Google Colab で はじめる Stable Diffusion v1.4

「Google Colab」で「Stable Diffusion」を試してみました。
・Stable Diffusion v1.4
・diffusers 0.3.0
【最新版の情報は以下で紹介】
1. Stable Diffusion
「Stable Diffusion」は、テキストから画像を生成する、高性能な画像生成AIです。
2. ライセンスの確認
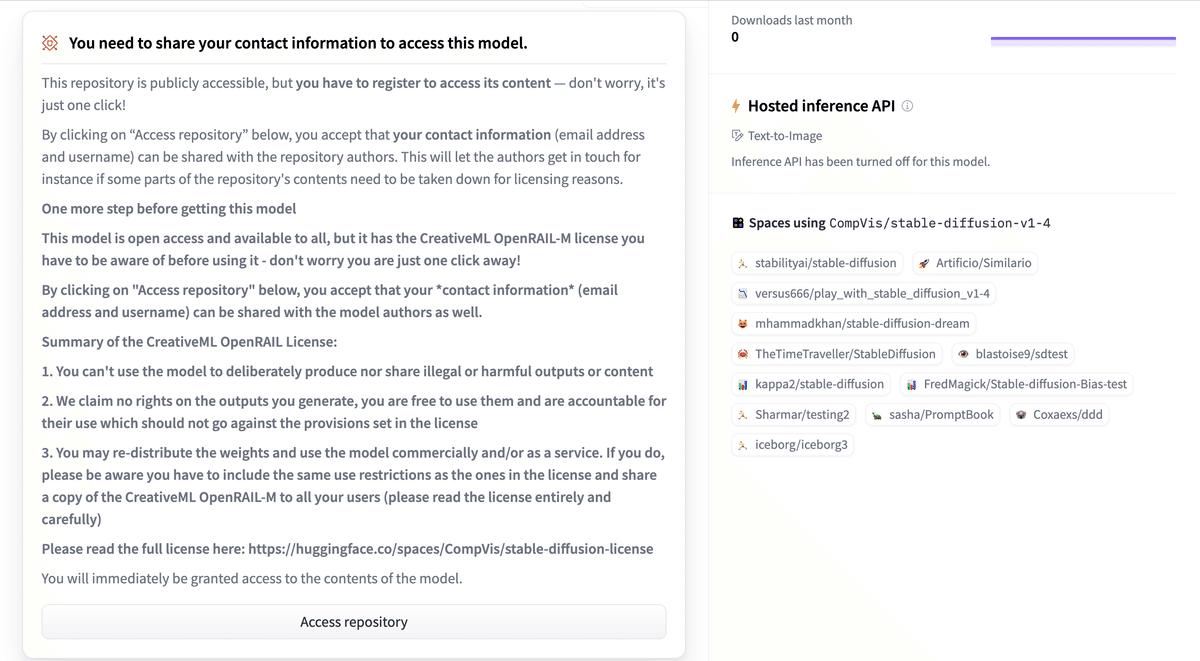
以下のモデルカードにアクセスして、ライセンスを確認し、「Access Repository」を押し、「Hugging Face」にログインして(アカウントがない場合は作成)、同意します。
3. HuggingFaceのトークンの取得
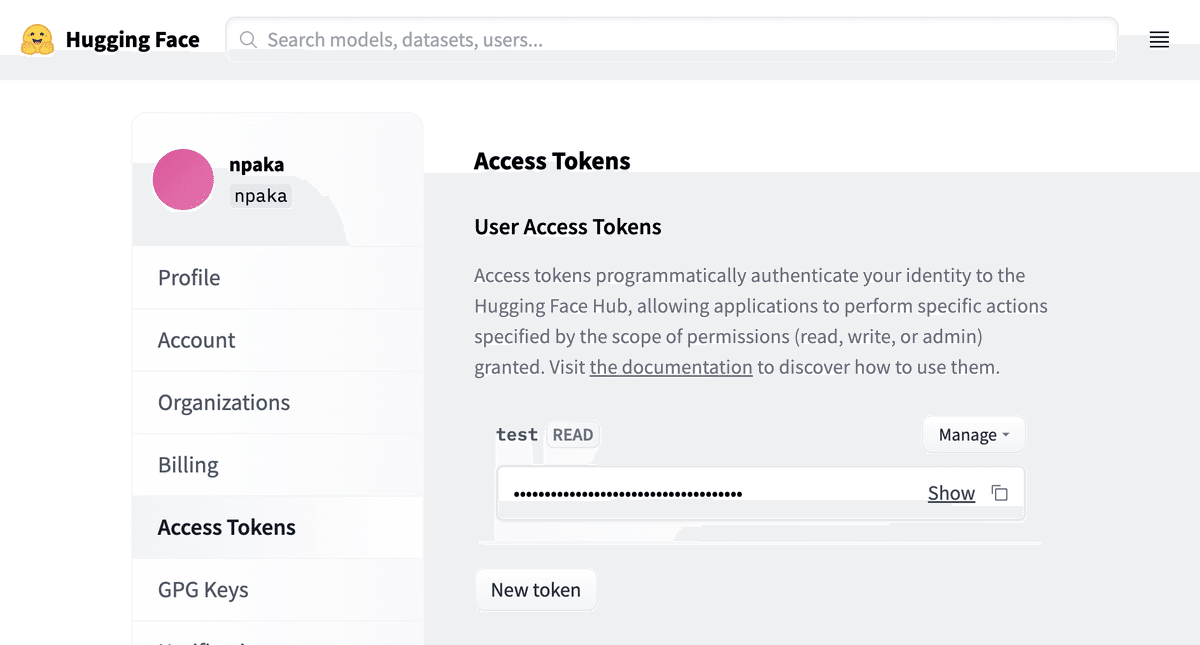
「HuggingFace」にログインして、「Settings → Access Token」でトークンを取得します。
4. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」に「GPU」を選択。
(2) 「Stable Diffusion」のインストール。
# パッケージのインストール
!pip install diffusers==0.3.0 transformers scipy ftfy(3) トークン変数の準備。
以下の「<HugginFace Hubのトークン>」の部分に、先程取得したHuggingFace Hubのトークンをコピー&ペーストします。
# トークン変数の準備
YOUR_TOKEN="<HugginFace Hubのトークン>"(4) 「Stable Diffusion」パイプラインの準備。
from diffusers import StableDiffusionPipeline
# StableDiffusionパイプラインの準備
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=YOUR_TOKEN
).to("cuda")(5) テキストを渡して画像を生成。
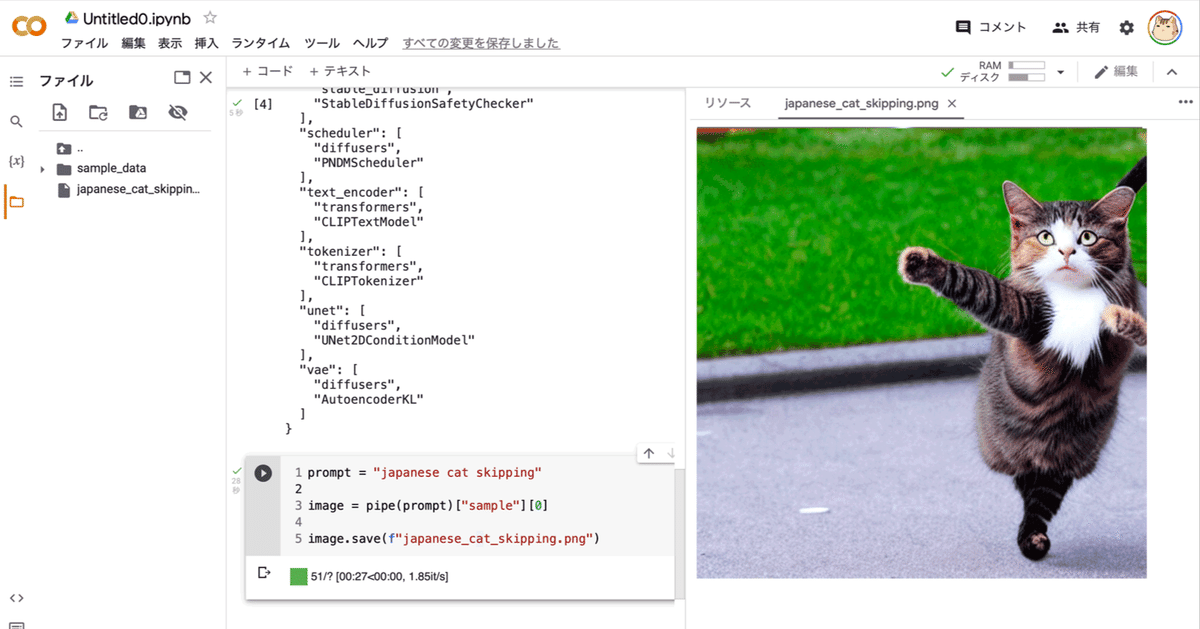
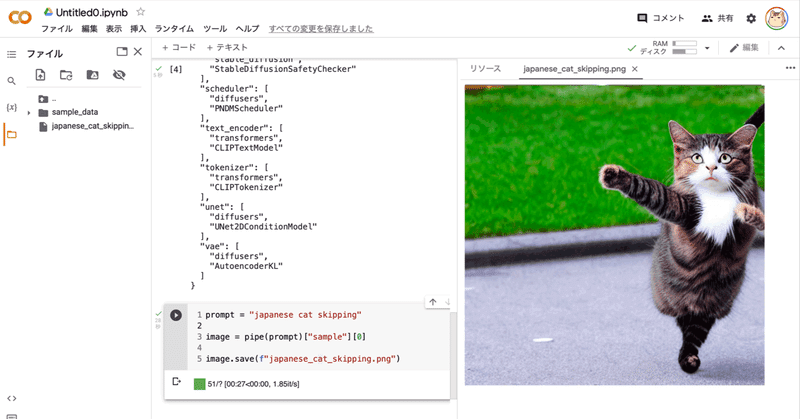
以下では、「japanese cat skipping」というテキストを渡してみました。
from torch import autocast
# テキストからの画像生成
prompt = "japanese cat skipping"
with autocast("cuda"):
images = pipe(prompt, guidance_scale=7.5).images
images[0].save("output.png")(6) 生成した画像の確認。
左端のフォルダアイコンでファイル一覧を表示し、output.pngをダブルクリックします。
【おまけ】 APIリファレンス
「StableDiffusionパイプライン」のpipeのパラメータは、次のとおりです。
・prompt (str or List[str]) : プロンプト
・height (int, optional, defaults to 512) : 生成する画像の高さ
・width (int, optional, defaults to 512) : 生成する画像の幅
・num_inference_steps (int, optional, defaults to 50) : ノイズ除去のステップ数
・guidance_scale (float, optional, defaults to 7.5) : プロンプトに従う度合い (7〜11程度)
・eta (float, optional, defaults to 0.0) : eta (eta=0.0 は決定論的サンプリング)
・generator (torch.Generator, optional) : 乱数ジェネレータ
・latents (torch.FloatTensor, optional) : 事前に生成されたノイジーな潜在変数
・output_type (str, optional, defaults to "pil") : 出力種別
・return_dict (bool, optional, defaults to True) : tupleの代わりにStableDiffusionPipelineOutputを返すかどうか
・戻り値 : tuple or StableDiffusionPipelineOutput
StableDiffusionPipelineOutputのプロパティは、次のとおりです。
・images (List[PIL.Image.Image] or np.ndarray) : 長さbatch_sizeのPIL画像のリスト または shape(batch_size,height,width,num_channels)のnumpy配列。
・nsfw_content_detected (List[bool]) : 生成画像がNSFW(not-safe-for-work)かどうかのリスト。