
Google Colab で LLaMA-Factory を試す

「Google Colab」で「LLaMA-Factory」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. LLaMA-Factory
「LLaMA-Factory」は、WebUIによる簡単操作でLLMを学習できるLLMファインチューニングフレームワークです。
サポートするモデルは、次のとおりです。

サポートする学習法は、次のとおりです。

サポートするデータセットは、次のとおりです。
事前学習データセット
・Wiki Demo (en)
・RefinedWeb (en)
・RedPajama V2 (en)
・Wikipedia (en)
・Wikipedia (zh)
・Pile (en)
・SkyPile (zh)
・The Stack (en)
・StarCoder (en)
SFTデータセット
・Stanford Alpaca (en)
・Stanford Alpaca (zh)
・GPT-4 Generated Data (en&zh)
・Self-cognition (zh)
・Open Assistant (multilingual)
・ShareGPT (zh)
・Guanaco Dataset (multilingual)
・BELLE 2M (zh)
・BELLE 1M (zh)
・BELLE 0.5M (zh)
・BELLE Dialogue 0.4M (zh)
・BELLE School Math 0.25M (zh)
・BELLE Multiturn Chat 0.8M (zh)
・UltraChat (en)
・LIMA (en)
・OpenPlatypus (en)
・CodeAlpaca 20k (en)
・Alpaca CoT (multilingual)
・OpenOrca (en)
・MathInstruct (en)
・Firefly 1.1M (zh)
・Web QA (zh)
・WebNovel (zh)
・Nectar (en)
・deepctrl (en&zh)
・Ad Gen (zh)
・ShareGPT Hyperfiltered (en)
・ShareGPT4 (en&zh)
・UltraChat 200k (en)
・AgentInstruct (en)
・LMSYS Chat 1M (en)
・Evol Instruct V2 (en)
Preferenceデータセット
・HH-RLHF (en)
・Open Assistant (multilingual)
・GPT-4 Generated Data (en&zh)
・Nectar (en)
依存関係は、次のとおりです。
・Python 3.8+、PyTorch 1.13.1+
・Transformers、Datasets、Accelerate、PEFT、TRL
・sentencepiece、protobuf、tiktoken
・jieba、rouge-chinese、nltk (評価と予測に利用)
・gradio、matplotlib (WebUIに利用)
・uvicorn、fastapi、sse-starlette (APIに利用)
ハードウェア要件は、次のとおりです。

2. 学習
今回は、「Elyza-7B」で「ござるデータセット」を学習させます。
Colabでの学習手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
QLoRAを有効にしたい場合のみ、bitsandbytesもインストールします。
# パッケージのインストール
!git clone https://github.com/hiyouga/LLaMA-Factory.git
%cd LLaMA-Factory
!pip install -r requirements.txt
!pip install bitsandbytes(3) コードの編集。
・src/train_web.py (7行目)
share=Trueを指定し、ColabでWebUIを利用できるようにします。
demo.launch(server_name="0.0.0.0", share=True, inbrowser=True)
・data/dataset_info.json (2行目)
「ござるデータセット」(gozaru_ja)を追加します。
{
"gozaru_ja": {
"hf_hub_url": "bbz662bbz/databricks-dolly-15k-ja-gozarinnemon",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
:
・src/llmtuner/data/template.py (554行目)
「日本語版Llama2のチャットテンプレート」(llama2_ja)を追加します。
register_template(
name="llama2_ja",
prefix=[
"<<SYS>>\n{{system}}\n<</SYS>>\n\n"
],
prompt=[
"[INST] {{query}} [/INST]"
],
system="あなたは誠実で優秀な日本人のアシスタントです。",
sep=[]
)(4) 「LLaMA-Factory」の起動。
# LLaMA-Factoryの起動
!CUDA_VISIBLE_DEVICES=0 python src/train_web.py(5) 「https://XXXX.gradio.live」のリンクが表示されたらクリック。

(6) モデルの設定。
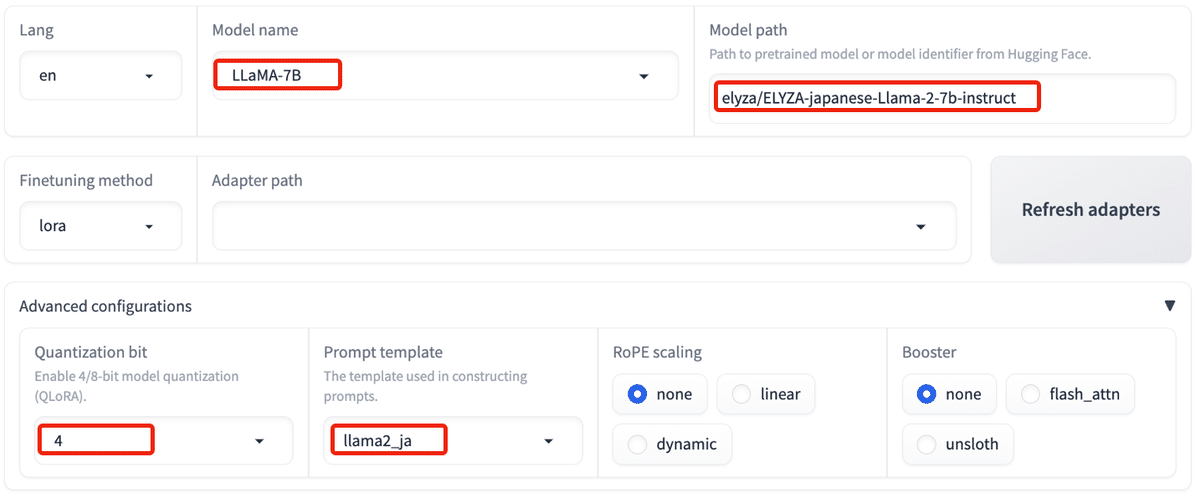
今回は、「Elyza-7B」(LLama2ベース)の4bitのQLoRAを指定します。
・Model name : LLaMA-7B
・Model path : elyza/ELYZA-japanese-Llama-2-7b-instruct
・Quantization bit : 4
・Prompt template : llama2_ja
(7) 「train」タブで学習の設定。
・Dataset : gozaru_ja
・Cutoff length : 512
・Learning rate : 2e-4
・Max samples : 10000
・Compute type : bf16
・Batch size : 16
・Maximum gradient norm : 0.3

(8) 「Preview command」ボタンでコマンドを確認し、「Start」ボタンで学習開始。
33分ほどかかりました。

3. 推論
Colabでの推論手順は、次のとおりです。
(1) 「Refresh adapters」ボタンで更新した後、「Adapter path」で学習したアダプターを選択。

(2) 「Chat」タブで「Load model」ボタンを押した後、システムメッセージとユーザーメッセージを入力して「Submit」ボタンを押す。
「ござる」口調 (または「知らんけど」) になることを確認します。

4. 評価
Colabでの評価手順は、次のとおりです。
(1) 「Evaluate & Predict」タブで「Dataset」と「Max samples」を設定した後、「Preview command」ボタンでコマンドを確認し、「Start」ボタンで評価を開始。

「BLEU-4スコア」は、主に機械翻訳の品質を測定する指標です。4単語のn-gramの一致を測定します。30から40の範囲は良い、20から30はまあまあ、20未満は改善の余地があると考えることができます。
「ROUGEスコア」は、主に要約の品質を測定する指標です。生成されたテキストが参照テキストとどれだけ一致しているかを測定します。ROUGE-1は単語の一致、ROUGE-2は2単語の連続するn-gramの一致、ROUGE-Lは最長の共通の部分列を測定します。一般に、ROUGEスコアが高い(ROUGE-1やROUGE-2で70%以上、ROUGE-Lで50%以上)場合、生成されたテキストが参照テキストと高い一致度を持っていると評価されます。
この記事が気に入ったらサポートをしてみませんか?