LlamaIndexによるマルチモーダルRAGの評価

以下の記事が面白かったので、かるくまとめました。
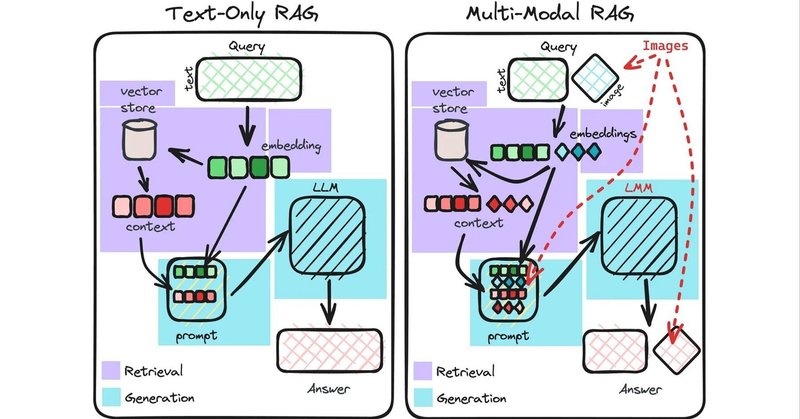
1. テキストオンリーRAG と マルチモーダルRAG
はじめに、「テキストオンリーRAG」と「マルチモーダルRAG」の比較を行います。

1-1. インデックスデータ
・テキストオンリーRAG
テキストをエンコードし、インデックスに保存。
テキスト用のエンコーダ (text-embedding-ada-002など) を使用。
・マルチモーダルRAG
テキストと画像をエンコードし、別のインデックス (または名前空間/コレクション) に保存。
テキスト用のエンコーダ (text-embedding-ada-002など)と画像用のエンコーダ (clipなど) を使用。
1-2. 生成モデル
・テキストオンリーRAG
LLM (GPT-4、GPT-3.5、LLaMa-2 など) を選択。
・マルチモーダルRAG
LMM (GPT-4V、LLaVA など) を選択。
1-3. クエリ
・テキストオンリーRAG
ユーザーがテキストのみのクエリを送信。
・マルチモーダルRAG
ユーザーが画像とテキストの両方を含むクエリを送信。
1-4. ドキュメントの取得
・テキストオンリーRAG
テキストクエリをエンコードし、関連するテキストの取得に使用。
・マルチモーダルRAG
テキストと画像のクエリをエンコードし、関連するテキストと画像の取得に使用。
1-5. レスポンス生成
・テキストオンリーRAG
取得したテキストは、LLMジェネレータでクエリに対する回答を生成するためのコンテキストとして使用。
・マルチモーダルRAG
取得したテキストと画像は、LLMジェネレーターでクエリに対する回答を生成するためのコンテキストとして使用。
2. テキストオンリーRAGの評価
「テキストオンリーRAG」の標準的なアプローチは、「Retrieval」と「Generation」の2段階の評価を個別に検討することです。
2-1. Retrieval の評価
「Retrieval」の評価では、取得したドキュメントがユーザークエリに関連しているかどうかを評価します。
一般的な指標は、次のとおりです。
・recall
・hit rate
・mean reciprocal rank
・mean average precision
・normalized discounted cumulative gain
最初の2つは、関連するドキュメントの位置 (またはランキング) を考慮しませんが、他の指標はそれぞれ独自の方法で考慮します。
2-2. Generation の評価
「Generation」の評価では、応答がユーザークエリに十分に答えるために、取得したドキュメントを使用しているかどうかを評価します。
質問応答システムでは、書き言葉でクエリに十分に答える方法が1つだけではなく、たくさんあるため、生成された応答の測定は困難です。
そのため、測定は人間が実行できる主観的な判断に依存していますが、これにはコストがかかり、拡張性がありません。別のアプローチは、LLM審査員を使用して、関連性や忠実性などを評価することです。
・Relevancy : テキストのコンテキストを考慮し、生成した応答がクエリとどの程度一致するかを評価。
・Faithfulness : 生成した応答が取得したテキストのコンテキストとどの程度一致するかを評価。
取得したコンテキスト、クエリ、生成した応答がLLM審査員に渡されます。LLMによる評価は、一部の研究者によって 「LLM-As-A-Judge」と呼ばれています。
現在「llama-index v0.9.2」では、以下の評価に対応しています。
・Retrieval の評価
・hit-rate
・mean reciprocal rank
・Generation の評価
・relevancy
・faithfulness
詳しくは、ドキュメントを参照してください。
3. マルチモーダル RAG の評価
マルチモーダルの場合でも、評価は「Retrieval」と「Generation」に関して実行できます (またそうすべきです)。
3-1. テキストと画像の Retrieval の評価の分離
取得するドキュメントには2つの形式があるため、通常のRetrieval評価指標をテキストと画像に対して、別々に計算することを検討するのが最も賢明であると思われます。このようにして、マルチモーダルRetrieverのどの側面がうまく機能し、どの側面がうまく機能していないのかについて把握できます。次に、必要な重み付けスキームを適用して、指標ごとに単一の集計された検索スコアを確立できます。

3-2. LLM-As-A-Judge に よる Generation の評価
「GPT-4V」のようなマルチモーダルモデル (LMM) や、「LLaVA」のようなオープンソースの代替モデルは、入力と画像コンテキストの両方を取り込んで、ユーザーのクエリに対する回答を生成できます。「テキストオンリーRAG」と同様に、生成された回答の「relevancy」と「faithfulness」にも懸念があります。 しかし、マルチモーダルなケースでそのような指標を計算できるようにするには、コンテキスト画像とテキストも取り込める審査員が必要になります。 したがって、マルチモーダルの場合、「relevancy」と「faithfulness」およびその他の関連する指標を計算するために、「LMM-As-A-Judge」を採用します。
・relevancy (マルチモーダル) : テキストと画像のコンテキストを考慮し、生成した応答がクエリとどの程度一致するかを評価。
・faithfulness (マルチモーダル) : 生成した応答が、取得したテキストと画像のコンテキストとどの程度一致するかを評価。
これらの評価には、LlamaIndexに最近追加された「Multi-Modal Evaluator」を使用することができます。
from llama_index.evaluation.multi_modal import (
MultiModalRelevancyEvaluator,
MultiModalFaithfulnessEvaluator
)
from llama_index.multi_modal_llm import OpenAIMultiModal
relevancy_judge = MultiModalRelevancyEvaluator(
multi_modal_llm=OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=300,
)
)
faithfulness_judge = MultiModalRelevancyEvaluator(
multi_modal_llm=OpenAIMultiModal(
model="gpt-4-vision-preview",
max_new_tokens=300,
)
)
# クエリに対して生成した応答とその取得したコンテキスト情報
query = ...
response = ...
contexts = ... # retrieved text contexts
image_paths = ... # retrieved image contexts
# 評価
relevancy_eval = relevancy_judge.evaluate(
query=query,
response=response,
contexts=contexts,
image_paths=image_paths
)
faithfulness_eval = faithfulness_judge.evaluate(
query=query,
response=response,
contexts=contexts,
image_paths=image_paths
)4. 注意事項
生成した応答を判断するためにLLMまたはLMMを使用することには欠点があることに注意する必要があります。これらの審査員はそれ自体が生成モデルであり、ハルシネーションやその他の矛盾に悩まされる可能性があります。強力なLLMは人間の判断に比較的高い割合で一致することが研究で示されていますが、本番環境での使用にはより高い注意を払う必要があります。
現時点では、強力なLMMが人間の判断にもうまく適合できることを示す研究はありません。Generationの評価は、主にその知識と推論能力の評価に関係します。アライメントや安全性など、LLMとLMMを評価する重要な側面は他にもあります。詳しくは、「Evaluating LMMs: A Comprehensive Survey」を参照してください。
関連
・LlamaIndexを使用してマルチモーダルRAGを評価するためのノートブック
・マルチモーダルRAGの概要
・マルチモーダル抽象化に関するドキュメント/ガイド
この記事が気に入ったらサポートをしてみませんか?