
MarLÖ : マインクラフトの強化学習環境

1. MarLÖ
「MarLÖ」は、マインクラフトの強化学習環境です。金の鉱石を発見する、Mobを捕まえるなどの、マインクラフトに関するタスクに挑戦します。OpenAI GymのGymインタフェースを利用して学習させることができます。
2. MarLÖのタスク
◎MarLo-MazeRunner-v0

【説明】
迷路を抜けてレッドストーンの柱への到達するタスクです。
【観察】
エージェントが使用する深度マップが提供されます。これにより、このタスクが簡単になります。
【行動】
・Jump
・Move
・Pitch
・Turn
・Crouch
・Attack
・Use
【報酬】
なし
◎MarLo-CliffWalking-v0
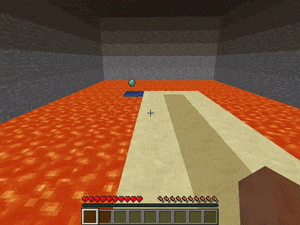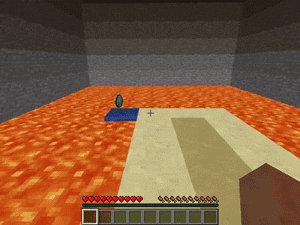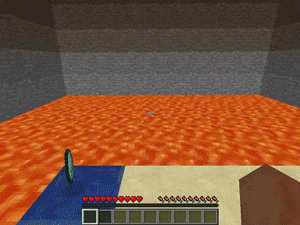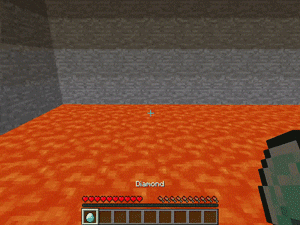
【説明】
崖の迷路の端に置かれているダイヤモンドを拾うタスクです。
崖は溶岩に囲まれ、地形には穴が開いてます。
【行動】
・Move
・Jumpmove
・Strafe
・Turn
・Movenorth, Moveeast, Movesouth, Movewest
・Jumpnorth, Jumpeast, Jumpsouth, Jumpeast
・Jump
・Look
・Use
・Jumpuse
【報酬】
溶岩に落ちたら-100
最終目標に到達したら+100
ステップ毎に-1
◎MarLo-CatchTheMob-v0
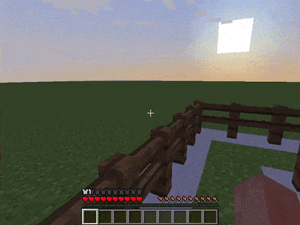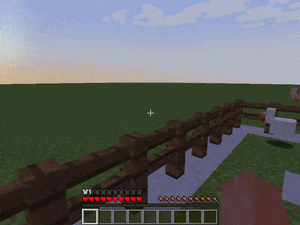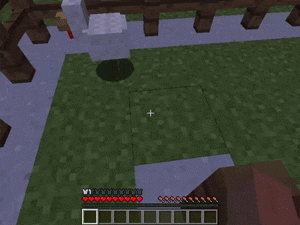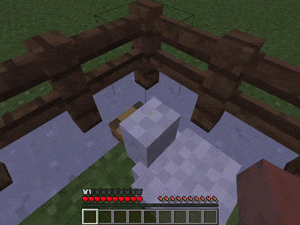
【説明】
1人または2人のエージェントが、対象のモンスターをキャッチし、現在いるブロックから逃げられないようにするタスクです。
さまざまな角度でコーナリングすることで実現できます。
【行動】
・Move
・Jumpmove
・Strafe
・Turn
・Movenorth, Moveeast, Movesouth, Movewest
・Jumpnorth, Jumpeast, Jumpsouth, Jumpwest
・Jump
・Look
・Use
・Jumpuse
【報酬】
ステップ毎に-0.02(エピソード毎に最大50ステップ)
現在のマップを終了したら+0.2
Mobを捕まええたら+1
◎MarLo-FindTheGoal-v0
【説明】
金を発見するタスクです。
【行動】
・Move
・Turn
【報酬】
ステップ毎に-0.01
目標達成時に+0.5
タイムオーバー時に-0.1
◎MarLo-Attic-v0
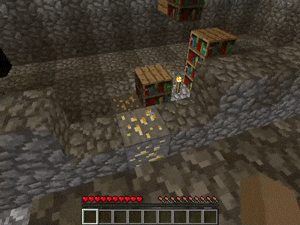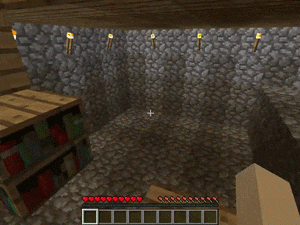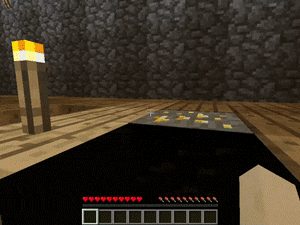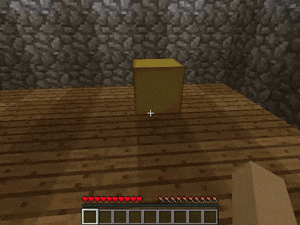
【説明】
マンションの屋根裏部屋にあるゴールド/ダイヤモンド/レッドストーンを発見するタスクです。
階段、本棚、溶岩の穴などのさまざまな障害があります。
【行動】
・Jump
・Move
・Pitch
・Strafe
・Turn
・Crouch
・Use
【報酬】
タイムオーバー時に-1000
目標達成時に+1000
金/ダイヤモンド/レッドストーン発見時に+20
◎MarLo-DefaultFlatWorld-v0
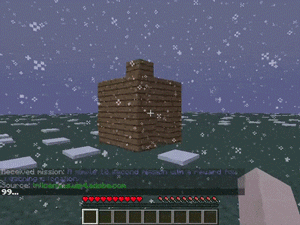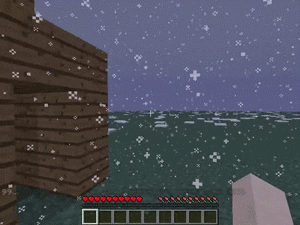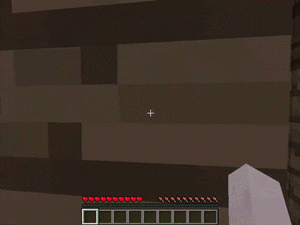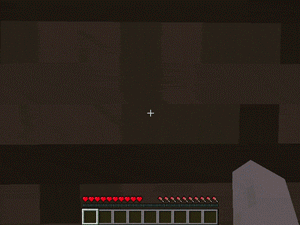
【説明】
エージェントのスポーン近くの場所に到達するタスクです。
天気は暗く雪が多いです。
【行動】
・Forward/Backward
・Turning
【報酬】
目標達成時に+100
◎MarLo-DefaultWorld-v0
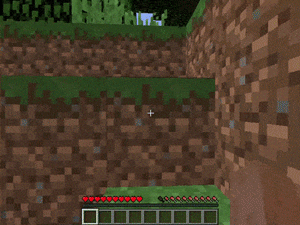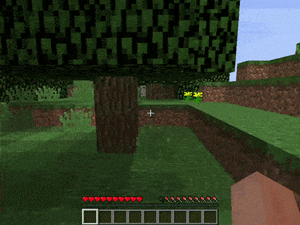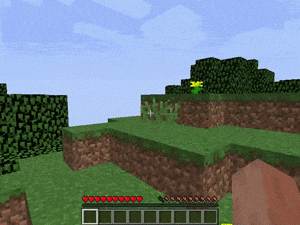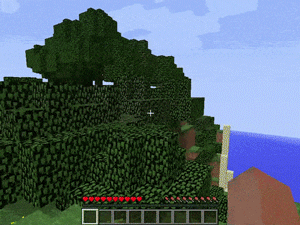
【説明】
通常のランダムなマインクラフトの世界で、金/ダイヤモンド/レッドストーンを発見するタスクです。
シードはランダムに生成されるため、場所は常に同じではありません。
【行動】
・Forward/Backward
・Turning
【報酬】
目標達成時に+1000
タイムオーバー時に-1000
死亡時に-10000
◎MarLo-Eating-v0
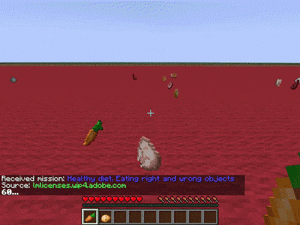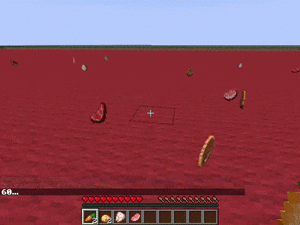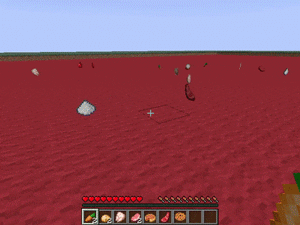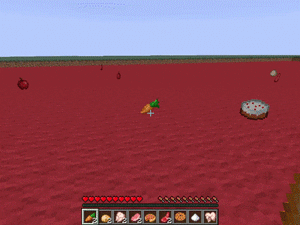
【説明】
食品が散らばった平らなマップで、健康的な食品のみを拾うするタスクです。
エージェントは特定のアイテムを他のアイテムよりも優先するように求められます。
【行動】
・Move forward/backward
・Jump
・Turn
・Strafe
・Crouch
・Use
【報酬】
魚、ポークチョップ、牛肉、鶏肉、ウサギ、マトンを拾った時+2
ジャガイモ、卵、ニンジンを拾った時+1
リンゴ、メロンを拾った時-1
砂糖、ケーキ、クッキー、パンプキンパイを拾った時-2
◎MarLo-Obstacles-v0
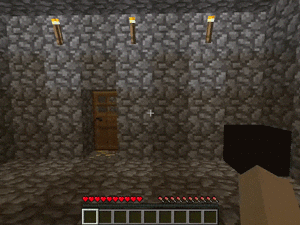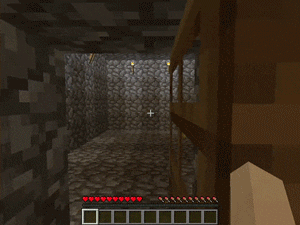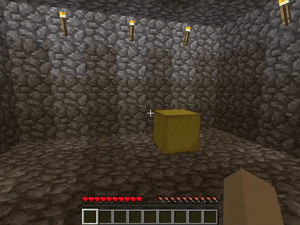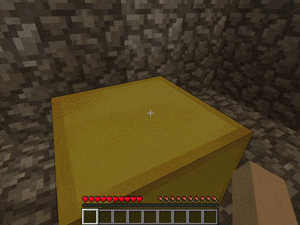
【説明】
障害物やレバーによって作動するドアがある部屋で、金/ダイヤモンド/レッドストーンを発見するタスクです。
【行動】
・Jump
・Move
・Pitch
・Strafe
・Turn
・Crouch
・Use
【報酬】
目標達成時に+2000
タイムイーバー時に-1000
金/ダイヤモンド/レッドストーン発見時に+20
◎MarLo-TrickyArena-v0
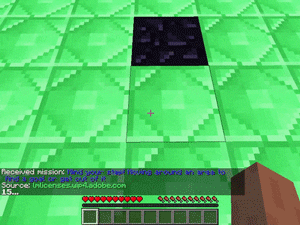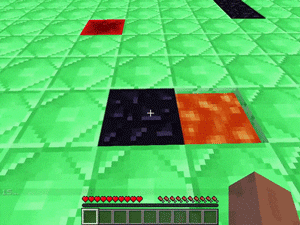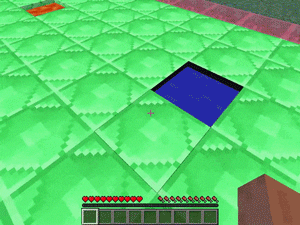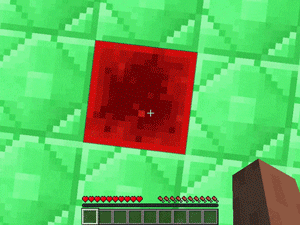
【説明】
レッドストーン/黒曜石/氷/水/溶岩の穴が散らばった平らなマップで、できるだけ多くの黒曜石を踏んでからレッドストーンに到達するタスクです。
【行動】
・Jump
・Move
・Pitch
・Strafe
・Turn
・Crouch
・Use
【報酬】
黒曜石タッチ時に1秒の遅延を伴う+100
死亡時に-1000
タイムオーバー時に-900
ステンドグラスに触れた時に+100
水穴に落ちた時に-800
レッドストーン発見時に+400
◎MarLo-Vertical-v0
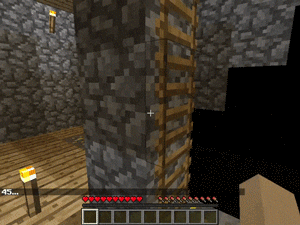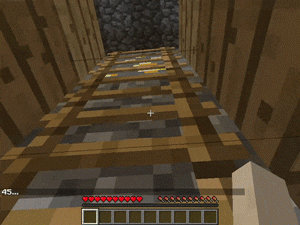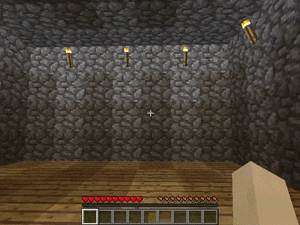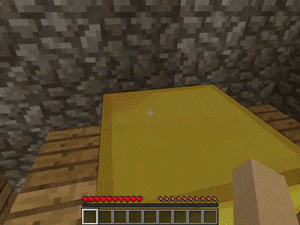
【説明】
階段/梯子などの多くの垂直配置のあるマップで、塔の最上部で金/ダイヤモンド/レッドストーンを発見するタスクです。
【行動】
・Jump
・Move
・Pitch
・Strafe
・Turn
・Crouch
・Use
【報酬】
目標達成時に+8000
タイムオーバー時に-1000
金/ダイヤモンド/レッドストーン発見時に+20
3. MarLÖのインストール
MarLÖをインストールするには、AnacondaのPython 3.6の仮想環境で以下の以下のコマンドを入力します。Macでは動かなかったのでUbuntu 18にインストールしました。インストールのテストでは、エラーがでないことだけを確認します。
$ conda config --add channels conda-forge
$ conda activate marlo
$ conda install -c crowdai malmo
$ pip install -U marlo
# インストールのテスト
$ python -c "import marlo"
$ python -c "from marlo import MalmoPython"4. マインクラフトのクライアントの起動
マインクラフトのクライアントを起動するには、次のコマンドを入力します。
$ $MALMO_MINECRAFT_ROOT/launchClient.sh -port 10000成功すると、以下のようにタイトル画面が表示されます。

4. シングルエージェントの起動
シングルエージェントを起動して、ランダム行動を採るコードは次の通りです。別ターミナルでAnacondaの仮想環境を開きこのコードを実行します。
#!/usr/bin/env python
# $MALMO_MINECRAFT_ROOT/launchClient.sh -port 10000
import marlo
client_pool = [('127.0.0.1', 10000)]
join_tokens = marlo.make('MarLo-FindTheGoal-v0',
params={"client_pool": client_pool})
# シングルエージェントのタスクのためシングルトークン
assert len(join_tokens) == 1
join_token = join_tokens[0]
# 環境の生成
env = marlo.init(join_token)
# 初期状態の取得
observation = env.reset()
# エージェントの実行
done = False
while not done:
# 行動の取得
_action = env.action_space.sample()
# 1ステップ実行
obs, reward, done, info = env.step(_action)
# ログ出力
print("reward:", reward)
print("done:", done)
print("info", info)
env.close()マインクラフトのクライアントでランダム行動が始まります。

5. マルチエージェントの起動
マルチエージェントを実行するには、マインクラフトのクライアントを2つ起動した後、以下のコードを実行します。
#!/usr/bin/env python
# $MALMO_MINECRAFT_ROOT/launchClient.sh -port 10000
# $MALMO_MINECRAFT_ROOT/launchClient.sh -port 10001
import marlo
client_pool = [('127.0.0.1', 10000),('127.0.0.1', 10001)]
join_tokens = marlo.make('MarLo-MazeRunner-v0',
params={"client_pool": client_pool,
"agent_names" : ["MarLo-Agent-0", "MarLo-Agent-1"]})
# マルチエージェントのタスクのため2
assert len(join_tokens) == 2
# エージェントの実行
@marlo.threaded
def run_agent(join_token):
env = marlo.init(join_token)
observation = env.reset()
done = False
count = 0
while not done:
_action = env.action_space.sample()
obs, reward, done, info = env.step(_action)
print("reward:", reward)
print("done:", done)
print("info", info)
env.close()
# agent-0の実行
thread_handler_0, _ = run_agent(join_tokens[0])
# agent-1の実行
thread_handler_1, _ = run_agent(join_tokens[1])
# 両方のスレッドの実行が完了するまで待機
thread_handler_0.join()
thread_handler_1.join()
print("Episode Run Complete")この記事が気に入ったらサポートをしてみませんか?