 'GPT2ForSequenceClassification', 'GPTBigCodeForSequenceClassification', 'GPTNeoForSequenceClassification', 'GPTNeoXForSequenceClassification', 'GPTJForSequenceClassification', 'IBertForSequenceClassification', 'LayoutLMForSequenceClassification', 'LayoutLMv2ForSequenceClassification', 'LayoutLMv3ForSequenceClassification', 'LEDForSequenceClassification', 'LiltForSequenceClassification', 'LlamaForSequenceClassification', 'LongformerForSequenceClassification', 'LukeForSequenceClassification', 'MarkupLMForSequenceClassification', 'MBartForSequenceClassification', 'MegaForSequenceClassification', 'MegatronBertForSequenceClassification', 'MobileBertForSequenceClassification', 'MPNetForSequenceClassification', 'MvpForSequenceClassification', 'NezhaForSequenceClassification', 'NystromformerForSequenceClassification', 'OpenLlamaForSequenceClassification', 'OpenAIGPTForSequenceClassification', 'OPTForSequenceClassification', 'PerceiverForSequenceClassification', 'PLBartForSequenceClassification', 'QDQBertForSequenceClassification', 'ReformerForSequenceClassification', 'RemBertForSequenceClassification', 'RobertaForSequenceClassification', 'RobertaPreLayerNormForSequenceClassification', 'RoCBertForSequenceClassification', 'RoFormerForSequenceClassification', 'SqueezeBertForSequenceClassification', 'TapasForSequenceClassification', 'TransfoXLForSequenceClassification', 'XLMForSequenceClassification', 'XLMRobertaForSequenceClassification', 'XLMRobertaXLForSequenceClassification', 'XLNetForSequenceClassification', 'XmodForSequenceClassification', 'YosoForSequenceClassification'].
GPT-NeoX-Japaneseというモデルもあるはずなのですが…また勉強しよう。
npakaさんのサンプルに従って、推論させてみました。
prompt = "Q:まどか☆マギカでは誰が一番かわいい?\nA:"
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=100, min_new_tokens=100, do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
モデルが文章を出力する時に使っている確率分布を取り出してみます。
参考にしたqiitaによると…
generateメソッドの内部を参考にすると、モデルの出力するlogitsにsoftmaxを掛けたものを確率分布として扱っているようです。1この確率分布を取り出してみます。
prompt = "Q:まどか☆マギカでは誰が一番かわいい?\nA:"
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model(token_ids)
next_token_logits = output.logits[0, -1, :]
next_token_probs = torch.softmax(next_token_logits, dim=-1)
sorted_ids = torch.argsort(next_token_probs, descending=True, dim=-1)
for i in range(5):
print(f"{tokenizer.decode(sorted_ids[i])} ({100*next_token_probs[sorted_ids[i]]:.2f}%)")
ちなみに Tempartureってシャルルの法則とボルツマン分布からきてたことを知りました。
[まとめ]日本語LLMでGoogleColab課金しそうになったけどちゃんと踏みとどまって勉強しました。
なお同じような rinna vs CALMのインストールテストをからあげさんがDocker環境で成功していらっしゃいます。すばらしい。
というわけでGoogle Colabにお金を払わなくても、OpenCALM-1Bを使ってかなりの勉強ができることがわかりました。rinna-3.6Bも頑張れば動くのかもしれません。ちなみにGPT2や日本語BERTは動きます。感情分析もできていて勉強になりました。
▼Hugging Face Transformers を使って日本語 BERT モデルをファインチューニングして感情分析 (with google colab)
それでも無料で遊びたい人は… HuggingFace Spacesがある!
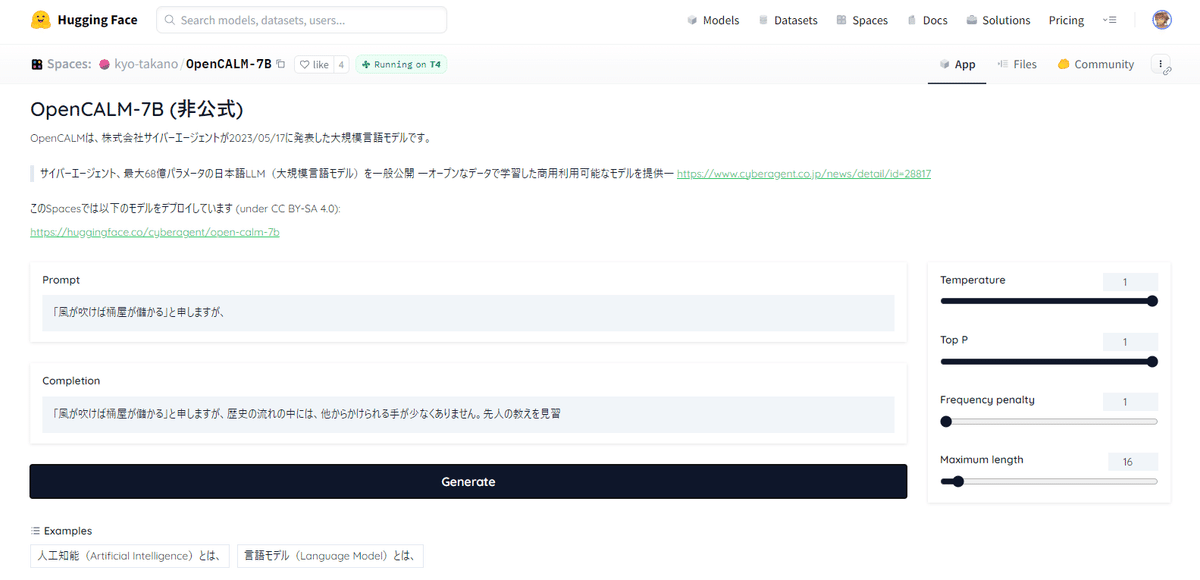
もうさっそく HuggingFace上のWebインタフェース"Spaces"でOpenCALM-7Bを動くようにしてくれた奇特な方がいらっしゃいます。一番でかいやつです。さすがオープンソース。KyoTakanoさんありがとうございます。
よく見ると上のほうに[Running on T4]と表示されているので、このかたが計算機代を払ってくれているのでしょうかね…。
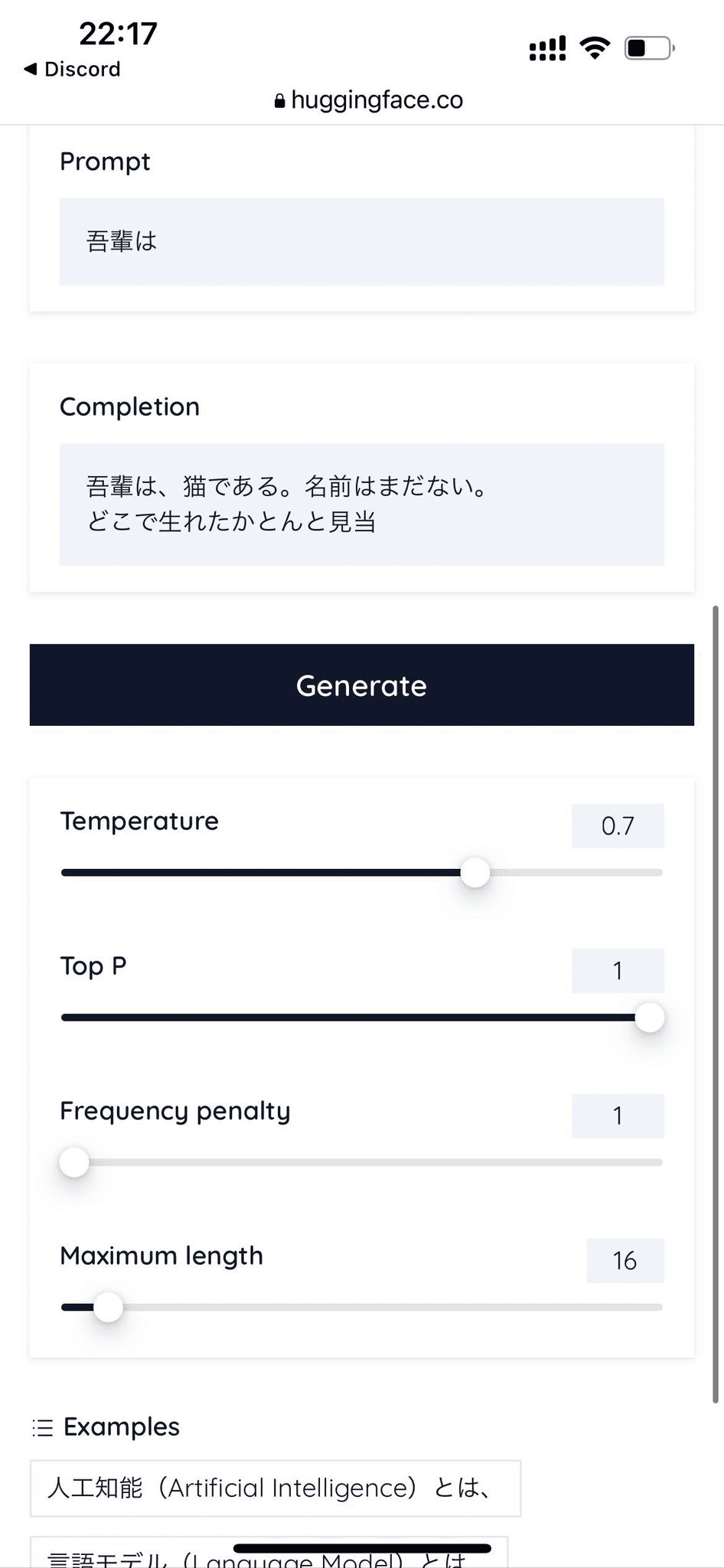
「吾輩は…」と打てば「猫である。名前はまだない」
スマホでも動きます。
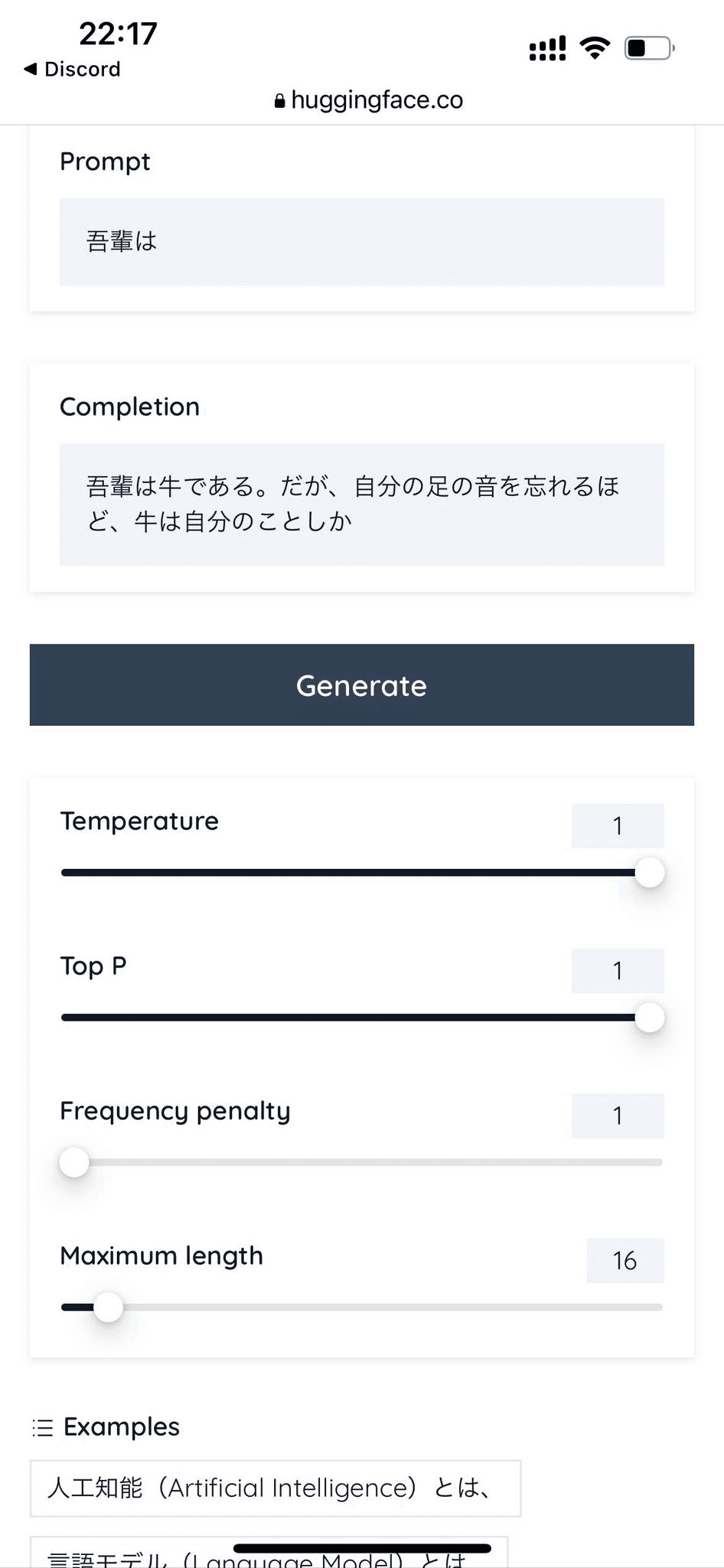
Tempartureを上げると「牛」になりましたが…。
以上です!何か間違ってたらコメントください!
参考文献
ここまで読んで、面白いと思った人はこちらの書籍がおすすめです。
npakaさんの本
▼BERT/GPT-3/DALL-E 自然言語処理・画像処理・音声処理 人工知能プログラミング実践入門
▼機械学習エンジニアのためのTransformers ―最先端の自然言語処理ライブラリによるモデル開発
日本語版はこんなタイトルですが、英語版(原作)は「Natural Language Processing With Transformers: Building Language Applications With Hugging Face」
つまりHuggingFaceを作った人達による書籍です。めちゃ分厚くて嚙みしめきれないお得感ある…。
こちらのHuggingFace公式日本語「NLP Course」もおすすめです!
最後に Google Colab での ipynbを共有します
https://colab.research.google.com/gist/kaitas/dee6986d56fa358aa18d2e2a9084e5af/opencalm-free.ipynb
おまけ:カバーイラストメイキング
今回は WebUIを使ってローカル生成しています。
ひまひま女子トモちゃんのファンアートを作るつもりだったのですが…

それはそれとしてうまくできたので、つぎはカバーアートのネタストックづくりです。同じプロンプトから生成しています。

その中からいい感じのレイアウトが生まれたのでこれをimage2imageで錬成します。


最後に高解像度化して完成です

今回の画像生成で新たなをコツを掴んだ感じします。
コツを掴んだかもしれない#ひまひま女子トモちゃん pic.twitter.com/tHHbJ2Njtk
— Dr.(Shirai)Hakase #AI神絵師本 #技術書典14 (@o_ob) May 17, 2023
まだまだ頑張れそう#ひまひま女子トモちゃん #ひまあーと pic.twitter.com/xqRlyKPf2a
— Dr.(Shirai)Hakase #AI神絵師本 #技術書典14 (@o_ob) May 17, 2023

いいなと思ったら応援しよう!
