
Google Colab で SeamlessM4T を試す

「Google Colab」で「SeamlessM4T」を試したので、まとめました。
1. SeamlessM4T
「SeamlessM4T」は、音声とテキストをシームレスに翻訳および文字起こしを行う、多言語なマルチタスクモデルです。入力は約100、出力は36の言語に対応しています。
・Speech-to-speech translation (S2ST) : 音声から音声への翻訳
・Speech-to-text translation (S2TT) : 音声からテキストへの翻訳
・Text-to-speech translation (T2ST) : テキストから音声への翻訳
・Text-to-text translation (T2TT) : テキストからテキストへの翻訳
・Automatic speech recognition (ASR) : 自動音声認識
2. SeamlessM4Tのモデル
「SeamlessM4T」は、次の2つのモデルが提供されています。
3. Colabでの実行
ColabでのS2STの実行手順は、次のとおりです。
(1) 音声を録音したWAVファイル (sample.wav) をアップロード。
(2) 160000Hzに変換。
SeamlessM4Tを利用するには、WAVファイルを160000Hzに変換しておく必要があります。
import torchaudio
path_to_input_audio="sample.wav"
path_to_resampled_audio="sample_160000.wav"
# 16000Hzにリサンプリング
resample_rate = 16000
waveform, sample_rate = torchaudio.load(path_to_input_audio)
resampler = torchaudio.transforms.Resample(sample_rate, resample_rate, dtype=waveform.dtype)
resampled_waveform = resampler(waveform)
torchaudio.save(path_to_resampled_audio, resampled_waveform, resample_rate)(3) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/facebookresearch/seamless_communication
%cd seamless_communication
!pip install .(4) トランスレーターの準備。
今回は、「facebook/seamless-m4t-medium」を利用しています。
import torch
from seamless_communication.models.inference import Translator
# トランスレーターの準備
translator = Translator(
"seamlessM4T_medium",
vocoder_name_or_card="vocoder_36langs",
dtype=torch.float16,
device=torch.device("cuda:0")
)(5) 翻訳の実行。
# S2ST (音声から音声への翻訳)
translated_text, wav, sr = translator.predict("../sample_160000.wav", "s2st", "eng")
print("translated_text:", translated_text)
print("wav", wav)
print("sr:", sr)translated_text: From smartphones to feature phones to multi-devices.
wav tensor([[[-4.7080e-04, -2.0744e-04, -1.3344e-05, ..., 1.2436e-03,
1.1790e-03, 1.2109e-03]]], device='cuda:0')
sr: 16000(6) WAVファイルの保存。
# WAVファイルの保存
torchaudio.save("../sample_en.wav", wav[0].cpu(), sr)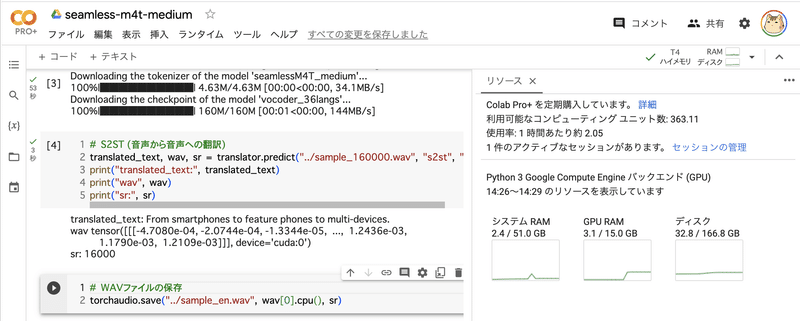
【おまけ】 コマンド一覧
詳しくは推論のREADMEを参照。
・S2ST
m4t_predict <path_to_input_audio> s2st <tgt_lang> --output_path <path_to_save_audio> --model_name seamlessM4T_large・S2TT
m4t_predict <path_to_input_audio> s2tt <tgt_lang>・T2TT
m4t_predict <input_text> t2tt <tgt_lang> --src_lang <src_lang>・T2ST
m4t_predict <input_text> t2st <tgt_lang> --src_lang <src_lang> --output_path <path_to_save_audio>・ASR
m4t_predict <path_to_input_audio> asr <tgt_lang>この記事が気に入ったらサポートをしてみませんか?