Google Colab で LINE の japanese-large-lm を試す

「Google Colab」でLINEの「japanese-large-lm」を試したので、まとめました。
1. japanese-large-lm
「japanese-large-lm」は、「LINE」が開発した36億パラメータの日本語LLMです。
2. japanese-large-lmのモデル
「japanese-large-lm」では、次の3種類のモデルが提供されています。
・line-corporation/japanese-large-lm-3.6b : ベースモデル
・line-corporation/japanese-large-lm-3.6b-instruction-sft : 指示モデル
・line-corporation/japanese-large-lm-1.7b : ベースモデル
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install transformers accelerate bitsandbytes
!pip install sentencepiece(2) トークナイザーとモデルの準備。
今回は、「line-corporation/japanese-large-lm-3.6b」を8bit量子化で読み込みました。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"line-corporation/japanese-large-lm-3.6b",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"line-corporation/japanese-large-lm-3.6b",
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
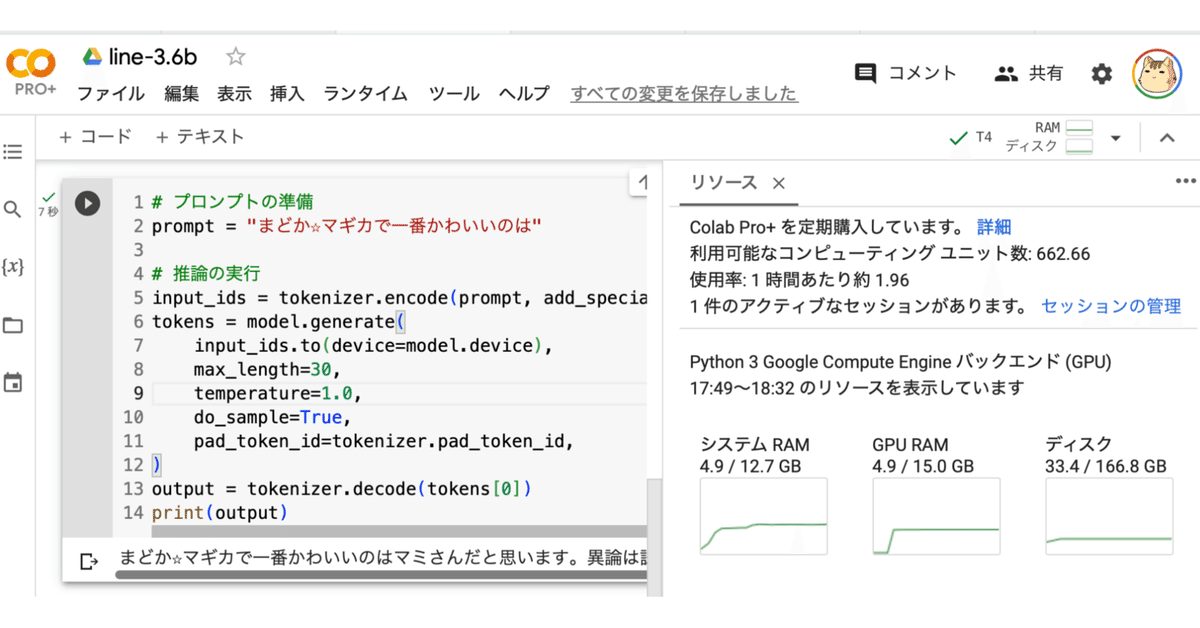
)(3) 推論の実行。
ベースモデルなので、任意のテキストの続きを作成してもらいました。
# プロンプトの準備
prompt = "まどか☆マギカで一番かわいいのは"
# 推論の実行
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
tokens = model.generate(
input_ids.to(device=model.device),
max_length=30,
temperature=1.0,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
)
output = tokenizer.decode(tokens[0])
print(output)まどか☆マギカで一番かわいいのはマミさんだと思います。異論は認めます( `・ω・ ́)さやかとほむほむ!関連
この記事が気に入ったらサポートをしてみませんか?