
Google Colab で DragNUWA を試す

「Google Colab」で「DragNUWA」を試したので、まとめました。
【注意】Google Colab Pro / Pro+で動作確認しました。
1. DragNUWA
「DragNUWA」は、テキスト・画像・軌跡から動画を生成するAIモデルです。
3つの制御要素を利用することで、意味論的、空間的、時間的側面から高度に制御された動画を生成することが可能です。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/ProjectNUWA/DragNUWA.git
%cd DragNUWA
!pip install -r environment.txt(2) モデルをmodelsフォルダにダウロード。
ウェイトがダウンロードできない場合は、こちらから直接ダウンロードします。
!pip install git+https://github.com/wkentaro/gdown.git
!gdown https://drive.google.com/uc?id=1Z4JOley0SJCb35kFF4PCc6N6P1ftfX4i -O models/drag_nuwa_svd.pth(3) DragNUWA_demo.pyの最終行を以下のように書き換える。
demo.launch(server_name="0.0.0.0", debug=True)↓
demo.launch(server_name="0.0.0.0", debug=True, share=True)(4) WebUIの起動。
# WebUIの機能
!python DragNUWA_demo.py(5) 「https://XXXX.gradio.live」のリンクが表示されたらクリック。

(6) 「Upload Image」ボタンで画像をアップロード。
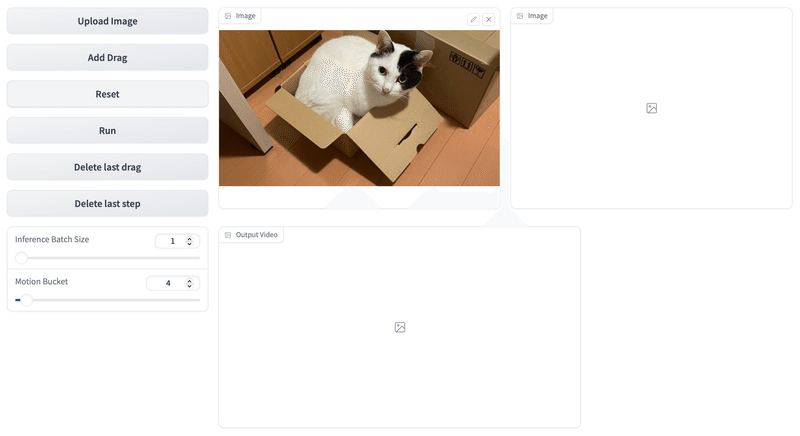
(7) 「Add Drag」ボタンを押した後、画像を2回(以上)クリックして軌跡を追加。
マウスのドラッグ操作では追加できません。
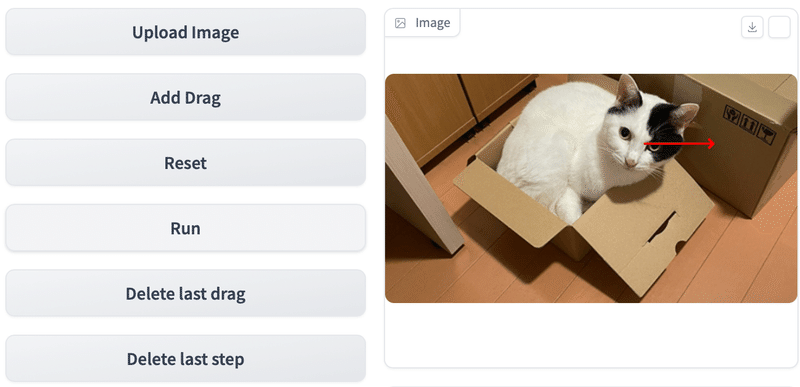
(8) 「Run」ボタンを押す。
40秒ほどで動画が生成されます。
DragNUWAを試す。https://t.co/EAOg8gh6Yc pic.twitter.com/KtyKp4Q3vq
— 布留川英一 / Hidekazu Furukawa (@npaka123) January 9, 2024
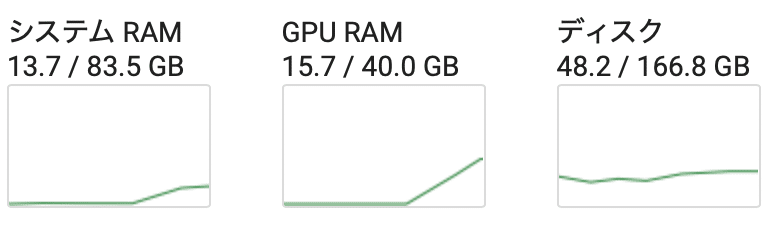
メモリ消費量は、次のとおり。
この記事が気に入ったらサポートをしてみませんか?