
LangChain Chat のしくみ

「LangChain Blog」の記事「LangChain Chat」が面白かったので、簡単にまとめました。
1. LangChain Chat
「LangChain Chat」は、LangChainの文書の質問応答に特化したオープンソースなチャットボットです。
・Deployed Chatbot
・Deployed Chatbot on HuggingFace spaces
・Open source repo
過去数週間、多くの類似プロジェクトがありましたが、「LangChain Chat」には次のような点で独自性があるため、共有することにしました。
・文書の取り込み
・チャットボットのインタフェース
・出力形式の調整
・速度とパフォーマンスの調整
特に「チャットボットのインターフェース」は重要であり (ChatGPTの成功を見てください)、他の実装にはそれが欠けていると考えています。
2. 類似プロジェクト
多くの類似プロジェクトは、次のようなシステム構成で要約できます。
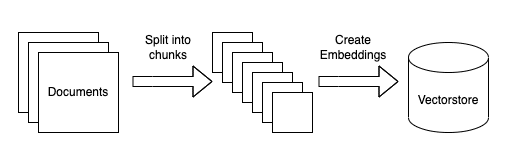
◎ 文書の取り込み
(1) 一連の文書を取り込む。
(2) それらを小さなチャンクに分割。
(3) 文書ごとに埋め込みを作成。
◎ クエリ
(1) クエリの埋め込みを作成。
(2) 埋め込み空間で最も類似した文書を見つける。
(3) これら文書を元のクエリと共に言語モデルに渡して、回答を生成。
他の良い例は、次のとおりです。
・GitHub support bot : 問題解決の点でLangChain Chatに最も似ている。
・Dr. Doc Search : 本 (PDF) との会話。
・Semantic Search Answers : いくつかのトピックについての適切な説明。
・Ask My Book : 現在のブームの火付け役。
3. 文書の取り込み
「文書の取り込み」には、2つ案がありました。「GitHub」または「インターネット」からのスクレイピングです。GitHubのファイルは操作しやすい形式 (markdown 等) もありますが、、操作しにくいもの (.ipynb 等) もありました。 そこで、「インターネット」からスクレイピングすることにしました。
HTMLの前処理は、最初は一般的な方法 (Beautiful Soup) で行いました。しかし、サイドバーのコンテンツが悪い結果を生み出していることがわかりました。以下の赤い領域は、新しい情報を提供していません。これらの領域を明示的に無視するようにパーサーを変更しました。

これはレイアウト特有のものではありますが、コンテキストとして、どのデータを含めるか (含めないか) について考慮することは、とても重要であると考えています。
4. チャットボットのインターフェイス
チャットボットのインターフェイスは、重要なUXである (ChatGPTの成功を見てください)と考えています。
類似プロジェクトで行われていない重要な機能の1つは、「Follow-up Question」 (相手が発した言葉を拾った質問を投げかけていくこと) です。これは、チャットベースのインターフェースにとって非常に重要な機能であると考えています。この問題を無視し、各質問を独立したものとして扱うと、誰かが自然な方法で「Follow-up Question」をしたい場合や、前の質問や回答の一部を参照したい場合にうまくいきません。
LangChainでこれを行う主な方法は、会話チェーンのメモリを使用することです。最も単純な実装では、前の会話の行がコンテキストとしてプロンプトに追加されます。しかし、これは私たちのユースケースでは少し破綻しています。なぜなら、私たちは会話履歴をプロンプトに追加するだけでなく、どの文書を取得するかの決定に使用することに関心があるからです。「Follow-up Question」をする場合、関連するドキュメントを取得するために、その「Follow-up Question」が何なのかを知る必要があります。
そこで、次のような新しいチェーンを作成しました。
(1) 会話履歴と新しい質問から、単一の独立した質問を作成。
(2) その質問を通常のベクター データベース質問応答チェーンで使用。

「Vector Database Question Answer Chain」でその質問を使用すると損失が発生し、コンテキストの一部が失われるのではないかと少し心配しましたが、実際には悪影響は見られませんでした。
この解決策にたどり着く過程で、「Vector Database」からのドキュメント取得に関して、いくつか試しましたが、ほとんどうまくいきませんでした。
・会話履歴と質問を一緒に埋め込む : 会話履歴が長くなると、大規模で過剰なインデックスを作成してしまう。
・会話履歴と質問を別々に埋め込み、結果を組み合わせる : 上記よりも優れているが、以前のトピックに関する情報をコンテキストに引き込みすぎる。
5. 出力形式の調整
「LangChain Chat」のユースケースでは、いくつかの重要な考慮事項がありました。
・回答には公式ソースを含める必要がある。
・回答にコードが含まれている場合、コードブロックとして適切にフォーマットする必要がある。
・チャットボットは答えがわからないことを率直に伝える必要がある。
次のプロンプトで、これらすべてを達成することができました。
You are an AI assistant for the open source library LangChain. The documentation is located at https://langchain.readthedocs.io.
You are given the following extracted parts of a long document and a question. Provide a conversational answer with a hyperlink to the documentation.
You should only use hyperlinks that are explicitly listed as a source in the context. Do NOT make up a hyperlink that is not listed.
If the question includes a request for code, provide a code block directly from the documentation.
If you don't know the answer, just say "Hmm, I'm not sure." Don't try to make up an answer.
If the question is not about LangChain, politely inform them that you are tuned to only answer questions about LangChain.
Question: {question}
=========
{context}
=========
Answer in Markdown:このプロンプトでは、Markdown 形式で応答を要求しています。これにより、適切な見出し、リスト、リンク、およびコード ブロックを使用して、視覚的に魅力的な形式で回答を表示できます。
Next.jsフロントエンドでは次のようになります。

各回答のハイパーリンクは、プロンプトで前もって提供しているドキュメントへのベースURLを使用して構築されています。データ取り込みパイプラインでドキュメントのWebサイトをスクレイピングしたので、回答へのパスを特定し、それをベースURLと組み合わせて、動作するリンクを作成することができます。
チャットボットの正確性をできるだけ保つために、temperatureを0に保ち、答えが不明確な質問をされた場合は、「Hmm, I’m not sure.」(うーん、よくわからない) と言うようにプロンプトに指示を入れています。また、LangChainに関すること以外の質問は断るという指示も入れています。
6. 速度とパフォーマンスの調整
長いMarkdownの回答のテストでは、質は素晴らしいものでしたが、回答時間は希望より若干長くなりました。パフォーマンスを向上させるために、プロンプトを改良し、さまざまなキーワードと文構造を試すことに多くの時間を費やしました。
1つの方法は、プロンプトの最後に「Markdown」キーワードを記載することでした。このユースケースでは、キーワードが1つだけ言及されている書式設定された出力を返すことができました。
プロンプトの先頭近くにベース URLを提供すると、全体的なパフォーマンスが向上しました。これにより、モデルに回答に含める最終URLを作成するための作業参照が提供されます。
「hyperlinks」の代わりに「hyperlink」、「code blocks」の代わりに「code block」などの単数形を使用すると、応答時間が改善されることがわかりました。