
TenorFlow Lite 入門 / Androidによる質問回答(BERT)

1. Androidによる質問と回答
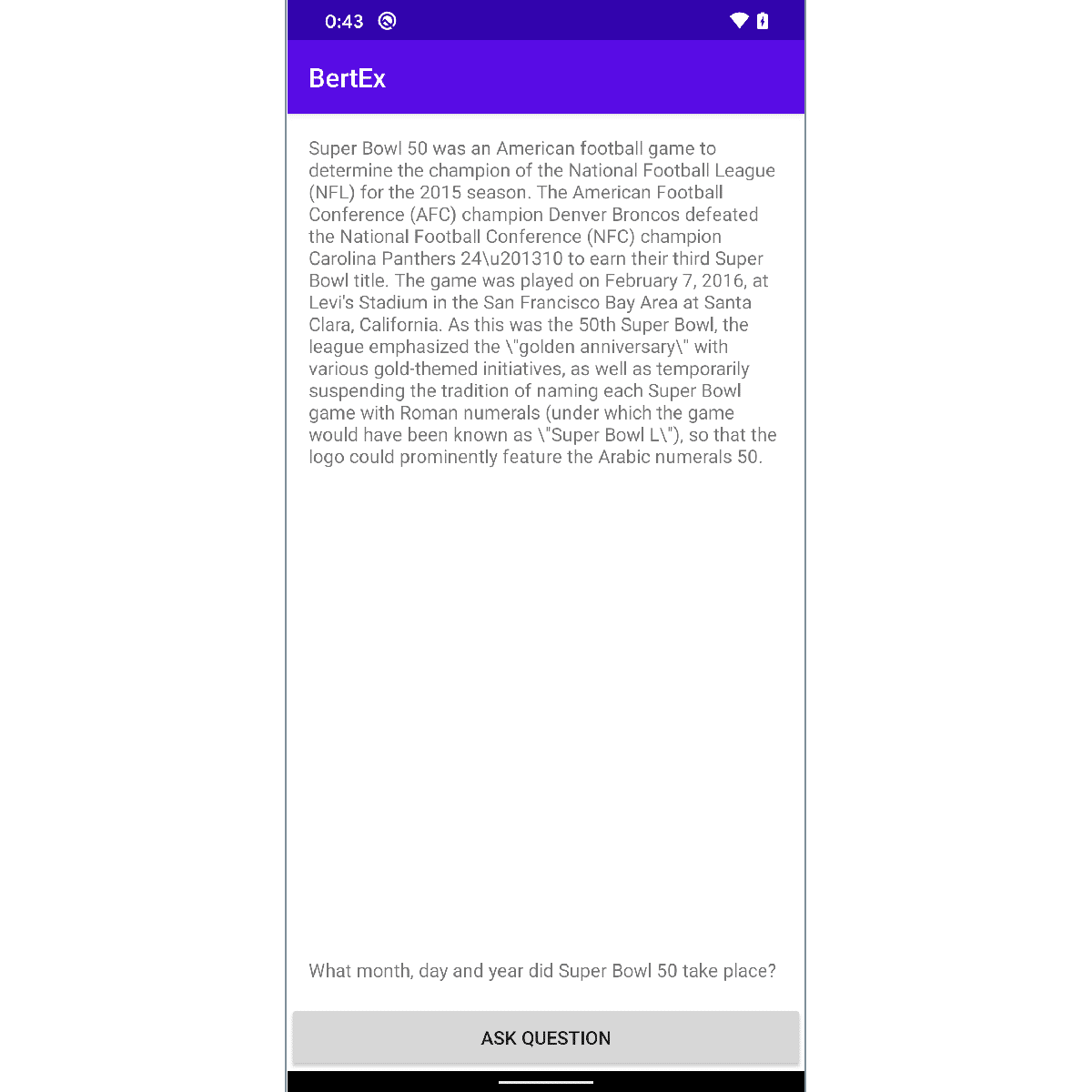
「TensorFlow Lite」を使ってAndroidで質問回答を行います。コンテンツを読んで質問に応じて回答を返します。
2. バージョン
・compileSdkVersion 29
・minSdkVersion 26
・targetSdkVersion 29
・tensorflow-lite:0.1.7
3. 依存関係の追加
「build.gradle(Mudule:app)」に、「TensorFlow Lite」のプロジェクトの依存関係を追加します。「Ints」を利用するため「Guava」も追加してます。
android {
<<省略>>
aaptOptions {
noCompress "tflite"
}
compileOptions {
sourceCompatibility = '1.8'
targetCompatibility = '1.8'
}
}dependencies {
<<省略>>
// TensorFlow Lite
implementation('org.tensorflow:tensorflow-lite:0.0.0-nightly') { changing = true }
implementation('org.tensorflow:tensorflow-lite-gpu:0.0.0-nightly') { changing = true }
implementation('org.tensorflow:tensorflow-lite-support:0.0.0-nightly') { changing = true }
// Guava
implementation 'com.google.guava:guava:28.1-android'
}
4. マニフェストファイルの設定
「CAMERA」のパーミッションを追加します。
<uses-permission android:name="android.permission.CAMERA" />5. アセットの準備
プロジェクトの「app/src/main/assets」に、「TensorFlow Lite BERT QA Android Example Application」のページからダウンロードした「モデル」と「単語辞書」と「コンテンツと質問」を追加します。
・model.tflite
・vocab.txt
・qa.json
6. レイアウトの設定
「activity_main.xml」に「TextView」と「Button」を追加します。
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<RelativeLayout android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="#FFFFFF">
<TextView
android:id="@+id/content_text_view"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:padding="16dp"
android:scrollbars="vertical"
android:layout_alignParentTop="true" />
<TextView
android:id="@+id/input_text_view"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:padding="16dp"
android:scrollbars="vertical"
android:layout_above="@+id/button" />
<Button
android:id="@+id/button"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:padding="16dp"
android:text="Ask question"
android:layout_alignParentBottom="true" />
</RelativeLayout>
</androidx.constraintlayout.widget.ConstraintLayout>7. UIの作成
画像分類を行うUIを作成します。
以下の処理を行なっています。
・パーミッション
・カメラのプレビューと解析
・BertInterpriterにコンテンツと質問を渡して推論(後ほど説明)
◎ MainActivity.java
package net.npaka.bertex;
import androidx.appcompat.app.AppCompatActivity;
import android.graphics.Color;
import android.os.Bundle;
import android.text.Spannable;
import android.text.SpannableString;
import android.text.style.BackgroundColorSpan;
import android.view.View;
import android.widget.Button;
import android.widget.TextView;
import java.util.List;
import java.util.Random;
public class MainActivity extends AppCompatActivity {
// QA
private final static String CONTENTS = "Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24\\u201310 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the \\\"golden anniversary\\\" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as \\\"Super Bowl L\\\"), so that the logo could prominently feature the Arabic numerals 50.";
private final static String[] Q = {
"Which NFL team represented the NFC at Super Bowl 50?",
"Where did Super Bowl 50 take place?",
"Which NFL team won Super Bowl 50?",
"What color was used to emphasize the 50th anniversary of the Super Bowl?",
"What was the theme of Super Bowl 50?", "What day was the game played on?",
"What is the AFC short for?", "What was the theme of Super Bowl 50?",
"What does AFC stand for?", "What day was the Super Bowl played on?",
"Who won Super Bowl 50?",
"What venue did Super Bowl 50 take place in?",
"What city did Super Bowl 50 take place in?",
"If Roman numerals were used, what would Super Bowl 50 have been called?",
"Super Bowl 50 decided the NFL champion for what season?",
"What year did the Denver Broncos secure a Super Bowl title for the third time?",
"What city did Super Bowl 50 take place in?",
"What stadium did Super Bowl 50 take place in?",
"What was the final score of Super Bowl 50? ",
"What month, day and year did Super Bowl 50 take place? ",
"What year was Super Bowl 50?", "What team was the AFC champion?",
"What team was the NFC champion?", "Who won Super Bowl 50?",
"Super Bowl 50 determined the NFL champion for what season?",
"Which team won Super Bowl 50.",
"Where was Super Bowl 50 held?",
"The name of the NFL championship game is?",
"What 2015 NFL team one the AFC playoff?"
};
// UI
private TextView contentTextView;
private TextView inputTextView;
// 推論
private BertInterpreter interpreter;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 推論
this.interpreter = new BertInterpreter(this);
// UI
this.contentTextView = findViewById(R.id.content_text_view);
this.contentTextView.setText(CONTENTS);
this.inputTextView = findViewById(R.id.input_text_view);
this.inputTextView.setText(Q[new Random().nextInt(Q.length)]);
Button button = findViewById(R.id.button);
button.setOnClickListener((View v) -> {
// 推論
String query = this.inputTextView.getText().toString();
String content = this.contentTextView.getText().toString();
List<QaAnswer> answers = this.interpreter.predict(query, content);
// 結果表示
if (!answers.isEmpty()) {
presentAnswer(answers.get(0), content);
}
});
}
// 結果の表示
private void presentAnswer(QaAnswer answer, String content) {
Spannable spanText = new SpannableString(content);
int offset = content.indexOf(answer.text, 0);
if (offset >= 0) {
spanText.setSpan(
new BackgroundColorSpan(Color.rgb(238, 255, 65)),
offset, offset+answer.text.length(),
Spannable.SPAN_EXCLUSIVE_EXCLUSIVE);
}
contentTextView.setText(spanText);
}
}
8. 質問回答
コンテンツと質問を受け取り、回答を返します。
◎ BertInterpreter.java
package net.npaka.bertex;
import android.content.Context;
import android.content.res.AssetFileDescriptor;
import com.google.common.base.Joiner;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.tensorflow.lite.Interpreter;
// Bertインタプリタ
public class BertInterpreter {
// パラメータ定数
private static final int MAX_ANS_LEN = 32;
private static final int MAX_QUERY_LEN = 64;
private static final int MAX_SEQ_LEN = 384;
private static final boolean DO_LOWER_CASE = true;
private static final int PREDICT_ANS_NUM = 5;
private static final int OUTPUT_OFFSET = 1;
private static final Joiner SPACE_JOINER = Joiner.on(" ");
// 推論
private Context context;
private Map<String, Integer> dic = new HashMap<>();
private FeatureConverter featureConverter;
private Interpreter interpreter;
// コンストラクタ
public BertInterpreter(Context context) {
this.context = context;
loadModel("model.tflite");
loadDictionary("vocab.txt");
this.featureConverter = new FeatureConverter(dic, DO_LOWER_CASE, MAX_QUERY_LEN, MAX_SEQ_LEN);
}
// モデルの読み込み
private synchronized void loadModel(String path) {
try {
AssetFileDescriptor fd = this.context.getAssets().openFd(path);
FileInputStream in = new FileInputStream(fd.getFileDescriptor());
FileChannel fc = in.getChannel();
long startOffset = fd.getStartOffset();
long declaredLength = fd.getDeclaredLength();
ByteBuffer buffer = fc.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
Interpreter.Options opt = new Interpreter.Options();
opt.setNumThreads(1);
this.interpreter = new Interpreter(buffer, opt);
} catch (Exception e) {
e.printStackTrace();
}
}
// 辞書の読み込み
private synchronized void loadDictionary(String path) {
try {
InputStream ins = this.context.getAssets().open(path);
BufferedReader reader = new BufferedReader(new InputStreamReader(ins));
int index = 0;
while (reader.ready()) {
String key = reader.readLine();
this.dic.put(key, index++);
}
} catch (Exception e) {
e.printStackTrace();
}
}
// 推論
public synchronized List<QaAnswer> predict(String query, String content) {
// コンテンツと質問を特徴に変換
Feature feature = featureConverter.convert(query, content);
// 入力の準備
int[][] inputIds = new int[1][MAX_SEQ_LEN];
int[][] inputMask = new int[1][MAX_SEQ_LEN];
int[][] segmentIds = new int[1][MAX_SEQ_LEN];
float[][] startLogits = new float[1][MAX_SEQ_LEN];
float[][] endLogits = new float[1][MAX_SEQ_LEN];
for (int j = 0; j < MAX_SEQ_LEN; j++) {
inputIds[0][j] = feature.inputIds[j];
inputMask[0][j] = feature.inputMask[j];
segmentIds[0][j] = feature.segmentIds[j];
}
Object[] inputs = {inputIds, inputMask, segmentIds};
Map<Integer, Object> output = new HashMap<>();
output.put(0, endLogits);
output.put(1, startLogits);
// 推論の実行
this.interpreter.runForMultipleInputsOutputs(inputs, output);
// 結果の生成
List<QaAnswer> answers = getBestAnswers(startLogits[0], endLogits[0], feature);
return answers;
}
// ロジットと入力特徴からn-best回答とロジットを取得
private synchronized List<QaAnswer> getBestAnswers(
float[] startLogits, float[] endLogits, Feature feature) {
// モデルはインデックスに閉じた間隔 [start, end] を使用
int[] startIndexes = getBestIndex(startLogits);
int[] endIndexes = getBestIndex(endLogits);
List<QaAnswer.Pos> origResults = new ArrayList<>();
for (int start : startIndexes) {
for (int end : endIndexes) {
if (!feature.tokenToOrigMap.containsKey(start)) {
continue;
}
if (!feature.tokenToOrigMap.containsKey(end)) {
continue;
}
if (end < start) {
continue;
}
int length = end - start + 1;
if (length > MAX_ANS_LEN) {
continue;
}
origResults.add(new QaAnswer.Pos(start, end, startLogits[start] + endLogits[end]));
}
}
Collections.sort(origResults);
List<QaAnswer> answers = new ArrayList<>();
for (int i = 0; i < origResults.size(); i++) {
if (i >= PREDICT_ANS_NUM) {
break;
}
String convertedText;
if (origResults.get(i).start > 0) {
convertedText = convertBack(feature, origResults.get(i).start, origResults.get(i).end);
} else {
convertedText = "";
}
QaAnswer ans = new QaAnswer(convertedText, origResults.get(i));
answers.add(ans);
}
return answers;
}
// 全ロジットからn-bestロジットを取得
private synchronized int[] getBestIndex(float[] logits) {
List<QaAnswer.Pos> tmpList = new ArrayList<>();
for (int i = 0; i < MAX_SEQ_LEN; i++) {
tmpList.add(new QaAnswer.Pos(i, i, logits[i]));
}
Collections.sort(tmpList);
int[] indexes = new int[PREDICT_ANS_NUM];
for (int i = 0; i < PREDICT_ANS_NUM; i++) {
indexes[i] = tmpList.get(i).start;
}
return indexes;
}
// 回答を元のテキスト形式に変換
private static String convertBack(Feature feature, int start, int end) {
int shiftedStart = start + OUTPUT_OFFSET;
int shiftedEnd = end + OUTPUT_OFFSET;
int startIndex = feature.tokenToOrigMap.get(shiftedStart);
int endIndex = feature.tokenToOrigMap.get(shiftedEnd);
String ans = SPACE_JOINER.join(feature.origTokens.subList(startIndex, endIndex + 1));
return ans;
}
}◎ QaAnswer.java
package net.npaka.bertex;
// QA回答
public class QaAnswer {
public Pos pos;
public String text;
// コンストラクタ
public QaAnswer(String text, Pos pos) {
this.text = text;
this.pos = pos;
}
// コンストラクタ
public QaAnswer(String text, int start, int end, float logit) {
this(text, new Pos(start, end, logit));
}
// 位置
public static class Pos implements Comparable<Pos> {
public int start;
public int end;
public float logit;
// コンストラクタ
public Pos(int start, int end, float logit) {
this.start = start;
this.end = end;
this.logit = logit;
}
// 比較
@Override
public int compareTo(Pos other) {
return Float.compare(other.logit, this.logit);
}
}
}9. コンテンツと質問を特徴に変換
コンテンツと質問を特徴に変換するクラスを作成します。
(TensorFlow Liteの公式サンプルと同じ)
◎ FeatureConverter.java
package net.npaka.bertex;
import net.npaka.bertex.tokenization.FullTokenizer;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
// 文字列をBERTモデルに与える特徴に変換
public final class FeatureConverter {
private final FullTokenizer tokenizer;
private final int maxQueryLen;
private final int maxSeqLen;
// コンストラクタ
public FeatureConverter(
Map<String, Integer> inputDic, boolean doLowerCase, int maxQueryLen, int maxSeqLen) {
this.tokenizer = new FullTokenizer(inputDic, doLowerCase);
this.maxQueryLen = maxQueryLen;
this.maxSeqLen = maxSeqLen;
}
// コンバート
public Feature convert(String query, String context) {
List<String> queryTokens = tokenizer.tokenize(query);
if (queryTokens.size() > maxQueryLen) {
queryTokens = queryTokens.subList(0, maxQueryLen);
}
List<String> origTokens = Arrays.asList(context.trim().split("\\s+"));
List<Integer> tokenToOrigIndex = new ArrayList<>();
List<String> allDocTokens = new ArrayList<>();
for (int i = 0; i < origTokens.size(); i++) {
String token = origTokens.get(i);
List<String> subTokens = tokenizer.tokenize(token);
for (String subToken : subTokens) {
tokenToOrigIndex.add(i);
allDocTokens.add(subToken);
}
}
// -3は、[CLS]、[SEP]、[SEP]を表す
int maxContextLen = maxSeqLen - queryTokens.size() - 3;
if (allDocTokens.size() > maxContextLen) {
allDocTokens = allDocTokens.subList(0, maxContextLen);
}
List<String> tokens = new ArrayList<>();
List<Integer> segmentIds = new ArrayList<>();
// トークンインデックスを元のインデックスにマップ(feature.origTokens内)
Map<Integer, Integer> tokenToOrigMap = new HashMap<>();
// 特徴の生成の開始
tokens.add("[CLS]");
segmentIds.add(0);
// クエリ入力用
for (String queryToken : queryTokens) {
tokens.add(queryToken);
segmentIds.add(0);
}
// セパレータ入力用
tokens.add("[SEP]");
segmentIds.add(0);
// テキスト入力用
for (int i = 0; i < allDocTokens.size(); i++) {
String docToken = allDocTokens.get(i);
tokens.add(docToken);
segmentIds.add(1);
tokenToOrigMap.put(tokens.size(), tokenToOrigIndex.get(i));
}
// 終了マーク用
tokens.add("[SEP]");
segmentIds.add(1);
List<Integer> inputIds = tokenizer.convertTokensToIds(tokens);
List<Integer> inputMask = new ArrayList<>(Collections.nCopies(inputIds.size(), 1));
while (inputIds.size() < maxSeqLen) {
inputIds.add(0);
inputMask.add(0);
segmentIds.add(0);
}
return new Feature(inputIds, inputMask, segmentIds, origTokens, tokenToOrigMap);
}
}◎ Feature.java
package net.npaka.bertex;
import java.util.List;
import java.util.Map;
import com.google.common.primitives.Ints;
// BERTモデルに与えられる特徴
public class Feature {
public final int[] inputIds;
public final int[] inputMask;
public final int[] segmentIds;
public final List<String> origTokens;
public final Map<Integer, Integer> tokenToOrigMap;
// コンストラクタ
public Feature(
List<Integer> inputIds,
List<Integer> inputMask,
List<Integer> segmentIds,
List<String> origTokens,
Map<Integer, Integer> tokenToOrigMap) {
this.inputIds = Ints.toArray(inputIds);
this.inputMask = Ints.toArray(inputMask);
this.segmentIds = Ints.toArray(segmentIds);
this.origTokens = origTokens;
this.tokenToOrigMap = tokenToOrigMap;
}
}
10. トークン化
テキストをトークン化するクラスを作成します。
(TensorFlow Liteの公式サンプルと同じ)
◎ FullTokenizer.java
package net.npaka.bertex.tokenization;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
// トークン化
public final class FullTokenizer {
private final BasicTokenizer basicTokenizer;
private final WordpieceTokenizer wordpieceTokenizer;
private final Map<String, Integer> dic;
// コンストラクタ
public FullTokenizer(Map<String, Integer> inputDic, boolean doLowerCase) {
dic = inputDic;
basicTokenizer = new BasicTokenizer(doLowerCase);
wordpieceTokenizer = new WordpieceTokenizer(inputDic);
}
// トークン化
public List<String> tokenize(String text) {
List<String> splitTokens = new ArrayList<>();
for (String token : basicTokenizer.tokenize(text)) {
splitTokens.addAll(wordpieceTokenizer.tokenize(token));
}
return splitTokens;
}
// トークンをIDに変換
public List<Integer> convertTokensToIds(List<String> tokens) {
List<Integer> outputIds = new ArrayList<>();
for (String token : tokens) {
outputIds.add(dic.get(token));
}
return outputIds;
}
}◎ BasicTokenizer.java
package net.npaka.bertex.tokenization;
import com.google.common.base.Ascii;
import com.google.common.collect.Iterables;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
// BasicTokenizer (句読点の分割, 小文字の大文字化など)
public final class BasicTokenizer {
private final boolean doLowerCase;
// コンストラクタ
public BasicTokenizer(boolean doLowerCase) {
this.doLowerCase = doLowerCase;
}
// トークン化
public List<String> tokenize(String text) {
String cleanedText = cleanText(text);
List<String> origTokens = whitespaceTokenize(cleanedText);
StringBuilder stringBuilder = new StringBuilder();
for (String token : origTokens) {
if (doLowerCase) {
token = Ascii.toLowerCase(token);
}
List<String> list = runSplitOnPunc(token);
for (String subToken : list) {
stringBuilder.append(subToken).append(" ");
}
}
return whitespaceTokenize(stringBuilder.toString());
}
// 無効な文字の削除と空白のクリーンアップ
static String cleanText(String text) {
if (text == null) {
throw new NullPointerException("The input String is null.");
}
StringBuilder stringBuilder = new StringBuilder("");
for (int index = 0; index < text.length(); index++) {
char ch = text.charAt(index);
if (CharChecker.isInvalid(ch) || CharChecker.isControl(ch)) {
continue;
}
if (CharChecker.isWhitespace(ch)) {
stringBuilder.append(" ");
} else {
stringBuilder.append(ch);
}
}
return stringBuilder.toString();
}
// 空白の分割
static List<String> whitespaceTokenize(String text) {
if (text == null) {
throw new NullPointerException("The input String is null.");
}
return Arrays.asList(text.split(" "));
}
// 句点の分割
static List<String> runSplitOnPunc(String text) {
if (text == null) {
throw new NullPointerException("The input String is null.");
}
List<String> tokens = new ArrayList<>();
boolean startNewWord = true;
for (int i = 0; i < text.length(); i++) {
char ch = text.charAt(i);
if (CharChecker.isPunctuation(ch)) {
tokens.add(String.valueOf(ch));
startNewWord = true;
} else {
if (startNewWord) {
tokens.add("");
startNewWord = false;
}
tokens.set(tokens.size() - 1, Iterables.getLast(tokens) + ch);
}
}
return tokens;
}
}◎ WordpieceTokenizer.java
p
ackage net.npaka.bertex.tokenization;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
// テキストを単語の断片に分割する単語の断片のトークン化
public final class WordpieceTokenizer {
private final Map<String, Integer> dic;
private static final String UNKNOWN_TOKEN = "[UNK]"; // For unknown words.
private static final int MAX_INPUTCHARS_PER_WORD = 200;
// コンストラクタ
public WordpieceTokenizer(Map<String, Integer> vocab) {
dic = vocab;
}
// テキストをトークン化して単語に分割
public List<String> tokenize(String text) {
if (text == null) {
throw new NullPointerException("The input String is null.");
}
List<String> outputTokens = new ArrayList<>();
for (String token : BasicTokenizer.whitespaceTokenize(text)) {
if (token.length() > MAX_INPUTCHARS_PER_WORD) {
outputTokens.add(UNKNOWN_TOKEN);
continue;
}
boolean isBad = false; // 単語を既知のサブワードにトークン化できないかマーク
int start = 0;
List<String> subTokens = new ArrayList<>();
while (start < token.length()) {
String curSubStr = "";
int end = token.length(); // 長い部分文字列が最初に一致
while (start < end) {
String subStr =
(start == 0) ? token.substring(start, end) : "##" + token.substring(start, end);
if (dic.containsKey(subStr)) {
curSubStr = subStr;
break;
}
end--;
}
// 単語に既知のサブワードが含まれていない
if ("".equals(curSubStr)) {
isBad = true;
break;
}
// curSubStrは、見つけることができる最も長いサブワード
subTokens.add(curSubStr);
// 常駐文字列のトークン化
start = end;
}
if (isBad) {
outputTokens.add(UNKNOWN_TOKEN);
} else {
outputTokens.addAll(subTokens);
}
}
return outputTokens;
}
}
◎ CharChecker.java
package net.npaka.bertex.tokenization;
// 文字が空白/コントロール/句読点であるかどうかを確認
final class CharChecker {
// 空または未知の文字かどうか
public static boolean isInvalid(char ch) {
return (ch == 0 || ch == 0xfffd);
}
// 制御文字かどうか(空白を覗く)
public static boolean isControl(char ch) {
if (Character.isWhitespace(ch)) {
return false;
}
int type = Character.getType(ch);
return (type == Character.CONTROL || type == Character.FORMAT);
}
// 空白かどうか
public static boolean isWhitespace(char ch) {
if (Character.isWhitespace(ch)) {
return true;
}
int type = Character.getType(ch);
return (type == Character.SPACE_SEPARATOR
|| type == Character.LINE_SEPARATOR
|| type == Character.PARAGRAPH_SEPARATOR);
}
// 句読点かどうか
public static boolean isPunctuation(char ch) {
int type = Character.getType(ch);
return (type == Character.CONNECTOR_PUNCTUATION
|| type == Character.DASH_PUNCTUATION
|| type == Character.START_PUNCTUATION
|| type == Character.END_PUNCTUATION
|| type == Character.INITIAL_QUOTE_PUNCTUATION
|| type == Character.FINAL_QUOTE_PUNCTUATION
|| type == Character.OTHER_PUNCTUATION);
}
private CharChecker() {}
}11. 関連
この記事が気に入ったらサポートをしてみませんか?