Google Colab で GPT4ALL を試す

「Google Colab」で「GPT4ALL」を試したのでまとめました。
1. GPT4ALL
「GPT4ALL」は、LLaMAベースで、膨大な対話を含むクリーンなアシスタントデータで学習したチャットAIです。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) 新規のColabノートブックを開く。
(2) Googleドライブのマウント。
Colabインスタンスに大きなファイルをアップロードするのは大変なのでGoogleドライブを使ってます。
# Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')(3) 作業フォルダへの移動。
# 作業フォルダへの移動
import os
os.makedirs("/content/drive/My Drive/work", exist_ok=True)
%cd '/content/drive/My Drive/work'(4) GPT4ALLのクローン。
# GLT4ALLのクローン
!git clone https://github.com/nomic-ai/gpt4all.git(5) モデルをダウンロードして、「gpt4all/chat」フォルダに配置。
公式ページで紹介されているDirectLinkから「pt4all-lora-quantized.bin」をダウンロードします。
・https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
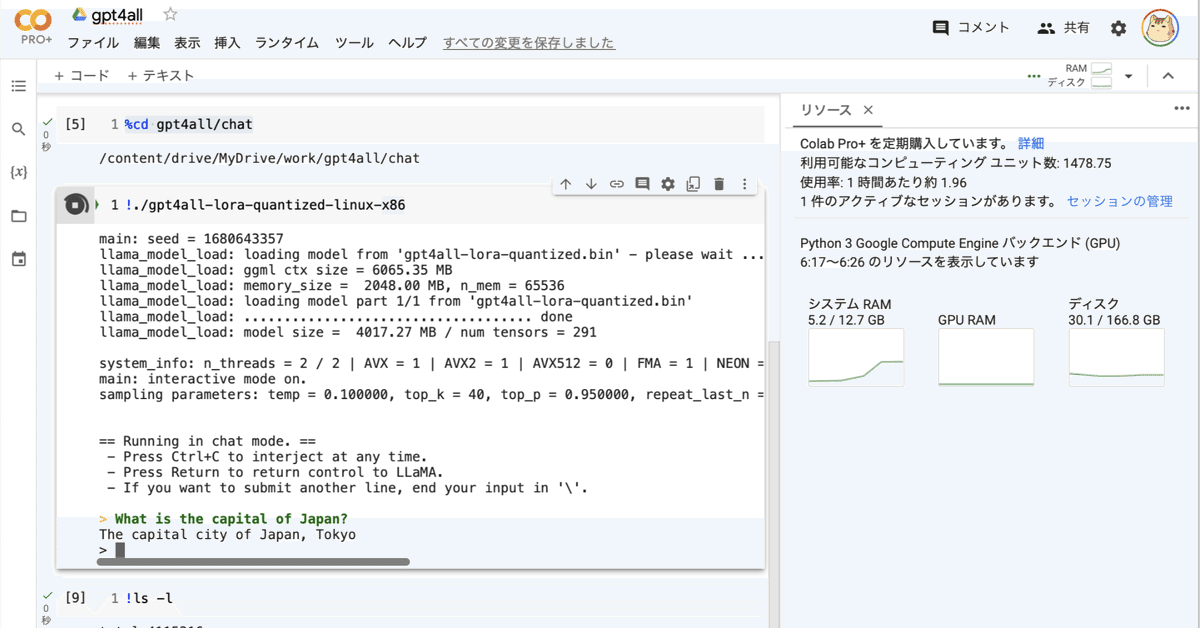
(6) 「GPT4ALL」の実行。
# GPT4ALLの実行
%cd gpt4all/chat
!chmod u+x ./gpt4all-lora-quantized-linux-x86
!gpt4all-lora-quantized-win64main: seed = 1680643357
llama_model_load: loading model from 'gpt4all-lora-quantized.bin' - please wait ...
llama_model_load: ggml ctx size = 6065.35 MB
llama_model_load: memory_size = 2048.00 MB, n_mem = 65536
llama_model_load: loading model part 1/1 from 'gpt4all-lora-quantized.bin'
llama_model_load: .................................... done
llama_model_load: model size = 4017.27 MB / num tensors = 291
system_info: n_threads = 2 / 2 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 |
main: interactive mode on.
sampling parameters: temp = 0.100000, top_k = 40, top_p = 0.950000, repeat_last_n = 64, repeat_penalty = 1.300000
== Running in chat mode. ==
- Press Ctrl+C to interject at any time.
- Press Return to return control to LLaMA.
- If you want to submit another line, end your input in '\'.
> What is the capital of Japan?
The capital city of Japan, Tokyo
> こんにちは
Konnichiwa (or Kon'nichi wa) means "hello" in Japanese. It can also be used as a greeting or farewell to someone you just met for the first time. 操作方法は、次のとおりです。
・Ctrl+C を押して、いつでも割り込み。 (Colabでは停止ボタン)
・Returnで制御を LLaMA に戻す。
・別の行を入力する場合は、入力を「\」で終了。
実行ファイルは、OSごとに異なります。
・M1 Mac/OSX : ./gpt4all-lora-quantized-OSX-m1
・Linux : ./gpt4all-lora-quantized-linux-x86
・Windows (PowerShell) : ./gpt4all-lora-quantized-win64.exe
・Intel Mac/OSX : ./gpt4all-lora-quantized-OSX-intel
ファイルの実行権限なかったのでchmodしてます。
関連
この記事が気に入ったらサポートをしてみませんか?