
スマホでも使えるAI神絵師「Dream Studio」公式ガイドの和訳から学ぶ呪文の基本 #StableDiffusion

この記事は「人工知能とともに絵を描くという行為が人類にどんな影響を与えているか」というnoteの技術補足編になります。
Stable Diffusion 「Dream Studio」とは
話題のAI神絵師「Stable Diffusion」ですが、いつでもPCの前に座って作業ができる人は良いのですが、移動しながらでも手元のスマホで「あっ…このプロンプトを試してみたい…」って時があると思います。
そんな時、Dream Studio LiteというUIサービスを使っています。
基本はプロンプトを入力して「Dream」ボタンを押すだけです。

スマホでも使いやすいWebインターフェースになっているのが特徴です。
開発元は Stable Diffusion の開発グループの一部でもある Stability AI社が開発・運営しています。
Dream Studio UI解説
画面の解説をします。
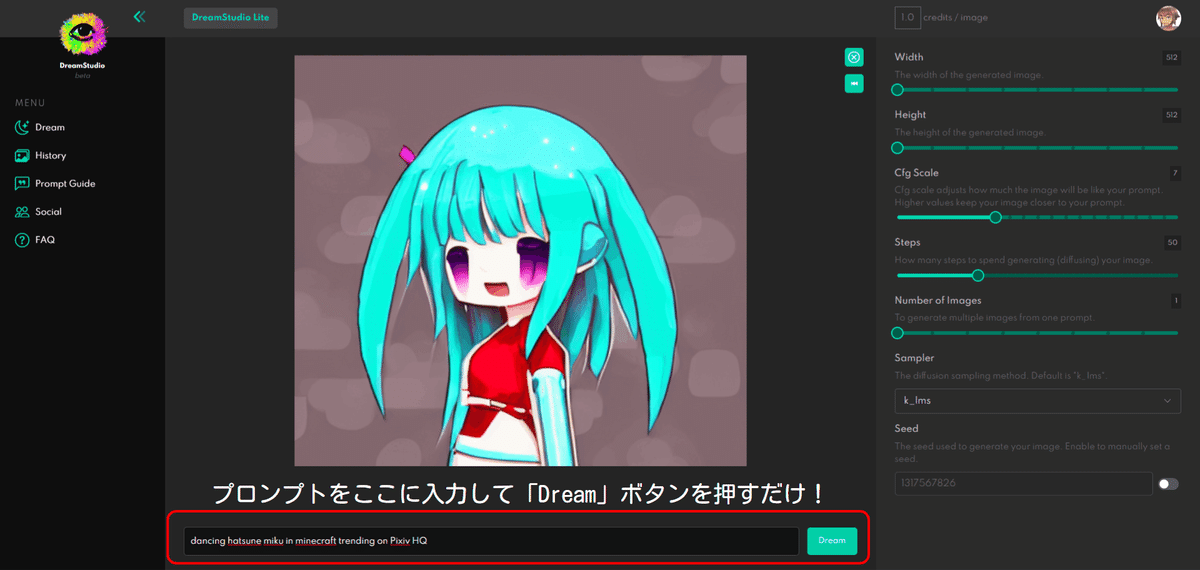
Width, Height:画像の解像度です。デフォルトは 512x512 pixels。最大は 1024x1024 pixels。クレジットを消費するので必要がないときは小さいほうが良いです。また小さくしておくほうが高速動作します。
Cfg Scale:画像がどの程度プロンプトと同じになるかを調整します。値を大きくすると画像はプロンプトに近くなります。
Steps:画像の生成過程での「Diffusion」に何回のステップを行うか?デフォルトでは 50 Steps です。10 Steps で 0.2 credits, 最大の 150 Stepsで3.0 credits を消費します。
Number of Images:これはめんどくさがりには良いですね。サイコロを同時にたくさん振ることができます。最大9件の画像を生成することができます。クレジット消費量の表示は変わりませんが、減るスピードがあっという間になりますのでご注意ください。
Sampler:k_lms(デフォルト), ddim, plms, k_euler, k_euler_oncestral, k_heun, k_dpm_2, k_dpm_2_oncestral で、Diffusion のサンプリング方式を指定します。
Seed:画像生成のための乱数シード、おそらく最初のガウスノイズの生成のために使われると推測します。つまり、このシード値を保存しておけば、そこそこに近い結果を検討することができるはずです。
利用料はどれぐらいかかるのか?
お値段的には {画像サイズ}x {Steps}の掛け算になっているようで、最大サイズの 1024x1024 pixels で Steps = {10, 25, 50, 75, 100, 150}としたときに、消費クレジットはそれぞれ{1.9, 4.7 , 14.1, 18.8, 28.2 }となっています。1000 クレジットが 10ポンドなので、1617.8 円。1クレジットあたり16.178円(2022/8/31のレート)。
デフォルトだと17円/生成。最大でも457円/生成、ということになります。
プロンプトエンジニアリングの基本(公式ガイドの参考訳)
【著者: @Graverman 】https://twitter.com/dailystablediff
以下参考訳です。
初心者がテキストから画像を生成するAIを使って、より良い画像生成するための簡単な公式を提案します。
これは Stable Diffusion でテストされましたが、十分なアートデータで訓練されていれば、どんなモデルでも使えるはずです。
このドキュメントを読み、これらの簡単なステップを適用した後、あなたは同じ労力でより良い画像を生成することができるようになります。
1. 生のプロンプト
生のプロンプト(Raw Prompt) とは、例えば、生成したいものを記述する最もシンプルな方法です。
パンダ「Panda」, 剣を持った戦士「A warrior with a sword」,スケルトン「Skeleton」
これはプロンプトの基本的な構成要素です。ほとんどの初心者は、生のプロンプトだけを使うことから始めますが、これは通常間違いです。
このようにして生成された画像は、ランダムで無秩序になる傾向があるからです。以下は、私が以前のプロンプトを実行して生成した例です。

見てわかるように、これらの画像は風景が不規則で、とても美的センスがあるとは思えません。ここで、次のポイントに移ります。
2. スタイル
スタイルは、プロンプトの重要な要素です。AIは、指定されたスタイルがない場合、通常、関連する画像で最も多く目にしたものを選択します。
例えば、私が風景を生成した場合、おそらくリアルな画像や油絵のような画像を生成することでしょう。
スタイルは生のプロンプトの直後に画像に最も影響を与えるため、よく選ばれたスタイルと生のプロンプトを持つだけで十分な場合があります。
最も一般的に使用されるスタイルは……
リアリスティック「Realistic」,
油絵「Oil painting」,
鉛筆画「Pencil drawing」,
コンセプトアート「Concept art」,
これらのスタイルをどのように使うか、1つ1つ検証していきます。
リアルな画像の場合、そのスタイルには様々な方法があり、ほとんどが似たような画像に仕上がります。
ここでは、よく使われる写実的な画像にするためのテクニックを紹介します。
ある写真+生のプロンプト「a photo of + raw prompt」
フォトグラフ+生のプロンプト「a photograph of + raw prompt」
生のプロンプト、ハイパーリアリスティック「raw prompt, hyperrealistic」
生のプロンプト、リアリスティック「raw prompt, realistic」
もちろん、これらを組み合わせることで、よりリアルな画像を得ることができます。
油絵を取得するには、プロンプトに「an oil painting of」を追加するだけです。
この場合、フレーム内の油絵が表示されることがありますが、これを修正するには、プロンプトを再実行するか、生プロンプト + 油絵「oil painting」を使用することができます。
鉛筆画を作成するには、生のプロンプトに「a pencil drawing of」を追加するか、生のプロンプト+「pencil drawing」とするだけです。
風景画の場合も同様です。
3. アーティスト
自分のスタイルをより具体的にしたり、イメージをより一貫したものにするために、プロンプトにアーティストの名前を使用することができます。
例えば、非常に抽象的なイメージにしたい場合は、「パブロ・ピカソ作」“made by Pablo Picasso” または単に ピカソ「Picasso」と付け加えるとよいでしょう。
以下に、さまざまなスタイルのアーティストのリストを掲載しますが、新しいアートを発見するクールな方法として、常にさまざまなアーティストを検索することをお勧めします。
ポートレート:John Singer Sargent, Edgar Degas, Paul Cézanne, Jan van Eyck
油絵:Leonardo DaVinci, Vincent Van Gogh, Johannes Vermeer, Rembrandt
鉛筆・ペン画:Albrecht Dürer, Leonardo da Vinci, Michelangelo, Jean-Auguste-Dominique Ingres
風景画:Thomas Moran, Claude Monet, Alfred Bierstadt, Frederic Edwin Church
作家を混ぜることは、面白い作品を作ることにつながるので、大いに推奨されます。
4. 仕上げ
この部分は、人によっては極端になり、この記事よりも長いプロンプトを作ることもあります。
仕上げ(Finishing touches)とは、プロンプトを自分の好きなように仕上げるために、最終的に追加するもののことです。
例えば、よりアーティスティックなイメージにしたい場合は、アートステーションで流行っている「trending on artstation」(www.artstation.com)を追加します。
よりリアルなライティングを追加したい場合は、「Unreal Engine」を追加します。何を加えてもいいのですが、以下に例を挙げます。
高精細「Highly detailed」、シュールレアリズム「surrealism」、アートステーションのトレンド「trending on art station」、トライアド配色(色相環を使った3角配色のこと)「triadic color scheme」、スムーズ「smooth」、シャープフォーカス「sharp focus」、マット「matte」、エレガント「elegant」、今まで見た中で最も美しい画像「the most beautiful image ever seen」、イラスト「illustration」、デジタルペイント「digital paint」、暗い「dark」、陰鬱「gloomy」、「octane render」( Cinema4D や Blender に使われている Otoy社製の高品質レンダリングエンジン)、8K、4K、ウォッシュドカラー「washed colors」、シャープ「sharp」、ドラマチックライティング「dramatic lighting」、美しい「beautiful」、ポストプロセス「post processing」、今日の写真「picture of the day」、環境照明「ambient lighting」、叙事詩的構図「epic composition」……。
5. まとめ
プロンプトエンジニアリングは、画像がどのように見えるかをよりよく制御することができます。
(正しい方法で行えば)あらゆる面で画質が向上します。
(こちらは原作の翻訳ですが)もしこのガイドの改善があれば、ぜひdiscord(Graverman#0804)で教えてください。
各パラメータの違いを試してみる
さて、プロンプトエンジニアリングについては前節の公式ガイドの翻訳で割愛するとして、
Dream Studio 各パラメータはどのような意味を持つのでしょうか。
Cfg Scaleを最大値20(=揺らぎなし) にして、Stepsを最小の 10 から、デフォルトの 50, 最大の 150に変化して、2種類のプロンプトで観察したいと思います。

他は全て同じパラメータ, Seed = 1457915964。
【Galaxy】「A dream of a distant galaxy, by Caspar David Friedrich, matte painting trending on artstation HQ」(起動時のデフォルト呪文)
Stepsが増えると細部の描写が細かくなる。画の派手さ(星の輝き)は減る、脚の本数や山の描写は謎。【Miku】「Dancing Hatsune Miku in Minecraft Trending on pixiv HQ」
Stepsが少なすぎるとボケ過ぎ。右上のハートはなぜ生まれたのか?
同様にサンプラーも変更してみましたが、この条件{Cfg Scale = 20, Steps = 50, Number of Images = 1, Seed = 1457915964 }では違いは判りませんでした。

おまけ:Stable Diffusion を 手元で動かしたい
せっかく無料で使える Stable Diffusion です。Dream Studio のような有料のUIではなく、Google Colaboratory を使って無料の Python 環境で利用してみたいと思います。
必要になるのはこれらのURLです。
HuggingFaceにおいて、CompVisの Stable Diffusion v1-4 データセット(Model Card)を無償で使うことができます。
Stable Diffusion v1-4 ライセンス
せっかくなのでライセンスも読んでいきましょう。
CreativeML OpenRAIL Mライセンスは、BigScienceとRAIL Initiativeが責任あるAIライセンスの領域で共同で行っている作業から適応された、OpenRAIL Mライセンスです。
私たちのライセンスのベースとなった BLOOM Open RAILライセンスについての記事もご覧ください。
モデルの説明
テキストプロンプトに基づく画像の生成・修正に利用できるモデルです。
Imagenの論文で提案されているように、事前に学習した固定テキストエンコーダー(CLIP ViT-L/14)を使用する潜在拡散モデルです。
Stable Diffucion V1-4: 制限事項とバイアス
せっかくなので制限事項も翻訳しておきます。
【制限事項】
完全なフォトリアリズムを実現するものではない。
読みやすいテキストをレンダリングすることができない。
「青い球の上に赤い立方体が乗っている」ような、合成を伴う難しいタスクではうまく動作しない。
顔や人物全般が適切に生成されない場合がある。
このモデルは主に英語のキャプションで学習させたので、他の言語ではうまく動作しない。
モデルのオートエンコーダ部分はロッシーです(lossy=データ失われる)。
このモデルはアダルトコンテンツを含む大規模データセットLAION-5Bで学習させたもので、追加の安全機構や考慮なしに製品使用するには適しません。
データセットの重複排除のための追加的な手段は用いていません。つまり学習データで重複している画像について、ある程度の重複記憶が観察されています。
学習データは、https://rom1504.github.io/clip-retrieval/ 重複記憶された画像の検出を追跡検索することができます。
【バイアス】
画像生成モデルの性能は素晴らしいものですが、社会的バイアスを強化したり悪化させたりする可能性もあります。Stable Diffusion v1は、主に英語表記に限定された画像からなるLAION-2B(en)のサブセットで学習されました。他の言語を使用するコミュニティや文化からのテキストや画像は、十分に説明されていない可能性があります。これは西洋文化がデフォルトとして設定されることが多いため、モデル全体の出力に影響を及ぼします。さらに、英語以外のプロンプトを使用した場合のモデルのコンテンツ生成能力は、英語のプロンプトを使用した場合よりも著しく劣ります。
技術書典13 に出展します!
以上でStable Diffusion / Dream Studio 公式ガイドの日本語訳+ちょっとした解説と実験を終わります。
なお宣伝ですが、
グリー技術書典部誌 2022秋号
「AIとコラボして人気絵師になる」
30ページぐらいあります
目次紹介↓
#技術書典 技術書典13ひとまず脱稿しました!
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) August 30, 2022
グリー技術書典部誌 2022秋号
「AIとコラボして人気絵師になる」
30ページぐらいあります#技術書典13 #stablediffusion https://t.co/vNFB7YUAAO pic.twitter.com/MfSQn0Laqq
電子版も9月10日に予定しているそうなので、こちらのグリー技術書典部@BOOTHをフォローして待っててね!
何かありましたらこちらのアカウントでご連絡いただければ幸いです。
日本の改正著作権法30条4項についての例外性を追記しておきました
— Dr.(Shirai)Hakase/Metaverse UX Dev/R&D (@o_ob) September 1, 2022
なお続編については、こちらのnoteと技術書典部13で9/10ごろ公開予定です。
■人工知能とともに絵を描くという行為が人類にどんな影響を与えているか(1)https://t.co/UQIxuGTNJr
この記事が気に入ったらサポートをしてみませんか?