
札幌市内の累計降雪量・積雪深を可視化する

こんばんは( ´ ▽ ` )ノ
私のような雪国に住んでいる人間にとって、その年の積雪量次第で生活が変わってくるぐらい影響の大きいものだと思うのは私だけですかね?
雪の影響を受けない地下鉄沿線居住だったり、雪かきを行わない人とかだと、そんなに気にしないのかもしれませんが。
札幌市では、こちらのサイトで市内14地点の累積降雪量・積雪深が毎日更新されています。
札幌管区気象台以外の地点は、土木センターや水再生プラザといった市保有の施設で観測されているようです。
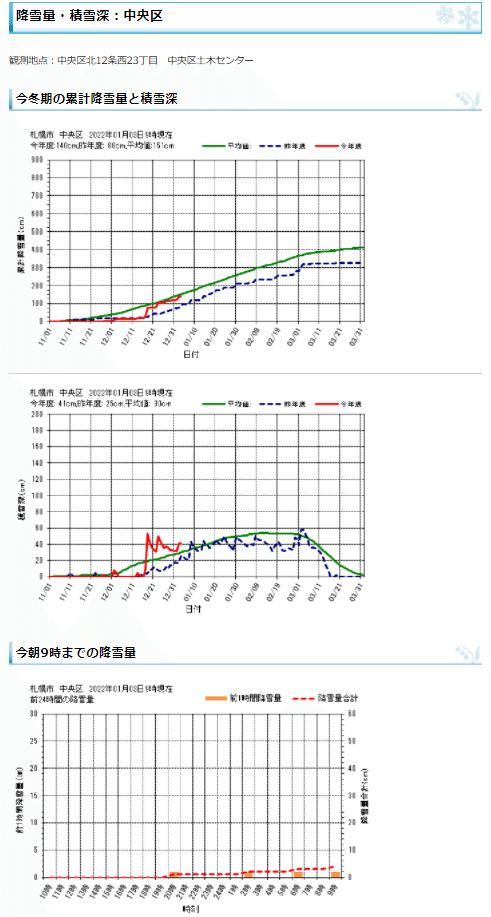
こんな感じで、累積降雪量・積雪深と過去24時間の1時間ごとの降雪量が見られるようになっています。
また、こちらのサイトでは平成17年度(2005年度)以降の観測データをダウンロードできるようになっています。
本投稿では、この観測データを使用して、過去及び今年度の札幌市内の累計降雪量・積雪深を、公開されている内容とは異なる視点で可視化していく過程をまとめていきます。
■1.観測データを確認する
まずは観測データがどのようなものなのかを、ダウンロードして確認します。
▼降雪量データ

観測地点ごとの、その日の降雪量のようですね。
データが取得できず、欠損値となっている日があることも考慮する必要がありそうです。
観測地点は、札幌管区気象台を除く13地点で、平成29年度以前は10地点。
▼積雪深データ

観測地点ごとの、その日時点での積雪深のようです。
降雪量データと同じように、欠損値となっている日があることも考慮する必要がありそうです。
観測地点も降雪量データと同様のようです。
■2.何を可視化するのかを決める
次に、何を可視化するのかを決めます。
札幌市が公開している最新データでは観測地点ごとの累積降雪量及び積雪深を見ることができますが、それぞれ別ページなので、どの地点が多いのかなど、全地点を俯瞰したものとしては見れません。
そこで、まずは全地点の累積降雪量及び積雪深をそれぞれ一つのグラフとして俯瞰できるように可視化したいと思います。
■3.前処理
可視化を行う上で必要かつ、もっとも手数がかかるのが前処理と呼ばれる工程。
具体的には元のデータを可視化できる形式に加工していく作業となります。
▼3.1.観測データのURL一覧を取得する
観測データをダウンロードできるサイトは下記の通りとなっており、一つのページから全てのデータがダウンロードできるようになっています。

手作業で行うのであれば、それぞれのリンクをクリックして...を繰り返せばいいのですが、今回はスクレイピングという技術を用いて、ダウンロードできるURLの一覧を取得して処理するようにしたいと思います。
Pythonで関数化したコードを書くと以下の感じになります。
# データ取得するURLのlistを取得する
def get_url_list():
# データ取得元URL
DATA_URL = 'https://www.city.sapporo.jp/kensetsu/yuki/weather-data.html'
# 指定サイトをスクレイピングしてhtmlを取得
f = urlopen(DATA_URL)
html = BeautifulSoup(f.read().decode('utf-8'), "html.parser")
# 取得するデータ(xlsファイル)はtableタグの中にURLへのリンクが含まれている
table_list = html.find_all('table')
# 相対URLのlist
a_list = []
for table in table_list:
a_list.append(table.find_all('a'))
# 2次元のリストを平坦化する
a_list = list(itertools.chain.from_iterable(a_list))
# URLを相対→絶対に変換
BASE_URL = 'https://www.city.sapporo.jp'
url_list = []
for a in a_list:
url_list.append(BASE_URL + a['href'])
return url_listこのコードで取得できるURLのリストは以下のようになります。
['https://www.city.sapporo.jp/kensetsu/yuki/documents/snowfall_r03.xls', 'https://www.city.sapporo.jp/kensetsu/yuki/documents/snowdepth_r03.xls', 'https://www.city.sapporo.jp/kensetsu/yuki/documents/snowfall_r02.xls', 'https://www.city.sapporo.jp/kensetsu/yuki/documents/snowdepth_r02.xls', 'https://www.city.sapporo.jp/kensetsu/yuki/documents/snowfall_r01.xls',・・・, 'https://www.city.sapporo.jp/kensetsu/yuki/documents/snowfall_h27.xls', 'https://www.city.sapporo.jp/kensetsu/yuki/documents/snowdepth_h27.xls']このリストを使って、観測データを取得していきます。
▼3.2.データ加工(1)~別々になっている年月日を1つの項目にまとめる
まずは、観測データを取得する部分から。
def main():
# データ取得するURLのlistを取得する
url_list = get_url_list()
# URLごとに処理する
for url in url_list:
# EXCELを読み込む(4行目がヘッダ)
df = pd.read_excel(url, header=4)先の項で作成した関数を呼び出して取得したURLのリストごとに処理する形式にしています。
read_excelという関数を呼び出すことで、EXCELを直接区切り文字形式のデータに変換しています。
事前に確認した元データのEXCELは、4行目までが説明で実際のデータは項目ヘッダとなる5行目からなので、5行目をヘッダ行に指定し、それ以降を読み込むことに。(0から数えるコード仕様なのでコード上ではheader=4となっています)
ここから可視化できる形式に加工していきます。
まずは、グラフにする上では扱いづらい、別々になっている年月日を1つの項目にまとめます。
df.insert(0, '年月日', pd.to_datetime(df['年'].astype(str).str.cat([df['月'].astype(str), df['日'].astype(str)], sep=' ')))
df.drop(columns=['年', '月', '日'], inplace=True)年月日を繋げた項目を先頭に追加して、元々あった年、月、日の項目を削除しています。
扱うデータがすべて同じ形式であればこれでOKなんですが、今回は使用しませんが取得できるデータの中に過去5年の平均値を持っているものがあり、それは以下のように年を持っていないため、このままではエラーになってしまいます。

対応として、年、月、日が揃っている場合のみ年月日を繋げた項目を追加するようにしました。
# 各年のデータと5年平均のデータでレイアウトが異なる
# 必須カラムを定義し、存在有無で処理分岐する
required_columns = {'年', '月', '日'}
# 各年のデータの場合は、別々のカラムになっている年月日を一つのカラムで再定義する
if required_columns <= set(df.columns):
df.insert(0, '年月日', pd.to_datetime(df['年'].astype(str).str.cat([df['月'].astype(str), df['日'].astype(str)], sep=' ')))
df.drop(columns=['年', '月', '日'], inplace=True)▼3.3.データ加工(2)~欠損値を補間する
次に欠損値を補間していきます。
データ仕様としては「X」が欠損値でそれのみを補間すればよいと考え、
df.replace('X', np.nan, inplace=True) # 欠測値を補間できるようにするために置き換え
df.interpolate(limit_direction='both', inplace=True) # 線形補間こんな感じで、「X」をコード上で欠損値と判断できる値に置き換えてから、線形補間という手法で欠損値を補間したのですが、ある一年だけ最終的にグラフにした際に表示がおかしくなってしまい...原因を調べたところ、下記のように観測値になぜか日付が混入していることがわかりました...なんでやねん

オープンデータを色々見てくると、こういうのは結構ありまして、問題のあるデータを的確に素早く見つけて対処できるスキルが、データ分析業には必要なんだということを実感させられます。
# 欠測値を線形補間する
# Note:データ仕様上の欠損値であるXと、数値として認識できない値も欠損値として処理する
# 数値として認識できない値がある列を抽出
mask = df.apply(lambda s:pd.to_numeric(s, errors='coerce')).notnull().all()
mask = mask[~mask]
for val in mask.index:
df[val] = pd.to_numeric(df[val], errors='coerce') # 数値として認識できない値は欠損値(nan)が入る
df.interpolate(limit_direction='both', inplace=True) # 線形補間最終的なコードとしては上記のようになりました。
もっとエレガントな書き方があるように思いますが、今回必要とするデータは数値のみですので、数値として認識できない列(データ上は観測地点ごとの数値)を抽出し、その列にだけ数値として認識できない値をコード上で欠損値と判断できる値に置き換えてから、線形補間という手法で欠損値を補間するようにしました。
▼3.4.EXCEL形式のファイルをタブ区切り形式で保存する
ここまで来たらあともう少しです。
加工後のデータをタブ区切り形式のファイルとして保存します。
# データ保存先ディレクトリ
DATA_DIR = 'data/'
# タブ区切りファイルで保存する
file_name = url[url.rfind('/') + 1:]
file_name = file_name.replace('.xls', '.tsv')
df.to_csv(DATA_DIR + file_name, sep = '\t', index = False)元々のファイル名の拡張子部分をタブ区切りを表す、'tsv'に置き換えて保存しています。
年月日 中央区 北区(太平) 北区(あいの里) 東区 白石区 厚別区 豊平区 清田区 南区(南31条西8丁目) 南区(定山渓) 西区(西野) 西区(平和) 手稲区
2021-01-01 17 38 42 30.0 19 30 15 17.0 14 42 24 27 24
2021-01-02 18 36 38 28.0 19 29 18 20.0 18 51 24 29 24
2021-01-03 25 52 57 44.0 33 38 25 27.0 22 45 29 29 27
2021-01-04 26 47 51 39.0 28 34 22 24.0 20 46 30 30 25
2021-01-05 23 43 48 36.0 25 33 20 22.0 19 50 27 29 23
2021-01-06 21 43 55 35.0 25 31 20 21.0 18 46 25 27 23
2021-01-07 21 43 50 36.0 25 31 20 21.0 18 44 26 29 25
2021-01-08 43 58 50 51.0 42 48 37 42.0 37 69 48 61 41
2021-01-09 37 53 47 45.0 37 42 32 37.0 32 69 42 52 38
2021-01-10 34 50 45 42.0 35 40 30 34.0 30 65 39 48 37保存されたファイルの中身はこんな感じ。
区切り文字には通常', '(カンマ)が用いられることが多いですが、タブ区切りにすることでテキストエディタからスプレッドシートに直接コピペで貼り付けやすいので、私はタブ区切りを使うことが多いです。
▼3.5.降雪量から累積降雪量データを作成する
前処理の最後として、累積降雪量データを作成していきます。
先の項までで作成された降雪量データを用います。
# データファイルのlistを取得する
def get_file_list():
file_list = glob.glob(DATA_DIR + 'snowfall_*.tsv')
return file_list
def main():
# データファイルのlistを取得する
file_list = get_file_list()
# ファイルごとに処理する
for file in file_list:
df_data = pd.read_csv(file, sep='\t', header=0, encoding='utf-8')
df_data['年月日'] = pd.to_datetime(df_data['年月日'], format='%Y-%m-%d')
df_data.set_index('年月日', inplace = True)
save_file_name = os.path.splitext(os.path.basename(file))[0]
df_cumsum = df_data.cumsum()
df_cumsum.reset_index(inplace=True)
df_cumsum.to_csv(DATA_DIR + 'cumsum_' + save_file_name + '.tsv', sep = '\t', index = False)処理の流れとしては以下の通り。
・先の項までで保存されたタブ区切り形式のファイルから降雪量データの一覧を取得
・ファイルごとに観測地点ごとの降雪量の累積和を算出し、別ファイルとして保存する
以上の通りで難しいことはしていないのですが、ポイントとしては累積和の算出処理を簡単にするために、累積和を行わない年月日を一旦インデックスに退避させ、累積和の算出後に戻すところかなと。
年月日 中央区 北区(太平) 北区(あいの里) 東区 白石区 厚別区 豊平区 清田区 南区(南31条西8丁目) 南区(定山渓) 西区(西野) 西区(平和) 手稲区
2021-01-01 75 143 173 108.0 75 102 71 49.0 52 213 110 125 82
2021-01-02 77 144 173 110.0 76 105 76 55.0 58 226 114 130 84
2021-01-03 88 164 198 131.0 93 118 88 66.0 66 226 124 133 90
2021-01-04 95 164 200 131.0 93 118 88 66.0 68 229 133 139 90
2021-01-05 95 164 200 131.0 93 118 88 66.0 68 238 135 141 90
2021-01-06 95 167 209 133.0 93 118 88 66.0 68 238 135 141 91
2021-01-07 95 168 209 134.0 94 119 89 66.0 69 238 137 143 93
2021-01-08 119 186 218 152.0 114 138 109 90.0 90 268 161 182 110
2021-01-09 119 186 218 152.0 114 138 109 90.0 90 275 161 184 111
2021-01-10 119 186 218 152.0 114 138 109 90.0 90 277 161 185 111保存されたファイルの中身はこんな感じです。
■4.グラフを作成する
グラフを作成するところは特に変わったことは行っていないので、詳細は省略します。
作成されたグラフは以下の通り。
▼4.1.累積降雪量

▼4.2.積雪深

今回取り組んだ内容としては以上となります。
観測地点が多く、地点ごとの差があまり大きくないことからすべてを表示すると、グラフとしては見づらいかな...というのと、各年度のを見比べればわかることではあるんですが、その年の雪の量が多いのか少ないのかがパッと見でわかるようにしたいな...というのが残課題として残りました。
時間ができたら、この残課題に取り組みたいと思います。
この記事が気に入ったらサポートをしてみませんか?