
OpenAI API(GPT-3) 入門 (1) - 事始め

「OpenAI API」(GPT-3)の使い方をまとめました。
1. OpenAI API
「OpenAI API」は、OpenAIの最新の深層学習モデルにアクセスすることができるクラウドサービスです。「GPT-3」は、深層学習モデルそのものは公開されていないため、利用するには「OpenAI API」経由でアクセスする必要があります。「OpenAI API」は2021年5月現在ベータ版で、将来的には有料版としてリリースされる予定です。
「OpenAI API」は、汎用的な「テキスト入力 → テキスト出力」インターフェースのAPIです。使い方は簡単で、APIに自然言語で「タスクの説明」や「いくつかの回答例」を与えるだけで、そのコンテキストやパターンに一致するような回答が返されます。このAPIに与えるテキストを「プロンプト」、APIが生成するテキストを「コンプリーション」と呼びます。
2. OpenAI APIのベータ版の利用申請
OpenAI APIのベータ版の利用申請の手順は、次のとおりです。
(1) 「OpenAI API」のベータ版のサイト右上の「JOIN」から申請。
(2) 利用申請の許可がおりたら、「OpenAI API」のベータ版のサイト右上の「LOG IN」からログイン。
3. PlaygroundでのOpenAI APIの利用
「Playground」は、手軽に「GPT-3」を試すことができるWebページで、「OpenAI API」のベータ版のサイト内で提供されています。
「Playground」でのOpenAI APIの利用手順は次のとおりです。
(1) 「OpenAI API」のベータ版のサイトでログインし、「Playground」を開く。
(2) プロンプト領域に以下の文字列を入力して「Submit」ボタンを押す。
日本語を英語に翻訳します。
日本語: 吾輩は猫である
英語:成功すると、「I am a cat」が表示されます。違うテキストが表示される場合もあります。
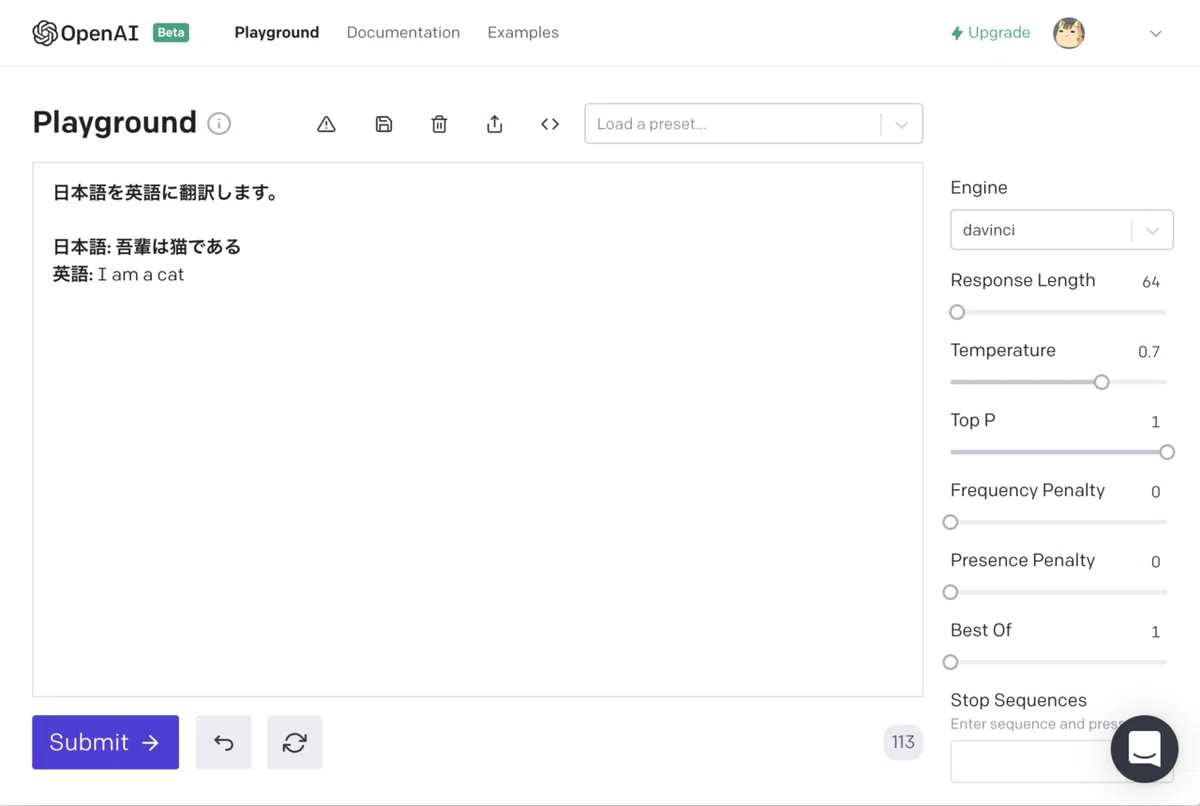
「I am a cat」以降の余分なテキスト生成が気になる場合は、「Stop Sequences」に「.」を指定してください。「.」が出現した時点でテキスト生成が停止します。
4. PythonでのOpenAI APIの利用
PythonでのOpenAI APIの利用の手順は、次のとおりです。
(1) 「OpenAI API」のベータ版のサイトでログインし、「APIキー」を取得。(2) Pythonの仮想環境を作成し、「openaiパッケージ」をインストール。
$ pip install openai(3) 以下のソースコードを作成し実行。
「<APIキー>」は、各自の「APIキー」に置き換えてください。「吾輩は猫である」の翻訳が返されます。
import openai
# APIキーの設定
openai.api_key = "<APIキー>"
# プロンプト
prompt = '''日本語を英語に翻訳します。
日本語: 吾輩は猫である
英語:'''
# 推論
response = openai.Completion.create(
engine='davinci',
prompt=prompt,
max_tokens=30,
stop='.')
print(prompt+response['choices'][0]['text'])I am a cat【おまけ】 Playgroundのパラメータ
・Engine: GPT-3のエンジン。davinciが最も精度が高く低速、adaが最も精度が低く高速(ada, babagge, curie, davinci)
・Response Length: 生成するトークンの最大数 (デフォルト:16, 最大:2048)
・Temperature: ランダムさ。創造的にするには0.9、答えがある場合は0推奨。top_pと同時変更は非推奨(デフォルト:0.7)
・Top P: nucleusサンプリング。0.1は、上位10%の確率を持つトークンのみが考慮を意味する。temperatureと同時変更は非推奨(デフォルト:1)
・Frequency Penalty: 生成したテキストに基づいて、新しいトークンに課すペナルティ。同じテキスト出力の可能性を減らす(デフォルト:0, 0〜1)
・Presence Penalty: 生成したトークンに基づいて、新しいトークンに課すペナルティ。同じトークンの繰り返し可能性を減らす(デフォルト:0, 0〜1)
・Best Of: サーバー側でbest_of個の結果を生成し、最良を返す(デフォルト:1)
・Stop Sequence: トークンの生成を停止する文章。最大4つ(デフォルト:なし)
・Inject Start Text: 書式補正のためコンプリーション前に追加するテキスト
・Inject Restart Text: 書式補正のためコンプリーション後に追加するテキスト
・Show Probabilities: トークンの生成される確率を色分けで表現
・Most Likely: 最も確率が高いものを色分け
・Liest Likely: 最も確率が低いものを色分け
・Full Spectrum: 両方を2色で色分け
【おまけ】 Completion.create()のパラメータ
・prompt: プロンプト。<|endoftext|>は、学習データで使われたドキュメントセパレータ(デフォルト:<|endoftext|>)
・engine: GPT-3のエンジン。davinciが最も精度が高く低速、adaが最も精度が低く高速(ada, babagge, curie, davinci)
・max_tokens: 生成するトークンの最大数 (デフォルト:16, 最大:2048)
・temperature: ランダムさ。創造的にするには0.9、答えがある場合は0推奨。top_pと同時変更は非推奨(デフォルト:1)
・top_p: nucleusサンプリング。0.1は、上位10%の確率を持つトークンのみが考慮を意味する。temperatureと同時変更は非推奨(デフォルト:1)
・frequency_penalty: 生成したテキストに基づいて、新しいトークンに課すペナルティ。同じテキスト出力の可能性を減らす(デフォルト:0, 0〜1)
・presence_penalty: 生成したトークンに基づいて、新しいトークンに課すペナルティ。同じトークンの繰り返し可能性を減らす(デフォルト:0, 0〜1)
・best_of: サーバー側でbest_of個の結果を生成し、最良を返す(デフォルト:1)
・stop: トークンの生成を停止する文章。最大4つ(デフォルト:null)
・n: 生成する結果数(デフォルト:1)
・echo: 結果に加えてプロンプトをエコーバック(デフォルト:false)
・stream: 進行状況をストリーミングバックするかどうか(デフォルト:false)
・logprobs: 選択トークンだけでなく、可能性の高いトークンにログ確率を含める。(デフォルト:null)
・logit_bias: 指定したトークンの可能性を減らす(デフォルト:null)
次回
この記事が気に入ったらサポートをしてみませんか?