Google Colab で Idefics2 のファインチューニングを試す

「Google Colab」で「Idefics2」のファインチューニングを試したのでまとめました。
【注意】Google Colab Pro/Pro+のV100で動作確認しています。
1. Idefics2 のファインチューニング用Colab
公式の「Idefics2」のファインチューニング用Colabに沿って実行するだけでファインチューニングできます。
2. 学習
Colabでの学習手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「V100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q accelerate datasets peft bitsandbytes(3) プロセッサーとモデルの準備。
パラメータで次の3つから学習オプションを選択します。今回はQLolaを選択しました。
・QLora
・Standard Lora
・Full fine-tuning
import torch
from peft import LoraConfig
from transformers import AutoProcessor, BitsAndBytesConfig, Idefics2ForConditionalGeneration
# パラメータ
DEVICE = "cuda:0"
USE_LORA = False
USE_QLORA = True
# プロセッサの準備
processor = AutoProcessor.from_pretrained(
"HuggingFaceM4/idefics2-8b",
do_image_splitting=False
)
# モデルの準備
if USE_QLORA or USE_LORA:
lora_config = LoraConfig(
r=8,
lora_alpha=8,
lora_dropout=0.1,
target_modules='.*(text_model|modality_projection|perceiver_resampler).*(down_proj|gate_proj|up_proj|k_proj|q_proj|v_proj|o_proj).*$',
use_dora=False if USE_QLORA else True,
init_lora_weights="gaussian"
)
if USE_QLORA:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = Idefics2ForConditionalGeneration.from_pretrained(
"HuggingFaceM4/idefics2-8b",
torch_dtype=torch.float16,
quantization_config=bnb_config if USE_QLORA else None,
)
model.add_adapter(lora_config)
model.enable_adapters()
else:
model = Idefics2ForConditionalGeneration.from_pretrained(
"HuggingFaceM4/idefics2-8b",
torch_dtype=torch.float16,
_attn_implementation="flash_attention_2", # A100 or H100 のみ可
).to(DEVICE)GPUメモリの消費量を抑えるため、以下の手法を使用しています。
・4bit量子化の使用
・LoRAのファインチューニング
・Vision Encoderのフリーズ
・小さなバッチサイズをより高いグラジエント蓄積度で補う
・画像分割の無効化
・Flash-Attentionの使用
(4) データセットの準備。
今回は、「nielsr/docvqa_1200_examples」を使用します。
各サンプルには、文書の「画像」「質問」「回答」のリストが含まれています。質問は、複数の言語で書かれていますが、英語のみ使用します。
from datasets import load_dataset
# データセットの準備
train_dataset = load_dataset("nielsr/docvqa_1200_examples", split="train")
train_dataset = train_dataset.remove_columns(['id', 'words', 'bounding_boxes', 'answer'])
eval_dataset = load_dataset("nielsr/docvqa_1200_examples", split="test")
eval_dataset = eval_dataset.remove_columns(['id', 'words', 'bounding_boxes', 'answer'])(5) サンプルの確認。
# サンプルの確認
train_dataset[10]{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=L size=1706x2198>,
'query': {
'de': 'Mit welchem Test werden ART Menthol-Werte bewertet, die ausgeliefert wurden?',
'en': 'Which test is used to evaluate ART menthol levels that has been shipped?',
'es': '¿Qué prueba se utiliza para evaluar los niveles de ART mentol que se ha enviado?',
'fr': 'Quel test est utilisé pour évaluer les niveaux de menthol ART qui ont été expédiés?',
'it': 'Quale test viene utilizzato per valutare i livelli di mentolo ART che è stato spedito?'
},
'answers': ['A second Danchi Test']
}(6) サンプルの画像の確認。
# サンプルの画像の確認
train_dataset[10]["image"]
(7) 「DataCollator」の定義。
サンプルのリストを受け取り、モデルに与える4つの入力テンソルを返しま
・input_ids : 言語モデルに供給される入力インデックス
・attention_mask : input_idsに対するアテンションマスク
・pixel_values : 画像をエンコードする前処理されたピクセル値
「Idefics2」は画像をネイティブ解像度 (最大980) とネイティブアスペクト比で扱います。
・pixel_attention_mask : pixel_valuesに対するアテンションマスク
複数の画像が同じサンプル (またはバッチ) に含まれる場合、これらの画像サイズやアスペクト比が異なる可能性があるため、画像のアテンションマスクが必要です。このマスキングにより、「Vision Encoder」は画像を適切に転送できるようになります。
import random
# DataCollatorの定義
class MyDataCollator:
def __init__(self, processor):
self.processor = processor
self.image_token_id = processor.tokenizer.additional_special_tokens_ids[
processor.tokenizer.additional_special_tokens.index("<image>")
]
def __call__(self, examples):
texts = []
images = []
for example in examples:
# データ抽出
image = example["image"] # 画像
question = example["query"]["en"] # 質問
answer = random.choice(example["answers"]) # 応答
# メッセージリストの作成
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Answer briefly."},
{"type": "image"},
{"type": "text", "text": question} # 質問
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": answer} # 応答
]
}
]
# テキストの画像の追加
text = processor.apply_chat_template(messages, add_generation_prompt=False)
texts.append(text.strip())
images.append([image])
batch = processor(text=texts, images=images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
labels[labels == processor.tokenizer.pad_token_id] = self.image_token_id
batch["labels"] = labels
return batch
# DataCollatorの準備
data_collator = MyDataCollator(processor)
(8) 学習パラメータとトレーナーの準備。
from transformers import TrainingArguments, Trainer
# 学習パラメータの準備
training_args = TrainingArguments(
num_train_epochs=2,
per_device_train_batch_size=2,
per_device_eval_batch_size=8,
gradient_accumulation_steps=8,
warmup_steps=50,
learning_rate=1e-4,
weight_decay=0.01,
logging_steps=25,
output_dir="/content/drive/My Drive/docvqa_ft_tutorial",
save_strategy="steps",
save_steps=250,
save_total_limit=1,
# evaluation_strategy="epoch",
fp16=True,
push_to_hub_model_id="idefics2-8b-docvqa-finetuned-tutorial",
remove_unused_columns=False,
report_to="none",
)
# トレーナーの準備
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_dataset,
# eval_dataset=eval_dataset, # You can also evaluate (loss) on the eval set, note that it will incur some additional GPU memory
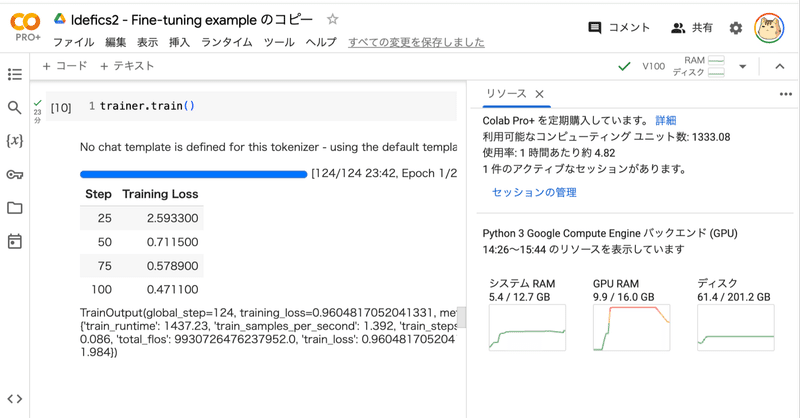
)(9) 学習の開始。
V100で23分ほどかかりました。
# 学習の開始
trainer.train()
3. 推論
Colabでの推論手順は、次のとおりです。
(1) 推論サンプルの準備。
# 推論サンプルの準備
example = eval_dataset[5]
example(2) 推論サンプルの画像の確認。
# 評価サンプルの画像の確認
example["image"]
(3) 推論の実行
model.eval()
image = example["image"]
query = example["query"]
# メッセージリストの準備
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Answer briefly."},
{"type": "image"},
{"type": "text", "text": query["en"]} # 質問
]
}
]
# 推論の実行
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=[text.strip()], images=[image], return_tensors="pt", padding=True)
generated_ids = model.generate(**inputs, max_new_tokens=64)
generated_texts = processor.batch_decode(generated_ids[:, inputs["input_ids"].size(1):], skip_special_tokens=True)
print(generated_texts)['6']4. 評価
学習中、評価のLossを追跡しましたが、DocVQAで使用された指標は 「ANLS」(Average Normalized Levenshtein Similarity) です。Biten+ ICCV'19によって提案された「ANLS」は、OCRのミスをスムーズに捕捉し、意図された回答が正しいにもかかわらず認識不良の場合にわずかなペナルティを適用します。
「ANLS」を計算するためのユーティリティを定義します。
(1) パッケージのインストール。
!pip install Levenshtein(2) 評価の計算式の定義。
import Levenshtein
def normalized_levenshtein(s1, s2):
len_s1, len_s2 = len(s1), len(s2)
distance = Levenshtein.distance(s1, s2)
return distance / max(len_s1, len_s2)
def similarity_score(a_ij, o_q_i, tau=0.5):
nl = normalized_levenshtein(a_ij, o_q_i)
return 1 - nl if nl < tau else 0
def average_normalized_levenshtein_similarity(ground_truth, predicted_answers):
assert len(ground_truth) == len(predicted_answers), "Length of ground_truth and predicted_answers must match."
N = len(ground_truth)
total_score = 0
for i in range(N):
a_i = ground_truth[i]
o_q_i = predicted_answers[i]
if o_q_i == "":
print("Warning: Skipped an empty prediction.")
max_score = 0
else:
max_score = max(similarity_score(a_ij, o_q_i) for a_ij in a_i)
total_score += max_score
return total_score / N(3) GPUメモリの開放
# GPUメモリの開放
torch.cuda.empty_cache()(4) 評価の実行。
from tqdm import tqdm
EVAL_BATCH_SIZE = 1
answers_unique = []
generated_texts_unique = []
for i in tqdm(range(0, len(eval_dataset), EVAL_BATCH_SIZE)):
examples = eval_dataset[i: i + EVAL_BATCH_SIZE]
answers_unique.extend(examples["answers"])
images = [[im] for im in examples["image"]]
texts = []
for q in examples["query"]:
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Answer briefly."},
{"type": "image"},
{"type": "text", "text": q["en"]}
]
}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True)
texts.append(text.strip())
inputs = processor(text=texts, images=images, return_tensors="pt", padding=True)
generated_ids = model.generate(**inputs, max_new_tokens=64)
generated_texts = processor.batch_decode(generated_ids[:, inputs["input_ids"].size(1):], skip_special_tokens=True)
generated_texts_unique.extend(generated_texts)(5) ANLSの確認。
generated_texts_unique = [g.strip().strip(".") for g in generated_texts_unique]
anls = average_normalized_levenshtein_similarity(
ground_truth=answers_unique, predicted_answers=generated_texts_unique,
)
print(anls)0.6492187657140279ANLSスコアは65程度です。これはDocVQAでよく学習されたモデルと比較すると低いスコアですが、練習のため小さなサブセットで学習学習と評価を行ったためです。ハイパーパラメータもチューニングしていません。
この記事が気に入ったらサポートをしてみませんか?